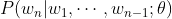프로그래밍을 배우기 시작한지 딱 1년 정도가 지났다. 42Ecole의 교육 과정이 한국에서도 진행된다고 했을 때, 지금이 기회라고 생각했다. 더 늦기 전에 내가 하고 싶은 것을 하기 위해 잘 다니고 있던 회사도 고민없이 그만두었다. 피신 시작 기간에 맞춰 퇴사했지만, 코로나로 인해 계속 지연되는 피신으로 인해 살짝 불안하기도 했었다. 다행히 5월에 피신을 시작할 수 있었고, 한 달 간 코딩, 밥, 잠 이외에는 아무것도 하지 않았다고 해도 과언이 아닐 정도로 몰두했다. 그 결과 본 과정에 합격했고, 여러 과제를 진행하면서 현재까지 무사히 잘 살아남아 있다.
피신을 시작하기 전엔 피신을 하면서 다 배울 수 있다고 해서 정말 아무런 준비도 하지 않고 피신을 시작했다. 첫 날에는 C언어가 아닌 난생 처음 만져보는 shell에 당황했다. 처음엔 이런 것도 배워야 하나? 라고 생각했는데, 지금 돌아보면 정말 좋은 출발이었던 것 같다. 오히려 지금은 GUI보다 CLI가 더 편할 때도 있다.
두 개의 shell 과제가 끝나고 C언어 과제를 시작했을 때 역시 당황하지 않을 수 없었다. "라이브러리를 쓸 수 없다고...? 그럼 어떻게 하라는 거지? 출력하는 다른 방법이 있나?" 한참을 고민하고 있을 때, 슬랙에 글 하나가 올라왔다. "Linux에서는 fd라는게 있는데 ~~~" 아직도 잊혀지지 않는 그 글의 내용은 바로 file descripter에 관한 내용이었다. 아마 이것이 내가 피신에서 배운 가장 첫 컴퓨터공학 지식이었던 것 같다. 그 이후로도 슬랙엔 피신을 진행하면서 많은 정보들이 공유되었고, 모르는 것은 직접 그 글을 올린 사람을 찾아가 물어보기도 했다.
피신에서 가장 좋았던 점은 지식과 정보의 나눔이었던 것 같다. 내가 모르는 건 가서 물어보고, 내가 아는 건 알려주는 그 과정이 너무 좋았다. 누군가 과제에 대해 고민하고 있으면 그 과제를 해결한 사람들이 너 나 할 것 없이 몰려가서 알려주곤 했다. 같은 과제를 하고 있는 사람이면 지금 어떤 방법으로 문제를 해결하고 있는지, 어떤 방법이 더 좋은지, 그런 얘기들을 나누며 과제를 하나씩 해결해나갔다. 뿐만 아니라, 내가 아직 진행하지 않은 과제에 대한 설명을 듣기 위해 일부러 평가를 진행한 경우도 자주 있었다.
개인적인 감상으로는 1기 2차 피시너들간의 교류가 유독 활발했던 것 같다. 처음에 피신 예정 인원은 150명 정도였는데, 코로나로 인하여 3개월 정도 연기되면서 약 90명 정도 밖에 남지 않았고, 따라서 거의 모든 피시너들을 알 수 있을 정도였다. 그래서 남은 소수 인원들 끼리 같이 잘해보자라는 마인드로 피신에 임해서 그랬던 것 같다.
올해 초 까지만 해도 본과정을 진행하면서 과연 내가 제대로 학습하고 있는 게 맞는지 의문이 들 때가 많았다. 그러나 최근에 기초를 공부하기 위해 운영체제 강의를 보면서 지금까지 학습했던 개념들이 나오는 것을 보고 잘 하고 있다는 확신이 들었다. 과제를 진행하면서 겪었던 각종 에러나 문제를 해결하는 과정들이 전부 컴퓨터공학 지식을 학습하는 과정이었던 것이다. 이 사실을 깨닫고 나서는 동료평가를 하는 기준이 조금 달라진 것 같다.
이전까지의 동료평가는 단순히 코드를 얼마나 깔끔하게 짰는지, 과제에서 요구하는 사항을 잘 만족하는지 그저 주어진 조건에만 맞게 평가를 진행했었다. 그러나 과제를 해결하는 과정이 컴퓨터공학 지식을 학습하는 과정이라는 것을 깨달은 이후에는 그 과제가 어떤 지식을 학습시키길 원하는가를 생각해보게 되었다. 예를 들어, 가장 첫 과제인 libft같은 경우는 그냥 단순히 라이브러리 함수를 똑같이 구현하는 과제가 아닌, 함수의 동작이 어떻게 이루어지고, 각각의 파라미터나 변수들이 어떤 것을 의미하는지 생각해보는 과제라고 생각한다.
테스터를 모두 통과해도 위 코드를 실행시키면 segfault가 발생한다. 평가를 받는 사람은 자신의 코드가 잘못된 줄 알고 당황한다. 그러나 코드는 잘못되지 않았다. 그렇다면 왜 segfault가 발생하는가? 답은 간단하다. 라이브러리의 strlen 함수도 마찬가지로 segfault가 발생한다. 그냥 strlen 함수가 그렇게 만들어져있기 때문이다. str이 null pointer일 때의 동작이 정의되지 않아서 에러가 발생하는 것이다. 지금까지 평가를 진행하면서 이 질문에 대한 답변을 제대로 들은 경우는 많지 않았다. 아마 직접 테스트 해보지 않고 단순히 테스터에만 의존하여 과제를 해결했기 때문이 아닐까 생각한다.
테스터가 나쁘다는 것은 아니다. 테스터가 많은 부분에서 이점을 주는 것은 사실이다. 30분이라는 제한된 시간 동안 모든 함수가 제대로 동작하는지 각종 테스트케이스를 넣어보면서 확인하긴 어렵기 때문에 테스터를 사용하는 것은 큰 도움이 된다. 다만 테스터는 어디까지나 보조수단일 뿐, 테스터를 너무 맹신하지 않는 것이 좋다고 생각한다. 물론 나도 과거에는 이러한 부분들을 반성하고 있고, 지금은 테스터 결과와는 상관 없이 그 사람이 얼마나 과제를 이해하고 코드를 짰는지를 더 중점적으로 보는 편이다.
이전에 코로나로 클러스터 출입이 불가하여 원격으로 ft_server 과제를 평가했던 적이 있었다. 평가를 받으시는 분은 VNC 화면을 공유하여 평가를 진행하는데, 자꾸 알트탭으로 창을 전환하며 어딘가에 적혀진 글을 보면서 명령어를 입력하는 것이 보였다. 그래서 피평가자분께 혹시라도 치팅으로 의심될 수 있으니 해당 글을 보지 말고 평가를 진행하기를 요청드렸더니 명령어를 모른다고 하셔서 더 이상 평가를 진행할 수 없었다. 과제 평가 기준에는 부합하지만 내가 생각했을 때 Docker 명령어도 모르고 이 과제를 했다는 것은 이 과제에서 요구하는 바를 만족시키지 못했다고 설명하고 Fail을 드렸다. 평가가 끝난 후 피평가자분께서 "안일한 생각으로 과제 평가표만 넘길 정도로 과제를 진행한 자신에 대해 부끄럽고 죄송하다"며 DM을 보내주셨고, 잘 마무리 되었다.
