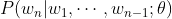텍스트 요약(Text Summarization)이란 위 그림과 같이 긴 길이의 문서(Document) 원문을 핵심 주제만으로 구성된 짧은 요약(Summary) 문장들로 변환하는 것을 말한다. 상대적으로 큰 텍스트인 뉴스 기사로 작은 텍스트인 뉴스 제목을 만들어내는 것이 텍스트 요약의 대표적인 예로 볼 수 있다.
이때 중요한 것은 요약 전후에 정보 손실 발생이 최소화되어야 한다는 점이다. 이것은 정보를 압축하는 과정과 같다. 비록 텍스트의 길이가 크게 줄어들었지만, 요약문은 문서 원문이 담고 있는 정보를 최대한 보존하고 있어야 한다. 이것은 원문의 길이가 길수록 만만치 않은 어려운 작업이 된다. 사람이 이 작업을 수행한다 하더라도 긴 문장을 정확하게 읽고 이해한 후, 그 의미를 손상하지 않는 짧은 다른 표현으로 원문을 번역해 내야 하는 것이다.
그렇다면 요약 문장을 만들어 내려면 어떤 방법을 사용하면 좋을까? 여기서 텍스트 요약은 크게 추출적 요약(Extractive Summarization)과 추상적 요약(Abstractive Summarization)의 두가지 접근으로 나누어볼 수 있다.
(1) 추출적 요약(Extractive Summarization)
첫번째 방식인 추출적 요약은 단어 그대로 원문에서 문장들을 추출해서 요약하는 방식이다. 가령, 10개의 문장으로 구성된 텍스트가 있다면, 그 중 핵심적인 문장 3개를 꺼내와서 3개의 문장으로 구성된 요약문을 만드는 식이다. 그런데 꺼내온 3개의 문장이 원문에서 중요한 문장일 수는 있어도, 3개의 문장의 연결이 자연스럽지 않을 수는 있다. 결과로 나온 문장들 간의 호응이 자연스럽지 않을 수 있다는 것이다. 딥 러닝보다는 주로 전통적인 머신 러닝 방식에 속하는 텍스트랭크(TextRank)와 같은 알고리즘을 사용한다.
(2) 추상적 요약(Abstractive Summarization)
두번째 방식인 추상적 요약은 추출적 요약보다 좀 더 흥미로운 접근을 사용한다. 원문으로부터 내용이 요약된 새로운 문장을 생성해내는 것이다. 여기서 새로운 문장이라는 것은 결과로 나온 문장이 원문에 원래 없던 문장일 수도 있다는 것을 의미한다. 자연어 처리 분야 중 자연어 생성(Natural Language Generation, NLG)의 영역인 셈이다. 반면, 추출적 요약은 원문을 구성하는 문장 중 어느 것이 요약문에 들어갈 핵심문장인지를 판별한다는 점에서 문장 분류(Text Classification) 문제로 볼 수 있을 것이다.
인공 신경망으로 텍스트 요약 훈련시키기
seq2seq 모델을 통해서 Abstractive summarization 방식의 텍스트 요약기를 만들어보자. seq2seq은 두 개의 RNN 아키텍처를 사용하여 입력 시퀀스로부터 출력 시퀀스를 생성해내는 자연어 생성 모델로 주로 뉴럴 기계번역에 사용되지만, 원문을 요약문으로 번역한다고 생각하면 충분히 사용 가능할 것이다.
seq2seq 개요
원문을 첫번째 RNN인 인코더로 입력하면, 인코더는 이를 하나의 고정된 벡터로 변환한다. 이 벡터를 문맥 정보를 가지고 있는 벡터라고 하여 컨텍스트 벡터(context vector)라고 한다. 두번째 RNN인 디코더는 이 컨텍스트 벡터를 전달받아 한 단어씩 생성해내서 요약 문장을 완성한다.
LSTM과 컨텍스트 벡터
LSTM이 바닐라 RNN과 다른 점은 다음 time step의 셀에 hidden state뿐만 아니라, cell state도 함께 전달한다는 점이다. 다시 말해, 인코더가 디코더에 전달하는 컨텍스트 벡터 또한 hidden state h와 cell state c 두 개의 값 모두 존재해야 한다는 뜻이다.