그러나 항상 이렇게 훈훈한 평가만 있는 것은 아니었다. 과제 관련 내용을 질문했을 때, 해당 내용은 평가 기준이랑 관계 없지 않냐며 짜증을 내는 사람 뿐만 아니라 평가 기준을 다 만족하는데 왜 Fail 이냐고 따지는 피평가자도 일부 있었다. 해당 내용이 왜 평가랑 관계가 있는지, 설명한 후에 Fail을 드리고 나면 평가 Feedback 점수를 0점으로 테러하는 사람도 있었다. 어쩌면 다른 사람에게 평가받았으면 통과했을지도 모르지만, 과제가 요구하는 바를 깨달아버린 이상 어쩔 수 없다. 운도 실력이라고 하지 않았는가!
회고를 쓰다 보니 잠시 딴 길로 샜는데, 어쨌든 요점은 평가를 통과하기 위한 과제 진행은 지양하는 것이 바람직하다고 생각한다. 1년쯤 하고 보니 42는 정말 내가 노력하는 만큼 알게되고, 내가 아는 만큼 더 많은 것을 보고 배울 수 있다는 것을 느꼈다. 지금도 평가를 진행하면서 이미 지나온 과제이지만 나도 간과하고 넘어간 부분이 있기 때문에 끝난 과제에서도 배우는 것이 많다.
김수보 멘토님의 글에서도 알 수 있다시피, 우리는 기술을 배우는 것이 아니다. 문제를 풀고, 협력하고, 스스로를 가르치고, 창의적이고, 비판적 사고를 가지기 위한 수용능력을 개발하는 것이다. 그러기 위해서 라이브러리를 쓰지 않고 과제를 해결하는 것이고, 과제를 해결하는 것이 곧 문제를 해결하는 능력을 기르는 것이라고 생각한다. 나는 이 사실을 깨닫는데 1년이라는 시간이 걸린 것 같다.
1년이라는 시간이 생각보다 빠른 것 같다. 1년동안 그토록 좋아하던 게임을 거의 안했는데, 코딩하고 공부하는 게 재밌었기 때문에 게임 생각이 안 나서 참 다행인 것 같다. 최근에는 AIFFEL이라는 인공지능 관련 교육을 듣느라 42과정을 잠시 미뤄두긴 했지만, 다시 42과정에 집중할 생각이다. 이제 사람도 많아진 만큼 나보다 과제를 앞선 사람들도 많아졌으므로 내가 부족한 부분을 잘 찝어줄 것이라 생각한다. 얼른 cpp 해야지.
텍스트 요약(Text Summarization)이란 위 그림과 같이 긴 길이의 문서(Document) 원문을 핵심 주제만으로 구성된 짧은 요약(Summary) 문장들로 변환하는 것을 말한다. 상대적으로 큰 텍스트인 뉴스 기사로 작은 텍스트인 뉴스 제목을 만들어내는 것이 텍스트 요약의 대표적인 예로 볼 수 있다.
이때 중요한 것은 요약 전후에 정보 손실 발생이 최소화되어야 한다는 점이다. 이것은 정보를 압축하는 과정과 같다. 비록 텍스트의 길이가 크게 줄어들었지만, 요약문은 문서 원문이 담고 있는 정보를 최대한 보존하고 있어야 한다. 이것은 원문의 길이가 길수록 만만치 않은 어려운 작업이 된다. 사람이 이 작업을 수행한다 하더라도 긴 문장을 정확하게 읽고 이해한 후, 그 의미를 손상하지 않는 짧은 다른 표현으로 원문을 번역해 내야 하는 것이다.
그렇다면 요약 문장을 만들어 내려면 어떤 방법을 사용하면 좋을까? 여기서 텍스트 요약은 크게 추출적 요약(Extractive Summarization)과 추상적 요약(Abstractive Summarization)의 두가지 접근으로 나누어볼 수 있다.
(1) 추출적 요약(Extractive Summarization)
첫번째 방식인 추출적 요약은 단어 그대로 원문에서 문장들을 추출해서 요약하는 방식이다. 가령, 10개의 문장으로 구성된 텍스트가 있다면, 그 중 핵심적인 문장 3개를 꺼내와서 3개의 문장으로 구성된 요약문을 만드는 식이다. 그런데 꺼내온 3개의 문장이 원문에서 중요한 문장일 수는 있어도, 3개의 문장의 연결이 자연스럽지 않을 수는 있다. 결과로 나온 문장들 간의 호응이 자연스럽지 않을 수 있다는 것이다. 딥 러닝보다는 주로 전통적인 머신 러닝 방식에 속하는 텍스트랭크(TextRank)와 같은 알고리즘을 사용한다.
(2) 추상적 요약(Abstractive Summarization)
두번째 방식인 추상적 요약은 추출적 요약보다 좀 더 흥미로운 접근을 사용한다. 원문으로부터 내용이 요약된 새로운 문장을 생성해내는 것이다. 여기서 새로운 문장이라는 것은 결과로 나온 문장이 원문에 원래 없던 문장일 수도 있다는 것을 의미한다. 자연어 처리 분야 중 자연어 생성(Natural Language Generation, NLG)의 영역인 셈이다. 반면, 추출적 요약은 원문을 구성하는 문장 중 어느 것이 요약문에 들어갈 핵심문장인지를 판별한다는 점에서 문장 분류(Text Classification) 문제로 볼 수 있을 것이다.
인공 신경망으로 텍스트 요약 훈련시키기
seq2seq 모델을 통해서 Abstractive summarization 방식의 텍스트 요약기를 만들어보자. seq2seq은 두 개의 RNN 아키텍처를 사용하여 입력 시퀀스로부터 출력 시퀀스를 생성해내는 자연어 생성 모델로 주로 뉴럴 기계번역에 사용되지만, 원문을 요약문으로 번역한다고 생각하면 충분히 사용 가능할 것이다.
seq2seq 개요
원문을 첫번째 RNN인 인코더로 입력하면, 인코더는 이를 하나의 고정된 벡터로 변환한다. 이 벡터를 문맥 정보를 가지고 있는 벡터라고 하여 컨텍스트 벡터(context vector)라고 한다. 두번째 RNN인 디코더는 이 컨텍스트 벡터를 전달받아 한 단어씩 생성해내서 요약 문장을 완성한다.
LSTM과 컨텍스트 벡터
LSTM이 바닐라 RNN과 다른 점은 다음 time step의 셀에 hidden state뿐만 아니라, cell state도 함께 전달한다는 점이다. 다시 말해, 인코더가 디코더에 전달하는 컨텍스트 벡터 또한 hidden state h와 cell state c 두 개의 값 모두 존재해야 한다는 뜻이다.