시작 토큰과 종료 토큰
[시작 토큰 SOS와 종료 토큰 EOS는 각각 start of a sequence와 end of a sequence를 나타낸다]
seq2seq 구조에서 디코더는 시작 토큰 SOS가 입력되면, 각 시점마다 단어를 생성하고 이 과정을 종료 토큰 EOS를 예측하는 순간까지 멈추지않는다. 다시 말해 훈련 데이터의 예측 대상 시퀀스의 앞, 뒤에는 시작 토큰과 종료 토큰을 넣어주는 전처리를 통해 어디서 멈춰야하는지 알려줄 필요가 있다.
어텐션 메커니즘을 통한 새로운 컨텍스트 벡터 사용하기
기존의 seq2seq는 인코더의 마지막 time step의 hidden state를 컨텍스트 벡터로 사용했다. 하지만 RNN 계열의 인공 신경망(바닐라 RNN, LSTM, GRU)의 한계로 인해 이 컨텍스트 정보에는 이미 입력 시퀀스의 많은 정보가 손실이 된 상태가 된다.
이와 달리, 어텐션 메커니즘(Attention Mechanism)은 인코더의 모든 step의 hidden state의 정보가 컨텍스트 벡터에 전부 반영되도록 하는 것이다. 하지만 인코더의 모든 hidden state가 동일한 비중으로 반영되는 것이 아니라, 디코더의 현재 time step의 예측에 인코더의 각 step이 얼마나 영향을 미치는지에 따른 가중합으로 계산되는 방식이다.
여기서 주의해야 할 것은, 컨텍스트 벡터를 구성하기 위한 인코더 hidden state의 가중치 값은 디코더의 현재 스텝이 어디냐에 따라 계속 달라진다는 점이다. 즉, 디코더의 현재 문장 생성 부위가 주어부인지 술어부인지 목적어인지 등에 따라 인코더가 입력 데이터를 해석한 컨텍스트 벡터가 다른 값이 된다. 이와 달리, 기본적인 seq2seq 모델에서 컨텍스트 벡터는 디코더의 현재 스텝 위치에 무관하게 한번 계산되면 고정값을 가진다.
인물사진 모드란, 피사체를 촬영할 때 배경이 흐려지는 효과를 넣어주는 것을 이야기 한다. 물론 DSLR의 아웃포커스 효과와는 다른 방식으로 구현한다.
핸드폰 카메라의 인물사진 모드는 듀얼 카메라를 이용해 아웃포커싱 기능을 흉내낸다.
DSLR에서는 사진을 촬영할 때 피사계 심도(depth of field, DOF)를 얕게 하여 초점이 맞은 피사체를 제외한 배경을 흐리게 만든다.
핸드폰 인물사진 모드는 화각이 다른 두 렌즈를 사용한다. 일반(광각) 렌즈에서는 배경을 촬영하고 망원 렌즈에서는 인물을 촬영한 뒤 배경을 흐리게 처리한 후 망원 렌즈의 인물과 적절하게 합성한다.
인물사진 모드에서 사용되는 용어
한국에서는 배경을 흐리게 하는 기술을 주로 '아웃포커싱'이라고 표현한다. 하지만 아웃포커싱은 한국에서만 사용하는 용어이고 정확한 영어 표현은 얕은 피사계 심도(shallow depth of field) 또는 셸로우 포커스(shallow focus) 라고 한다.
학습 목표
딥러닝을 이용하여 핸드폰 인물 사진 모드를 모방해본다.
셸로우 포커스 만들기
(1) 사진준비
하나의 카메라로 셸로우 포커스(shallow focus)를 만드는 방법은 다음과 같다.
이미지 세그멘테이션(Image segmentation) 기술을 이용하면 하나의 이미지에서 배경과 사람을 분리할 수 있다. 분리된 배경을 블러(blur)처리 후 사람 이미지와 다시 합하면 아웃포커싱 효과를 적용한 인물사진을 얻을 수 있다.
# 필요 모듈 import
import cv2
import numpy as np
import os
from glob import glob
from os.path import join
import tarfile
import urllib
from matplotlib import pyplot as plt
import tensorflow as tf
# 이미지 불러오기
import os
img_path = os.getenv('HOME')+'/aiffel/human_segmentation/images/2017.jpg' # 본인이 선택한 이미지의 경로에 맞게 바꿔 주세요.
img_orig = cv2.imread(img_path)
print (img_orig.shape)
(2) 세그멘테이션으로 사람 분리하기
배경에만 렌즈흐림 효과를 주기 위해서는 이미지에서 사람과 배경을 분리해야 한다. 흔히 포토샵으로 '누끼 따기'와 같은 작업을 이야기한다.
세그멘테이션(Segmentation)이란?
이미지에서 픽셀 단위로 관심 객체를 추출하는 방법을 이미지 세그멘테이션(image segmentation) 이라고 한다. 이미지 세그멘테이션은 모든 픽셀에 라벨(label)을 할당하고 같은 라벨은 "공통적인 특징"을 가진다고 가정한다. 이 때 공통 특징은 물리적 의미가 없을 수도 있다. 픽셀이 비슷하게 생겼다는 사실은 인식하지만, 우리가 아는 것처럼 실제 물체 단위로 인식하지 않을 수 있다. 물론 세그멘테이션에는 여러 가지 세부 태스크가 있으며, 태스크에 따라 다양한 기준으로 객체를 추출한다.
시멘틱 세그맨테이션(Semantic segmentation)이란?
세그멘테이션 중에서도 특히 우리가 인식하는 세계처럼 물리적 의미 단위로 인식하는 세그멘테이션을 시맨틱 세그멘테이션 이라고 한다. 쉽게 설명하면 이미지에서 픽셀을 사람, 자동차, 비행기 등의 물리적 단위로 분류(classification)하는 방법이라고 할 수 있다.
인스턴스 세그멘테이션(Instance segmentation)이란?
시맨틱 세그멘테이션은 '사람'이라는 추상적인 정보를 이미지에서 추출해내는 방법이다. 그래서 사람이 누구인지 관계없이 같은 라벨로 표현이 된다. 더 나아가서 인스턴스 세그멘테이션은 사람 개개인 별로 다른 라벨을 가지게 한다. 여러 사람이 한 이미지에 등장할 때 각 객체를 분할해서 인식하자는 것이 목표이다.
이미지 세그멘테이션의 간단한 알고리즘 : 워터쉐드 세그멘테이션(watershed segmentation)
이미지에서 영역을 분할하는 가장 간단한 방법은 물체의 '경계'를 나누는 것이다. 이미지는 그레이스케일(grayscale)로 변환하면 0~255의 값을 가지기 때문에 픽셀 값을 이용해서 각 위치의 높고 낮음을 구분할 수 있다. 따라서 낮은 부분부터 서서히 '물'을 채워 나간다고 생각할 때 각 영역에서 점점 물이 차오르다가 넘치는 시점을 경계선으로 만들면 물체를 서로 구분할 수 있게 된다.
(3) 시멘틱 세그멘테이션 다뤄보기
세그멘테이션 문제에는 FCN, SegNet, U-Net 등 많은 모델이 사용된다. 오늘은 그 중에서 DeepLab이라는 세그멘테이션 모델을 만들고 모델에 이미지를 입력할 것이다. DeepLab 알고리즘(DeepLab v3+)은 세그멘테이션 모델 중에서도 성능이 매우 좋아 최근까지도 많이 사용되고 있다.
# DeepLabModel Class 정의
class DeepLabModel(object):
INPUT_TENSOR_NAME = 'ImageTensor:0'
OUTPUT_TENSOR_NAME = 'SemanticPredictions:0'
INPUT_SIZE = 513
FROZEN_GRAPH_NAME = 'frozen_inference_graph'
# __init__()에서 모델 구조를 직접 구현하는 대신, tar file에서 읽어들인 그래프구조 graph_def를
# tf.compat.v1.import_graph_def를 통해 불러들여 활용하게 됩니다.
def __init__(self, tarball_path):
self.graph = tf.Graph()
graph_def = None
tar_file = tarfile.open(tarball_path)
for tar_info in tar_file.getmembers():
if self.FROZEN_GRAPH_NAME in os.path.basename(tar_info.name):
file_handle = tar_file.extractfile(tar_info)
graph_def = tf.compat.v1.GraphDef.FromString(file_handle.read())
break
tar_file.close()
with self.graph.as_default():
tf.compat.v1.import_graph_def(graph_def, name='')
self.sess = tf.compat.v1.Session(graph=self.graph)