시작 토큰과 종료 토큰
[시작 토큰 SOS와 종료 토큰 EOS는 각각 start of a sequence와 end of a sequence를 나타낸다]
seq2seq 구조에서 디코더는 시작 토큰 SOS가 입력되면, 각 시점마다 단어를 생성하고 이 과정을 종료 토큰 EOS를 예측하는 순간까지 멈추지않는다. 다시 말해 훈련 데이터의 예측 대상 시퀀스의 앞, 뒤에는 시작 토큰과 종료 토큰을 넣어주는 전처리를 통해 어디서 멈춰야하는지 알려줄 필요가 있다.
어텐션 메커니즘을 통한 새로운 컨텍스트 벡터 사용하기
기존의 seq2seq는 인코더의 마지막 time step의 hidden state를 컨텍스트 벡터로 사용했다. 하지만 RNN 계열의 인공 신경망(바닐라 RNN, LSTM, GRU)의 한계로 인해 이 컨텍스트 정보에는 이미 입력 시퀀스의 많은 정보가 손실이 된 상태가 된다.
이와 달리, 어텐션 메커니즘(Attention Mechanism)은 인코더의 모든 step의 hidden state의 정보가 컨텍스트 벡터에 전부 반영되도록 하는 것이다. 하지만 인코더의 모든 hidden state가 동일한 비중으로 반영되는 것이 아니라, 디코더의 현재 time step의 예측에 인코더의 각 step이 얼마나 영향을 미치는지에 따른 가중합으로 계산되는 방식이다.
여기서 주의해야 할 것은, 컨텍스트 벡터를 구성하기 위한 인코더 hidden state의 가중치 값은 디코더의 현재 스텝이 어디냐에 따라 계속 달라진다는 점이다. 즉, 디코더의 현재 문장 생성 부위가 주어부인지 술어부인지 목적어인지 등에 따라 인코더가 입력 데이터를 해석한 컨텍스트 벡터가 다른 값이 된다. 이와 달리, 기본적인 seq2seq 모델에서 컨텍스트 벡터는 디코더의 현재 스텝 위치에 무관하게 한번 계산되면 고정값을 가진다.
인물사진 모드란, 피사체를 촬영할 때 배경이 흐려지는 효과를 넣어주는 것을 이야기 한다. 물론 DSLR의 아웃포커스 효과와는 다른 방식으로 구현한다.
핸드폰 카메라의 인물사진 모드는 듀얼 카메라를 이용해 아웃포커싱 기능을 흉내낸다.
DSLR에서는 사진을 촬영할 때 피사계 심도(depth of field, DOF)를 얕게 하여 초점이 맞은 피사체를 제외한 배경을 흐리게 만든다.
핸드폰 인물사진 모드는 화각이 다른 두 렌즈를 사용한다. 일반(광각) 렌즈에서는 배경을 촬영하고 망원 렌즈에서는 인물을 촬영한 뒤 배경을 흐리게 처리한 후 망원 렌즈의 인물과 적절하게 합성한다.
인물사진 모드에서 사용되는 용어
한국에서는 배경을 흐리게 하는 기술을 주로 '아웃포커싱'이라고 표현한다. 하지만 아웃포커싱은 한국에서만 사용하는 용어이고 정확한 영어 표현은 얕은 피사계 심도(shallow depth of field) 또는 셸로우 포커스(shallow focus) 라고 한다.
학습 목표
딥러닝을 이용하여 핸드폰 인물 사진 모드를 모방해본다.
셸로우 포커스 만들기
(1) 사진준비
하나의 카메라로 셸로우 포커스(shallow focus)를 만드는 방법은 다음과 같다.
이미지 세그멘테이션(Image segmentation) 기술을 이용하면 하나의 이미지에서 배경과 사람을 분리할 수 있다. 분리된 배경을 블러(blur)처리 후 사람 이미지와 다시 합하면 아웃포커싱 효과를 적용한 인물사진을 얻을 수 있다.
# 필요 모듈 import
import cv2
import numpy as np
import os
from glob import glob
from os.path import join
import tarfile
import urllib
from matplotlib import pyplot as plt
import tensorflow as tf
# 이미지 불러오기
import os
img_path = os.getenv('HOME')+'/aiffel/human_segmentation/images/2017.jpg' # 본인이 선택한 이미지의 경로에 맞게 바꿔 주세요.
img_orig = cv2.imread(img_path)
print (img_orig.shape)
(2) 세그멘테이션으로 사람 분리하기
배경에만 렌즈흐림 효과를 주기 위해서는 이미지에서 사람과 배경을 분리해야 한다. 흔히 포토샵으로 '누끼 따기'와 같은 작업을 이야기한다.
세그멘테이션(Segmentation)이란?
이미지에서 픽셀 단위로 관심 객체를 추출하는 방법을 이미지 세그멘테이션(image segmentation) 이라고 한다. 이미지 세그멘테이션은 모든 픽셀에 라벨(label)을 할당하고 같은 라벨은 "공통적인 특징"을 가진다고 가정한다. 이 때 공통 특징은 물리적 의미가 없을 수도 있다. 픽셀이 비슷하게 생겼다는 사실은 인식하지만, 우리가 아는 것처럼 실제 물체 단위로 인식하지 않을 수 있다. 물론 세그멘테이션에는 여러 가지 세부 태스크가 있으며, 태스크에 따라 다양한 기준으로 객체를 추출한다.
시멘틱 세그맨테이션(Semantic segmentation)이란?
세그멘테이션 중에서도 특히 우리가 인식하는 세계처럼 물리적 의미 단위로 인식하는 세그멘테이션을 시맨틱 세그멘테이션 이라고 한다. 쉽게 설명하면 이미지에서 픽셀을 사람, 자동차, 비행기 등의 물리적 단위로 분류(classification)하는 방법이라고 할 수 있다.
인스턴스 세그멘테이션(Instance segmentation)이란?
시맨틱 세그멘테이션은 '사람'이라는 추상적인 정보를 이미지에서 추출해내는 방법이다. 그래서 사람이 누구인지 관계없이 같은 라벨로 표현이 된다. 더 나아가서 인스턴스 세그멘테이션은 사람 개개인 별로 다른 라벨을 가지게 한다. 여러 사람이 한 이미지에 등장할 때 각 객체를 분할해서 인식하자는 것이 목표이다.
이미지 세그멘테이션의 간단한 알고리즘 : 워터쉐드 세그멘테이션(watershed segmentation)
이미지에서 영역을 분할하는 가장 간단한 방법은 물체의 '경계'를 나누는 것이다. 이미지는 그레이스케일(grayscale)로 변환하면 0~255의 값을 가지기 때문에 픽셀 값을 이용해서 각 위치의 높고 낮음을 구분할 수 있다. 따라서 낮은 부분부터 서서히 '물'을 채워 나간다고 생각할 때 각 영역에서 점점 물이 차오르다가 넘치는 시점을 경계선으로 만들면 물체를 서로 구분할 수 있게 된다.
(3) 시멘틱 세그멘테이션 다뤄보기
세그멘테이션 문제에는 FCN, SegNet, U-Net 등 많은 모델이 사용된다. 오늘은 그 중에서 DeepLab이라는 세그멘테이션 모델을 만들고 모델에 이미지를 입력할 것이다. DeepLab 알고리즘(DeepLab v3+)은 세그멘테이션 모델 중에서도 성능이 매우 좋아 최근까지도 많이 사용되고 있다.
# DeepLabModel Class 정의
class DeepLabModel(object):
INPUT_TENSOR_NAME = 'ImageTensor:0'
OUTPUT_TENSOR_NAME = 'SemanticPredictions:0'
INPUT_SIZE = 513
FROZEN_GRAPH_NAME = 'frozen_inference_graph'
# __init__()에서 모델 구조를 직접 구현하는 대신, tar file에서 읽어들인 그래프구조 graph_def를
# tf.compat.v1.import_graph_def를 통해 불러들여 활용하게 됩니다.
def __init__(self, tarball_path):
self.graph = tf.Graph()
graph_def = None
tar_file = tarfile.open(tarball_path)
for tar_info in tar_file.getmembers():
if self.FROZEN_GRAPH_NAME in os.path.basename(tar_info.name):
file_handle = tar_file.extractfile(tar_info)
graph_def = tf.compat.v1.GraphDef.FromString(file_handle.read())
break
tar_file.close()
with self.graph.as_default():
tf.compat.v1.import_graph_def(graph_def, name='')
self.sess = tf.compat.v1.Session(graph=self.graph)
# 이미지를 전처리하여 Tensorflow 입력으로 사용 가능한 shape의 Numpy Array로 변환합니다.
def preprocess(self, img_orig):
height, width = img_orig.shape[:2]
resize_ratio = 1.0 * self.INPUT_SIZE / max(width, height)
target_size = (int(resize_ratio * width), int(resize_ratio * height))
resized_image = cv2.resize(img_orig, target_size)
resized_rgb = cv2.cvtColor(resized_image, cv2.COLOR_BGR2RGB)
img_input = resized_rgb
return img_input
def run(self, image):
img_input = self.preprocess(image)
# Tensorflow V1에서는 model(input) 방식이 아니라 sess.run(feed_dict={input...}) 방식을 활용합니다.
batch_seg_map = self.sess.run(
self.OUTPUT_TENSOR_NAME,
feed_dict={self.INPUT_TENSOR_NAME: [img_input]})
seg_map = batch_seg_map[0]
return cv2.cvtColor(img_input, cv2.COLOR_RGB2BGR), seg_map
preprocess()는 전처리, run()은 실제로 세그멘테이셔는 하는 함수이다. input tensor를 만들기 위해 전처리를 하고, 적절한 크기로 resize하여 OpenCV의 BGR 채널은 RGB로 수정 후 run()함수의 input parameter로 사용된다.
# Model 다운로드
# define model and download & load pretrained weight
_DOWNLOAD_URL_PREFIX = 'http://download.tensorflow.org/models/'
model_dir = os.getenv('HOME')+'/aiffel/human_segmentation/models'
tf.io.gfile.makedirs(model_dir)
print ('temp directory:', model_dir)
download_path = os.path.join(model_dir, 'deeplab_model.tar.gz')
if not os.path.exists(download_path):
urllib.request.urlretrieve(_DOWNLOAD_URL_PREFIX + 'deeplabv3_mnv2_pascal_train_aug_2018_01_29.tar.gz',
download_path)
MODEL = DeepLabModel(download_path)
print('model loaded successfully!')
위 코드는 구글이 제공하는 pretrained weight이다. 이 모델은 PASCAL VOC 2012라는 대형 데이터셋으로 학습된 v3 버전이다.
# 이미지 resize
img_resized, seg_map = MODEL.run(img_orig)
print (img_orig.shape, img_resized.shape, seg_map.max()) # cv2는 채널을 HWC 순서로 표시
# seg_map.max() 의 의미는 물체로 인식된 라벨 중 가장 큰 값을 뜻하며, label의 수와 일치
# PASCAL VOC로 학습된 label
LABEL_NAMES = [
'background', 'aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus',
'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike',
'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tv'
]
len(LABEL_NAMES)
# 사람을 찾아 시각화
img_show = img_resized.copy()
seg_map = np.where(seg_map == 15, 15, 0) # 예측 중 사람만 추출 person의 label은 15
img_mask = seg_map * (255/seg_map.max()) # 255 normalization
img_mask = img_mask.astype(np.uint8)
color_mask = cv2.applyColorMap(img_mask, cv2.COLORMAP_JET)
img_show = cv2.addWeighted(img_show, 0.6, color_mask, 0.35, 0.0)
plt.imshow(cv2.cvtColor(img_show, cv2.COLOR_BGR2RGB))
plt.show()
(4) 세그멘테이션 결과를 원래 크기로 복원하기
DeepLab 모델을 사용하기 위해 이미지 크기를 작게 resize했기 때문에 원래 크기로 복원해야 한다.
cv2.resize() 함수를 이용하여 원래 크기로 복원하였다. 크기를 키울 때 보간(interpolation)을 고려해야 하는데, cv2.INTER_NEAREST를 이용하면 깔끔하게 처리할 수 있지만 더 정확하게 확대하기 위해 cv2.INTER_LINEAR를 사용하였다.
결과적으로 img_mask_up 은 경계가 블러된 픽셀값 0~255의 이미지를 얻는다. 확실한 경계를 다시 정하기 위해 중간값인 128을 기준으로 임계값(threshold)을 설정하여 128 이하의 값은 0으로 128 이상의 값은 255로 만들었다.
(5) 배경 흐리게 하기
# 배경 이미지 얻기
img_mask_color = cv2.cvtColor(img_mask_up, cv2.COLOR_GRAY2BGR)
img_bg_mask = cv2.bitwise_not(img_mask_color)
img_bg = cv2.bitwise_and(img_orig, img_bg_mask)
plt.imshow(img_bg)
plt.show()
bitwise_not : not 연산하여 이미지 반전
bitwise_and : 배경과 and 연산하여 배경만 있는 이미지를 얻을 수 있다.
# 이미지 블러처리
img_bg_blur = cv2.blur(img_bg, (13,13))
plt.imshow(cv2.cvtColor(img_bg_blur, cv2.COLOR_BGR2RGB))
plt.show()
(6) 흐린 배경과 원본 영상 합성
# 255인 부분만 원본을 가져온 후 나머지는 blur 이미지
img_concat = np.where(img_mask_color==255, img_orig, img_bg_blur)
plt.imshow(cv2.cvtColor(img_concat, cv2.COLOR_BGR2RGB))
plt.show()
회고록
평소에 사진을 취미로 하고 있어서 이번 과제를 이해하는 것이 어렵지 않았다.