# 이미지를 전처리하여 Tensorflow 입력으로 사용 가능한 shape의 Numpy Array로 변환합니다.
def preprocess(self, img_orig):
height, width = img_orig.shape[:2]
resize_ratio = 1.0 * self.INPUT_SIZE / max(width, height)
target_size = (int(resize_ratio * width), int(resize_ratio * height))
resized_image = cv2.resize(img_orig, target_size)
resized_rgb = cv2.cvtColor(resized_image, cv2.COLOR_BGR2RGB)
img_input = resized_rgb
return img_input
def run(self, image):
img_input = self.preprocess(image)
# Tensorflow V1에서는 model(input) 방식이 아니라 sess.run(feed_dict={input...}) 방식을 활용합니다.
batch_seg_map = self.sess.run(
self.OUTPUT_TENSOR_NAME,
feed_dict={self.INPUT_TENSOR_NAME: [img_input]})
seg_map = batch_seg_map[0]
return cv2.cvtColor(img_input, cv2.COLOR_RGB2BGR), seg_map
preprocess()는 전처리, run()은 실제로 세그멘테이셔는 하는 함수이다. input tensor를 만들기 위해 전처리를 하고, 적절한 크기로 resize하여 OpenCV의 BGR 채널은 RGB로 수정 후 run()함수의 input parameter로 사용된다.
# Model 다운로드
# define model and download & load pretrained weight
_DOWNLOAD_URL_PREFIX = 'http://download.tensorflow.org/models/'
model_dir = os.getenv('HOME')+'/aiffel/human_segmentation/models'
tf.io.gfile.makedirs(model_dir)
print ('temp directory:', model_dir)
download_path = os.path.join(model_dir, 'deeplab_model.tar.gz')
if not os.path.exists(download_path):
urllib.request.urlretrieve(_DOWNLOAD_URL_PREFIX + 'deeplabv3_mnv2_pascal_train_aug_2018_01_29.tar.gz',
download_path)
MODEL = DeepLabModel(download_path)
print('model loaded successfully!')
위 코드는 구글이 제공하는 pretrained weight이다. 이 모델은 PASCAL VOC 2012라는 대형 데이터셋으로 학습된 v3 버전이다.
# 이미지 resize
img_resized, seg_map = MODEL.run(img_orig)
print (img_orig.shape, img_resized.shape, seg_map.max()) # cv2는 채널을 HWC 순서로 표시
# seg_map.max() 의 의미는 물체로 인식된 라벨 중 가장 큰 값을 뜻하며, label의 수와 일치
# PASCAL VOC로 학습된 label
LABEL_NAMES = [
'background', 'aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus',
'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike',
'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tv'
]
len(LABEL_NAMES)
# 사람을 찾아 시각화
img_show = img_resized.copy()
seg_map = np.where(seg_map == 15, 15, 0) # 예측 중 사람만 추출 person의 label은 15
img_mask = seg_map * (255/seg_map.max()) # 255 normalization
img_mask = img_mask.astype(np.uint8)
color_mask = cv2.applyColorMap(img_mask, cv2.COLORMAP_JET)
img_show = cv2.addWeighted(img_show, 0.6, color_mask, 0.35, 0.0)
plt.imshow(cv2.cvtColor(img_show, cv2.COLOR_BGR2RGB))
plt.show()
(4) 세그멘테이션 결과를 원래 크기로 복원하기
DeepLab 모델을 사용하기 위해 이미지 크기를 작게 resize했기 때문에 원래 크기로 복원해야 한다.
cv2.resize() 함수를 이용하여 원래 크기로 복원하였다. 크기를 키울 때 보간(interpolation)을 고려해야 하는데, cv2.INTER_NEAREST를 이용하면 깔끔하게 처리할 수 있지만 더 정확하게 확대하기 위해 cv2.INTER_LINEAR를 사용하였다.