이미지 세그멘테이션에 대해 단어만 알고 정확히 어떤 역할을 하는 기술인지 잘 몰랐는데 이번 학습을 통해 확실하게 알 수 있었다.
이미지를 블러처리 하는 과정에서 인물과 배경의 경계 부분도 같이 블러처리 되어버리기 때문에 나중에 이미지를 병합하는 과정에서 배경에 있는 인물 영역이 실제 사진의 인물 영역보다 넓어져 병합 후의 이미지에서 경계 주위로 그림자(?)가 지는 것 같은 현상을 볼 수 있었다.
앞으로 자율주행이나 인공지능을 이용해서 자동화 할 수 있는 부분에는 어디든 사용될 수 있을 법한 그런 기술인 것 같다.
이 기술을 이용해서 병, 캔, 플라스틱 과 같은 재활용 쓰레기를 구분할 수 있다고 하면, 환경 분야에서도 쓸 수 있지 않을까...? 그 정도로 구분하는 것은 어려울 것 같긴 하다.
jupyter notebook에서 생성된 이미지를 깔끔하게 보이도록 정리하려고 html을 이용하여 사진을 정렬했었는데 github에선 html style이 무시된다는 것을 알게되어 3시간 정도를 이미지 정렬하는 데 썼다... 결국 안 된다는 것을 깨닫고 pyplot을 이용해서 비교하였다.
문장은 각 단어들이 문법이라는 규칙을 따라 배열되어 있기 때문에 시퀀스 데이터로 볼 수 있다.
문법은 복잡하기 때문에 문장 데이터를 이용한 인공지능을 만들 때에는 통계에 기반한 방법을 이용한다.
순환신경망(RNN)
나는 공부를 [ ]에서 빈 칸에는 한다 라는 단어가 들어갈 것이다. 문장에는 앞 뒤 문맥에 따라 통계적으로 많이 사용되는 단어들이 있다. 인공지능이 글을 이해하는 방식도 위와 같다. 문법적인 원리를 통해서가 아닌 수많은 글을 읽게하여 통계적으로 다음 단어는 어떤 것이 올지 예측하는 것이다. 이 방식에 가장 적합한 인공지능 모델 중 하나가 순환신경망(RNN)이다.
시작은 <start>라는 특수한 토큰을 앞에 추가하여 시작을 나타내고, <end>라는 토큰을 통해 문장의 끝을 나타낸다.
언어 모델
나는, 공부를, 한다 를 순차적으로 생성할 때, 우리는 공부를 다음이 한다인 것을 쉽게 할 수 있다. 나는 다음이 한다인 것은 어딘가 어색하게 느껴진다. 실제로 인공지능이 동작하는 방식도 순전히 운이다.
이것을 좀 더 확률적으로 표현해 보면 나는 공부를 다음에 한다가 나올 확률을 $p(한다|나는, 공부를)$라고 하면, $p(공부를|나는)$보다는 높게 나올 것이다. $p(한다|나는, 공부를, 열심히)$의 확률값은 더 높아질 것이다.
문장에서 단어 뒤에 다음 단어가 나올 확률이 높다는 것은 그 단어가 자연스럽다는 뜻이 된다. 확률이 낮다고 해서 자연스럽지 않은 것은 아니다. 단어 뒤에 올 수 있는 자연스러운 단어의 경우의 수가 워낙 많아서 불확실성이 높을 뿐이다.
n-1개의 단어 시퀀스 $w_1,⋯,w_{n-1}$이 주어졌을 때, n번째 단어 $w_n$으로 무엇이 올지 예측하는 확률 모델을 언어 모델(Language Model)이라고 부른다. 파라미터 $\theta$로 모델링 하는 언어 모델을 다음과 같이 표현할 수 있다.
언어 모델은 어떻게 학습시킬 수 있을까? 언어 모델의 학습 데이터는 어떻게 나누어야 할까? 답은 간단하다. 어떠한 텍스트도 언어 모델의 학습 데이터가 될 수 있다. x_train이 n-1번째까지의 단어 시퀀스고, y_train이 n번째 단어가 되는 데이터셋이면 얼마든지 학습 데이터로 사용할 수 있다. 이렇게 잘 훈련된 언어 모델은 훌륭한 문장 생성기가 된다.
인공지능 만들기
(1) 데이터 준비
import re
import numpy as np
import tensorflow as tf
import os
# 파일 열기
file_path = os.getenv('HOME') + '/aiffel/lyricist/data/shakespeare.txt'
with open(file_path, "r") as f:
raw_corpus = f.read().splitlines() # 텍스트를 라인 단위로 끊어서 list 형태로 읽어온다.
print(raw_corpus[:9])
데이터에서 우리가 원하는 것은 문장(대사)뿐이므로, 화자 이름이나 공백은 제거해주어야 한다.
# 문장 indexing
for idx, sentence in enumerate(raw_corpus):
if len(sentence) == 0: continue # 길이가 0인 문장은 스킵
if sentence[-1] == ":": continue # :로 끝나는 문장은 스킵
if idx > 9: break
print(sentence)
이제 문장을 단어로 나누어야 한다. 문장을 형태소로 나누는 것을 토큰화(Tokenize)라고 한다. 가장 간단한 방법은 띄어쓰기를 기준으로 나누는 것이다. 그러나 문장부호, 대소문자, 특수문자 등이 있기 때문에 따로 전처리를 먼저 해주어야 한다.
# 문장 전처리 함수
def preprocess_sentence(sentence):
sentence = sentence.lower().strip() # 소문자로 바꾸고 양쪽 공백을 삭제
# 정규식을 이용하여 문장 처리
sentence = re.sub(r"([?.!,¿])", r" \1 ", sentence) # 패턴의 특수문자를 만나면 특수문자 양쪽에 공백을 추가
sentence = re.sub(r'[" "]+', " ", sentence) # 공백 패턴을 만나면 스페이스 1개로 치환
sentence = re.sub(r"[^a-zA-Z?.!,¿]+", " ", sentence) # a-zA-Z?.!,¿ 패턴을 제외한 모든 문자(공백문자까지도)를 스페이스 1개로 치환
sentence = sentence.strip()
sentence = '<start> ' + sentence + ' <end>' # 문장 앞뒤로 <start>와 <end>를 단어처럼 붙여 줍니다
return sentence
print(preprocess_sentence("Hi, This @_is ;;;sample sentence?"))
우리가 구축해야할 데이터셋은 입력이 되는 소스 문장(Source Sentence)과 출력이 되는 타겟 문장(Target Sentence)으로 나누어야 한다.
언어 모델의 입력 문장 : <start> 나는 공부를 한다
언어 모델의 출력 문장 : 나는 공부를 한다 <end>
위에서 만든 전처리 함수에서 를 제거하면 소스 문장, 를 제거하면 타겟 문장이 된다.
corpus = []
# 모든 문장에 전처리 함수 적용
for sentence in raw_corpus:
if len(sentence) == 0: continue
if sentence[-1] == ":": continue
corpus.append(preprocess_sentence(sentence))
corpus[:10]
이제 문장을 컴퓨터가 이해할 수 있는 숫자로 변경해주어야 한다. 텐서플로우는 자연어 처리를 위한 여러 가지 모듈을 제공하며, tf.keras.preprocessing.text.Tokenizer 패키지는 데이터를 토큰화하고, dictionary를 만들어주며, 데이터를 숫자로 변환까지 한 번에 해준다. 이 과정을 벡터화(Vectorize)라고 하며, 변환된 숫자 데이터를 텐서(tensor)라고 한다.
def tokenize(corpus):
# 텐서플로우에서 제공하는 Tokenizer 패키지를 생성
tokenizer = tf.keras.preprocessing.text.Tokenizer(
num_words=7000, # 전체 단어의 개수
filters=' ', # 전처리 로직
oov_token="<unk>" # out-of-vocabulary, 사전에 없는 단어
)
tokenizer.fit_on_texts(corpus) # 우리가 구축한 corpus로부터 Tokenizer가 사전을 자동구축
# tokenizer를 활용하여 모델에 입력할 데이터셋을 구축
tensor = tokenizer.texts_to_sequences(corpus) # tokenizer는 구축한 사전으로부터 corpus를 해석해 Tensor로 변환
# 입력 데이터의 시퀀스 길이를 일정하게 맞추기 위한 padding 메소드
# maxlen의 디폴트값은 None. corpus의 가장 긴 문장을 기준으로 시퀀스 길이가 맞춰진다
tensor = tf.keras.preprocessing.sequence.pad_sequences(tensor, padding='post')
print(tensor,tokenizer)
return tensor, tokenizer
tensor, tokenizer = tokenize(corpus)
print(tensor[:3, :10]) # 생성된 텐서 데이터 확인
# 단어 사전의 index
for idx in tokenizer.index_word:
print(idx, ":", tokenizer.index_word[idx])
if idx >= 10: break
src_input = tensor[:, :-1] # tensor에서 마지막 토큰을 잘라내서 소스 문장을 생성. 마지막 토큰은 <end>가 아니라 <pad>일 가능성이 높다.
tgt_input = tensor[:, 1:] # tensor에서 <start>를 잘라내서 타겟 문장을 생성.
print(src_input[0])
print(tgt_input[0])
# 데이터셋 구축
BUFFER_SIZE = len(src_input)
BATCH_SIZE = 256
steps_per_epoch = len(src_input) // BATCH_SIZE
VOCAB_SIZE = tokenizer.num_words + 1 # 0:<pad>를 포함하여 dictionary 갯수 + 1
dataset = tf.data.Dataset.from_tensor_slices((src_input, tgt_input)).shuffle(BUFFER_SIZE)
dataset = dataset.batch(BATCH_SIZE, drop_remainder=True)
dataset
데이터셋 생성 과정 요약
정규표현식을 이용한 corpus 생성
tf.keras.preprocessing.text.Tokenizer를 이용해 corpus를 텐서로 변환
tf.data.Dataset.from_tensor_slices()를 이용해 corpus 텐서를 tf.data.Dataset객체로 변환
(2) 모델 학습하기
이번에 만들 모델의 구조는 다음과 같다.
# 모델 생성
class TextGenerator(tf.keras.Model):
def __init__(self, vocab_size, embedding_size, hidden_size):
super(TextGenerator, self).__init__()
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_size)
self.rnn_1 = tf.keras.layers.LSTM(hidden_size, return_sequences=True)
self.rnn_2 = tf.keras.layers.LSTM(hidden_size, return_sequences=True)
self.linear = tf.keras.layers.Dense(vocab_size)
def call(self, x):
out = self.embedding(x)
out = self.rnn_1(out)
out = self.rnn_2(out)
out = self.linear(out)
return out
embedding_size = 256 # 워드 벡터의 차원 수
hidden_size = 1024 # LSTM Layer의 hidden 차원 수
model = TextGenerator(tokenizer.num_words + 1, embedding_size , hidden_size)
# 모델의 데이터 확인
for src_sample, tgt_sample in dataset.take(1): break
model(src_sample)
# 모델의 최종 출력 shape는 (256, 20, 7001)
# 256은 batch_size, 20은 squence_length, 7001은 단어의 갯수(Dense Layer 출력 차원 수)
model.summary() # sequence_length를 모르기 때문에 Output shape를 정확하게 모른다.
# 모델 학습
optimizer = tf.keras.optimizers.Adam()
loss = tf.keras.losses.SparseCategoricalCrossentropy(
from_logits=True,
reduction='none'
)
model.compile(loss=loss, optimizer=optimizer)
model.fit(dataset, epochs=30)
위의 코드에서 embbeding_size 는 워드 벡터의 차원 수를 나타내는 parameter로, 단어가 추상적으로 표현되는 크기를 말한다. 예를 들어 크기가 2라면 다음과 같이 표현할 수 있다.
차갑다: [0.0, 1.0]
뜨겁다: [1.0, 0.0]
미지근하다: [0.5, 0.5]
(3) 모델 평가하기
인공지능을 통한 작문은 수치적으로 평가할 수 없기 때문에 사람이 직접 평가를 해야 한다.
# 문장 생성 함수
def generate_text(model, tokenizer, init_sentence="<start>", max_len=20):
# 테스트를 위해서 입력받은 init_sentence도 텐서로 변환
test_input = tokenizer.texts_to_sequences([init_sentence])
test_tensor = tf.convert_to_tensor(test_input, dtype=tf.int64)
end_token = tokenizer.word_index["<end>"]
# 단어를 하나씩 생성
while True:
predict = model(test_tensor) # 입력받은 문장
predict_word = tf.argmax(tf.nn.softmax(predict, axis=-1), axis=-1)[:, -1] # 예측한 단어가 새로 생성된 단어
# 우리 모델이 새롭게 예측한 단어를 입력 문장의 뒤에 붙이기
test_tensor = tf.concat([test_tensor,
tf.expand_dims(predict_word, axis=0)], axis=-1)
# 우리 모델이 <end>를 예측했거나, max_len에 도달하지 않았다면 while 루프를 또 돌면서 다음 단어를 예측
if predict_word.numpy()[0] == end_token: break
if test_tensor.shape[1] >= max_len: break
generated = ""
# 생성된 tensor 안에 있는 word index를 tokenizer.index_word 사전을 통해 실제 단어로 하나씩 변환
for word_index in test_tensor[0].numpy():
generated += tokenizer.index_word[word_index] + " "
return generated # 최종 생성된 자연어 문장
# 생성 함수 실행
generate_text(model, tokenizer, init_sentence="<start> i love")
회고록
range(n)도 reverse() 함수가 먹힌다는 걸 오늘 알았다...