결과적으로 img_mask_up 은 경계가 블러된 픽셀값 0~255의 이미지를 얻는다. 확실한 경계를 다시 정하기 위해 중간값인 128을 기준으로 임계값(threshold)을 설정하여 128 이하의 값은 0으로 128 이상의 값은 255로 만들었다.
(5) 배경 흐리게 하기
# 배경 이미지 얻기
img_mask_color = cv2.cvtColor(img_mask_up, cv2.COLOR_GRAY2BGR)
img_bg_mask = cv2.bitwise_not(img_mask_color)
img_bg = cv2.bitwise_and(img_orig, img_bg_mask)
plt.imshow(img_bg)
plt.show()
bitwise_not : not 연산하여 이미지 반전
bitwise_and : 배경과 and 연산하여 배경만 있는 이미지를 얻을 수 있다.
# 이미지 블러처리
img_bg_blur = cv2.blur(img_bg, (13,13))
plt.imshow(cv2.cvtColor(img_bg_blur, cv2.COLOR_BGR2RGB))
plt.show()
(6) 흐린 배경과 원본 영상 합성
# 255인 부분만 원본을 가져온 후 나머지는 blur 이미지
img_concat = np.where(img_mask_color==255, img_orig, img_bg_blur)
plt.imshow(cv2.cvtColor(img_concat, cv2.COLOR_BGR2RGB))
plt.show()
회고록
평소에 사진을 취미로 하고 있어서 이번 과제를 이해하는 것이 어렵지 않았다.
이미지 세그멘테이션에 대해 단어만 알고 정확히 어떤 역할을 하는 기술인지 잘 몰랐는데 이번 학습을 통해 확실하게 알 수 있었다.
이미지를 블러처리 하는 과정에서 인물과 배경의 경계 부분도 같이 블러처리 되어버리기 때문에 나중에 이미지를 병합하는 과정에서 배경에 있는 인물 영역이 실제 사진의 인물 영역보다 넓어져 병합 후의 이미지에서 경계 주위로 그림자(?)가 지는 것 같은 현상을 볼 수 있었다.
앞으로 자율주행이나 인공지능을 이용해서 자동화 할 수 있는 부분에는 어디든 사용될 수 있을 법한 그런 기술인 것 같다.
이 기술을 이용해서 병, 캔, 플라스틱 과 같은 재활용 쓰레기를 구분할 수 있다고 하면, 환경 분야에서도 쓸 수 있지 않을까...? 그 정도로 구분하는 것은 어려울 것 같긴 하다.
jupyter notebook에서 생성된 이미지를 깔끔하게 보이도록 정리하려고 html을 이용하여 사진을 정렬했었는데 github에선 html style이 무시된다는 것을 알게되어 3시간 정도를 이미지 정렬하는 데 썼다... 결국 안 된다는 것을 깨닫고 pyplot을 이용해서 비교하였다.
이미 지난 대회였기 때문에 각종 솔루션들이 많이 올라와 있어서 컴페티션에 처음 참가하는 나와 같은 사람들에게는 입문하기 좋은 대회였던 것 같다. 인공지능 분야 공부를 시작하면서 꼭 달성하고 싶은 목표 중 하나가 캐글 컴페티션에서 메달을 얻어보는 것인데, 그 시작의 첫 걸음이라고 생각했다.
첫 참가라 어떻게 해야 할지 막막했지만, 우선 Baseline이 되는 노트북을 하나 지정하여 해당 Baseline을 기준으로 성능을 향상시켜 나가기로 하였다. 목표는 Private Score를 11만점 이하로 낮추는 것이다.
데이터를 먼저 살펴보면 다음과 같은 데이터들이 있다.