예시에 주어진 train data 갯수는 124960인걸 보면 총 데이터는 156200개인 것 같은데 아무리 전처리 단계에서 조건에 맞게 처리해도 168000개 정도가 나온다. 아무튼 일단 돌려본다.
문장의 길이가 최대 15라는 이야기는 <start>, <end>를 포함하여 15가 되어야 하는 것 같아서 tokenize했을 때 문장의 길이가 13 이하인 것만 corpus로 만들었다.
학습 회차 별 생성된 문장 input : <start> i love
1회차 '<start> i love you , i love you <end> '
2회차 '<start> i love you , i m not gonna crack <end> '
3회차'<start> i love you to be a shot , i m not a man <end> '
4회차 '<start> i love you , i m not stunning , i m a fool <end> '
batch_size를 각각 256, 512, 1024로 늘려서 진행했는데, 1epoch당 걸리는 시간이 74s, 62s, 59s 정도로 batch_size 배수 만큼의 차이는 없었다. batch_size가 배로 늘어나면 걸리느 시간도 당연히 반으로 줄어들 것이라 생각했는데 오산이었다.
1회차는 tokenize 했을 때 length가 15 이하인 것을 train_data로 사용하였다.
2, 3, 4회차는 tokenize 했을 때 length가 13 이하인 것을 train_data로 사용하였다.
3회차는 2회차랑 동일한 데이터에 padding 을 post에서 pre로 변경하였다. RNN에서는 뒤에 padding을 넣는 것 보다 앞쪽에 padding을 넣어주는 쪽이 마지막 결과에 paddind이 미치는 영향이 적어지기 때문에 더 좋은 성능을 낼 수 있다고 알고있기 때문이다.
근데 실제로는 pre padding 쪽이 loss가 더 크게 나왔다. 확인해보니 이론상으로는 pre padding이 성능이 더 좋지만 실제로는 post padding쪽이 성능이 더 잘 나와서 post padding을 많이 쓴다고 한다.
batch_size를 변경해서 pre padding을 한 번 더 돌려보았더니 같은 조건에서의 post padding 보다 loss가 높았고 문장도 부자연스러웠다. 앞으로는 post padding을 사용해야겠다.
오늘은 아이펠 첫 Exploration 노드를 진행하였다. 나는 이론보다는 실전파라 더 기대가 되는 날이었다. 매번 인터넷으로만 보던 딥러닝 모델을 내가 직접 구현해볼 수 있는 아주 좋은 기회였다. 물론 처음부터 모든 코드를 내가 짠 것은 아니지만, 지금은 어떻게 작동을 하는지 그 원리를 이해하고 익히는 것이 중요하다고 생각한다. 처음에는 노드를 열심히 따라가면서 코드를 하나하나 실행시켜 보는 것으로 시작해서, 가위바위보를 분류하는 모델은 앞서 모델링되어있는 자료를 참고하여 내가 직접 복붙(?)한 코드이다. 물론 MNIST를 이용한 숫자 분류와는 조금 다른 부분이 있어서 해당 부분만 수정할 줄 안다면 그다지 어렵지 않은 과제였다. 라고 생각했던 때가 있었지...
How to make?
일반적으로 딥러닝 기술은 "데이터 준비 → 딥러닝 네트워크 설계 → 학습 → 테스트(평가)" 순으로 이루어진다.
1. 데이터 준비
MINIST 숫자 손글씨 Dataset 불러들이기
import tensorflow as tf
from tensorflow import keras
import numpy as np
import matplotlib.pyplot as plt
print(tf.__version__) # Tensorflow의 버전 출력
mnist = keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
print(len(x_train)) # x_train 배열의 크기를 출력
plt.imshow(x_train[1], cmap=plt.cm.binary)
plt.show() # x_train의 1번째 이미지를 출력
print(y_train[1]) # x_train[1]에 대응하는 실제 숫자값
index = 10000
plt.imshow(x_train[index], cmap=plt.cm.binary)
plt.show()
print(f'{index} 번째 이미지의 숫자는 바로 {y_train[index]} 입니다.')
print(x_train.shape) # x_train 이미지의 (count, x, y)
print(x_test.shape)
Data 전처리 하기
인공지능 모델을 훈련시킬 때, 값이 너무 커지거나 하는 것을 방지하기 위해 정수 연산보다는 0~1 사이의 값으로 정규화 시켜주는 것이 좋다.
실제 테스트 데이터를 이용하여 테스트를 진행해본 결과, 99.1% 로 소폭 하락하였다. MNIST 데이터셋 참고문헌을 보면 학습용 데이터와 시험용 데이터의 손글씨 주인이 다른 것을 알 수 있다.
어떤 데이터를 잘못 추론했는지 확인해보기
model.evalutate() 대신 model.predict()를 사용하면 model이 입력값을 보고 실제로 추론한 확률분포를 출력할 수 있다.
predicted_result = model.predict(x_test_reshaped) # model이 추론한 확률값.
predicted_labels = np.argmax(predicted_result, axis=1)
idx = 0 # 1번째 x_test를 살펴보자.
print('model.predict() 결과 : ', predicted_result[idx])
print('model이 추론한 가장 가능성이 높은 결과 : ', predicted_labels[idx])
print('실제 데이터의 라벨 : ', y_test[idx])
# 실제 데이터 확인
plt.imshow(x_test[idx],cmap=plt.cm.binary)
plt.show()
추론 결과는 벡터 형태로, 추론 결과가 각각 0, 1, 2, ..., 7, 8, 9 일 확률을 의미한다.
아래 코드는 추론해낸 숫자와 실제 값이 다른 경우를 확인해보는 코드이다.
import random
wrong_predict_list=[]
for i, _ in enumerate(predicted_labels):
# i번째 test_labels과 y_test이 다른 경우만 모아 봅시다.
if predicted_labels[i] != y_test[i]:
wrong_predict_list.append(i)
# wrong_predict_list 에서 랜덤하게 5개만 뽑아봅시다.
samples = random.choices(population=wrong_predict_list, k=5)
for n in samples:
print("예측확률분포: " + str(predicted_result[n]))
print("라벨: " + str(y_test[n]) + ", 예측결과: " + str(predicted_labels[n]))
plt.imshow(x_test[n], cmap=plt.cm.binary)
plt.show()
5. 더 좋은 네트워크 만들어 보기
딥러닝 네트워크 구조 자체는 바꾸지 않으면서도 인식률을 올릴 수 있는 방법은 Hyperparameter 들을 바꿔보는 것이다. Conv2D 레이어에서 입력 이미지의 특징 수를 증감시켜보거나, Dense 레이어에서 뉴런 수를 바꾸어보거나, epoch 값을 변경해볼 수 있다.