ID : 집을 구분하는 번호
date : 집을 구매한 날짜
price : 집의 가격(Target variable)
bedrooms : 침실의 수
bathrooms : 화장실의 수
sqft_living : 주거 공간의 평방 피트(면적)
sqft_lot : 부지의 평방 피트(면적)
floors : 집의 층 수
waterfront : 집의 전방에 강이 흐르는지 유무 (a.k.a. 리버뷰)
view : 집이 얼마나 좋아 보이는지의 정도
condition : 집의 전반적인 상태
grade : King County grading 시스템 기준으로 매긴 집의 등급
sqft_above : 지하실을 제외한 평방 피트(면적)
sqft_basement : 지하실의 평방 피트(면적)
yr_built : 지어진 년도
yr_renovated : 집을 재건축한 년도
zipcode : 우편번호
lat : 위도
long : 경도
sqft_living15 : 주변 15 가구의 거실 크기의 평균
sqft_lot15 : 주변 15 가구의 부지 크기의 평균
먼저 데이터를 모델에 학습시키기 전에 모델이 잘 학습할 수 있도록 데이터를 가공해주는 것이 중요하다. 데이터를 가공하는 기법 중 하나인 FE(Feature Engineerning)는 그대로 사용하기에는 어려운 데이터의 변수를 가공하여 데이터를 비교적 간단명료하게 만드는 작업이다. 실제로 대회를 진행하다보니 이 FE을 얼만큼 잘 했느냐에 따라서 점수가 생각보다 많이 차이났었다.
target인 price의 분포를 확인해보니 선형으로 표현하긴 어려울 것 같아서 log scale로 변환하였다.
이제 어느 정도 선형성을 가지는 것 같다.
위의 그림은 스피어만 순위 상관계수를 히트맵으로 나타내보았다. 스피어만 순위 상관계수는 범주형 변수가 포함되어 있을 때, 목적변수와 가장 상관관계가 높은 순서대로 정렬해주는 식이다. 위의 히트맵에 따르면 가격과 가장 상관관계가 높은 변수들은 grade, sqft_living, sqft_living15 순으로 나타나는 것을 확인할 수 있다.
이상치를 제거하기 위하여 몇 가지 변수들을 살펴보았다. 그 중 grade에서는 다음과 같은 요소들을 확인해보고 이상치라고 생각되는 값들은 제거해주었다.
등급 3의 값이 큰 이유
등급 7, 8, 9에서 이상치가 많은 이유
등급 8과 11에서 큰 이상치가 나타나는 이유
모델이 더 잘 학습할 수 있도록 기존에 있는 변수들을 활용하여 새로운 Feature들을 생성해주었다.
새로 생성한 Feature에는 방의 전체 갯수, 거실의 비율, 면적대비 거실의 비율, 재건축 여부, 평당 가격, zipcode를 이용하여 위치에 따른 가격 등이 있다.
실제로 zipcode를 기준으로 평균 가격정보를 시각화 해보았더니 어느 정도 유의미한 변수인 것으로 볼 수 있었다.
FE를 끝내고 나면, train data에서 target인 price를 분리하여 train data를 모델에 학습시킨다.
사용한 모델은 XGBoost와 LightGBM 여러 개의 모델을 VotingRegressor로 앙상블 하여 사용하였다.
결과는 최종 Public Score 108111.71518, Private Score 106922.61196 으로 마무리하였다.
대회를 진행하면서 느낀점은, 모델을 향상시킨다는 것은 생각보다 어렵고 복잡한 일이라는 것이었다. 처음에는 추가로 FE를 진행하지 않고 있는 데이터만으로 모델을 학습시켰었는데 원하는 만큼의 성능이 나오질 않아서 다른 노트북을 참고하여 추가로 FE를 진행하였더니 그것 만으로도 엄청나게 성능이 향상되어 한 번에 원하는 결과를 얻을 수 있었다. 그 이전까지는 Hyperparameter 튜닝만으로는 어떻게 해도 11만점 이하가 나오질 않았었다.
또한, 학습 시의 결과가 좋다고 항상 실전 결과가 좋은 것은 아니었다. 물론 어느 정도의 경향성은 있지만 절대적인 것은 아니었다. 테스트 시에는 XGB가 가장 좋은 결과를 보여줘서 제출했는데 Public Score는 좋았지만 Private Score는 좋지 못했다. 이 부분은 아마 너무 train dataset에만 Overfitting 되어있어서 Private Score를 측정하는 test dataset에는 잘 예측을 하지 못한 것 같다.
이번 대회를 진행하면서 확실히 성장했다고 느낄 수 있었다. 더 좋은 Hyperparameter를 찾기 위해 GridSearch가 아닌 Optuna라는 라이브러리를 이용하여 RandomSearch도 시도해보고, 노드에서 가르쳐주지 않은 VotingRegressor나 HistGradientBoostingRegressor와 같이 다른 앙상블 모델도 사용해보면서 모델 설계에 대한 이해도가 조금은 높아진 것 같다.