Title
n_channel_1
n_channel_2
n_dense
n_train_epoch
loss
accuracy
1
16
32
32
10
0.0417
0.9889
2
1
32
32
10
0.0636
0.9793
3
2
32
32
10
0.0420
0.9865
4
4
32
32
10
0.0405
0.9886
5
8
32
32
10
0.0360
0.9885
6
32
32
32
10
0.0322
0.9903
7
64
32
32
10
0.0325
0.9914
8
128
32
32
10
0.0320
0.9912
9
16
1
32
10
0.1800
0.9437
10
16
64
32
10
0.0322
0.9912
11
16
128
32
10
0.0348
0.9917
12
16
32
64
10
0.0430
0.9888
13
16
32
128
10
0.0327
0.9916
14
16
32
32
15
0.0427
0.9900
15
16
32
32
20
0.0523
0.9884
16
64
128
128
15
0.0503
0.9901
각각의 Hyperparameter 별로 최적의 값을 찾아서 해당 값들만으로 테스트해보면 가장 좋은 결과가 나올 것 이라고 예상했는데 현실은 아니었다. 이래서 딥러닝이 어려운 것 같다.
6. 프로젝트: 가위바위보 분류기 만들기
오늘 배운 내용을 바탕으로 가위바위보 분류기를 만들어보자.
데이터 준비
1. 데이터 만들기
데이터는 구글의 teachable machine 사이트를 이용하면 쉽게 만들어볼 수 있다.
여러 각도에서
여러 크기로
다른 사람과 함께
만들면 더 좋은 데이터를 얻을 수 있다.
다운받은 이미지의 크기는 224x224 이다.
2. 데이터 불러오기 + Resize 하기
MNIST 데이터셋의 경우 이미지 크기가 28x28이었기 때문에 우리의 이미지도 28x28 로 만들어야 한다. 이미지를 Resize 하기 위해 PIL 라이브러리를 사용한다.
# PIL 라이브러리가 설치되어 있지 않다면 설치
!pip install pillow
from PIL import Image
import os, glob
print("PIL 라이브러리 import 완료!")
# 이미지 Resize 하기
# 가위 이미지가 저장된 디렉토리 아래의 모든 jpg 파일을 읽어들여서
image_dir_path = os.getenv("HOME") + "/aiffel/rock_scissor_paper/train/scissor"
print("이미지 디렉토리 경로: ", image_dir_path)
images=glob.glob(image_dir_path + "/*.jpg")
# 파일마다 모두 28x28 사이즈로 바꾸어 저장
target_size=(28,28)
for img in images:
old_img=Image.open(img)
new_img=old_img.resize(target_size,Image.ANTIALIAS)
new_img.save(img,"JPEG")
print("가위 이미지 resize 완료!")
# load_data 함수
def load_data(img_path, number):
# 가위 : 0, 바위 : 1, 보 : 2
number_of_data=number # 가위바위보 이미지 개수 총합
img_size=28
color=3
#이미지 데이터와 라벨(가위 : 0, 바위 : 1, 보 : 2) 데이터를 담을 행렬(matrix) 영역을 생성
imgs=np.zeros(number_of_data*img_size*img_size*color,dtype=np.int32).reshape(number_of_data,img_size,img_size,color)
labels=np.zeros(number_of_data,dtype=np.int32)
idx=0
for file in glob.iglob(img_path+'/scissor/*.jpg'):
img = np.array(Image.open(file),dtype=np.int32)
imgs[idx,:,:,:]=img # 데이터 영역에 이미지 행렬을 복사
labels[idx]=0 # 가위 : 0
idx=idx+1
for file in glob.iglob(img_path+'/rock/*.jpg'):
img = np.array(Image.open(file),dtype=np.int32)
imgs[idx,:,:,:]=img # 데이터 영역에 이미지 행렬을 복사
labels[idx]=1 # 바위 : 1
idx=idx+1
for file in glob.iglob(img_path+'/paper/*.jpg'):
img = np.array(Image.open(file),dtype=np.int32)
imgs[idx,:,:,:]=img # 데이터 영역에 이미지 행렬을 복사
labels[idx]=2 # 보 : 2
idx=idx+1
print("학습데이터(x_train)의 이미지 개수는",idx,"입니다.")
return imgs, labels
image_dir_path = os.getenv("HOME") + "/aiffel/rock_scissor_paper"
(x_train, y_train)=load_data(image_dir_path, 2100)
x_train_norm = x_train/255.0 # 입력은 0~1 사이의 값으로 정규화
print("x_train shape: {}".format(x_train.shape))
print("y_train shape: {}".format(y_train.shape))
# 불러온 이미지 확인
import matplotlib.pyplot as plt
plt.imshow(x_train[0])
print('라벨: ', y_train[0])
# 딥러닝 네트워크 설계
import tensorflow as tf
from tensorflow import keras
import numpy as np
n_channel_1=16
n_channel_2=32
n_dense=64
n_train_epoch=15
model=keras.models.Sequential()
model.add(keras.layers.Conv2D(n_channel_1, (3,3), activation='relu', input_shape=(28,28,3)))
model.add(keras.layers.MaxPool2D(2,2))
model.add(keras.layers.Conv2D(n_channel_2, (3,3), activation='relu'))
model.add(keras.layers.MaxPooling2D((2,2)))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(n_dense, activation='relu'))
model.add(keras.layers.Dense(3, activation='softmax'))
model.summary()
# 모델 학습
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train_reshaped, y_train, epochs=n_train_epoch)
# 테스트 이미지
image_dir_path = os.getenv("HOME") + "/aiffel/rock_scissor_paper/test/testset1"
(x_test, y_test)=load_data(image_dir_path, 300)
x_test_norm = x_test/255.0 # 입력은 0~1 사이의 값으로 정규화
print("x_train shape: {}".format(x_test.shape))
print("y_train shape: {}".format(y_test.shape))
# 불러온 이미지 확인
import matplotlib.pyplot as plt
plt.imshow(x_test[0])
print('라벨: ', y_test[0])
# 모델 테스트
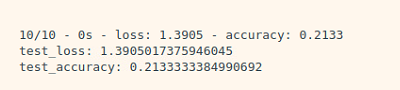
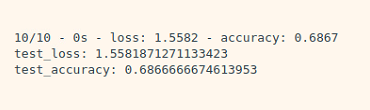
test_loss, test_accuracy = model.evaluate(x_test_reshaped, y_test, verbose=2)
print("test_loss: {} ".format(test_loss))
print("test_accuracy: {}".format(test_accuracy))
처음 100개의 데이터 가지고 실행했을 때 결과는 처참했다...
총 10명 분량을 train set으로 사용하고 test를 돌렸을 때 가장 잘 나온 결과!
오늘은 Layer를 추가하지 않고 단순히 Hyperparameter만 조정하여 인식률을 높이는 것을 목표로 했다. 우선 데이터가 부족한 것 같아서 10명 보다 더 많은 데이터를 추가해보면 좋을 것 같다. 아직 첫 모델이라 많이 부족했지만, 그래도 뭔가 목표가 있고 무엇을 해야 하는지 알게 되면 딥러닝이 조금 더 재밌어질 것 같다.