생각보다 11만점의 벽이 높아서 거의 2주 정도를 매달렸지만, 그래도 원하는 목표치를 달성할 수 있어서 기분도 좋고, 무엇보다 공부하면서 모델을 학습시키는 과정이 지루하지 않아서 재미있었다.
지금은 더 경험을 쌓기 위하여 다른 친구와 함께 Dacon에 참가하고 있는데, Baseline도 없이 데이터 처리부터 모델 설계를 하려고 하니 내가 무엇이 부족한지를 너무 뼈저리게 느낄 수 있어서 더 공부를 열심히 하는 계기가 되고 있다.
Implicit 라이브러리를 활용하여 Matrix Factorization(이하 MF) 기반의 추천 모델을 만들어 본다.
음악 감상 기록을 활용하여 비슷한 아티스트를 찾고 아티스트를 추천해 본다.
추천 시스템에서 자주 사용되는 데이터 구조인 CSR Matrix을 익힌다
유저의 행위 데이터 중 Explicit data와 Implicit data의 차이점을 익힌다.
새로운 데이터셋으로 직접 추천 모델을 만들어 본다.
추천시스템이란?
추천시스템이란, 데이터를 바탕으로 유저가 좋아할 만한 콘텐츠를 찾아서 자동으로 보여주거나 추천해주는 기능이다. 추천시스템의 원리는 간단하게 설명하면 나와 비슷한 다른 사용자들이 좋아하는 것과 비슷한 것을 내게 추천해준다는 것이다. 이러한 추천시스템은 크게 두 가지로 나뉜다.
협업 필터링이란 대규모의 기존 사용자 행동 정보를 분석하여 해당 사용자와 비슷한 성향의 사용자들이 기존에 좋아했던 항목을 추천하는 기술이다.
장점
결과가 직관적이며 항목의 구체적인 내용을 분석할 필요가 없다.
단점
콜드 스타트(Cold Start)문제가 있다.
계산량이 비교적 많은 알고리즘이므로 사용자 수가 많은 경우 효율적으로 추천할 수 없다.
시스템 항목이 많다 하더라도 사용자들은 소수의 인기있는 항목에만 관심을 보이는 롱테일(Long tail)문제가 있다.
행렬분해(Matrix Factorization), k-최근접 이웃 알고리즘 (k-Nearest Neighbor algorithm; kNN) 등의 방법이 많이 사용된다.
(2) 콘텐츠 기반 필터링
콘텐츠 기반 필터링은 항목 자체를 분석하여 추천을 구현한다. 예를 들어 음악을 추천하기 위해 음악 자체를 분석하여 유사한 음악을 추천하는 방식이다.
콘텐츠 기반 필터링을 위해서는 항목을 분석한 프로파일(item profile)과 사용자의 선호도를 추출한 프로파일(user profile)을 추출하여 이의 유사성을 계산한다. 유명한 음악 사이트인 판도 라(Pandora)의 경우, 신곡이 출시되면 음악을 분석하여 장르, 비트, 음색 등 약 400여 항목의 특 성을 추출한다. 그리고 사용자로부터는 ‘like’를 받은 음악의 특색을 바탕으로 해당 사용자의 프로 파일을 준비한다. 이러한 음악의 특성과 사용자 프로파일을 비교함으로써 사용자가 선호할 만한 음악을 제공하게 된다.
군집분석(Clustering analysis), 인공신경망(Artificial neural network), tf-idf(term frequencyinverse document frequency) 등의 기술이 사용된다.
추천시스템은 아이템은 매우 많고, 유저의 취향은 다양할 때 유저가 소비할 만한 아이템을 예측하는 모델이다.
유튜브 : 동영상이 매일 엄청나게 많이 올라오고 유저의 취향(게임 선호, 뷰티 선호, 지식 선호, 뉴스 선호)이 다양
페이스북 : 포스팅되는 글이 엄청 많고 유저가 관심 있는 페이지, 친구, 그룹은 전부 다름
# 파일 불러오기
import pandas as pd
import os
fname = os.getenv('HOME') + '/aiffel/recommendata_iu/data/lastfm-dataset-360K/usersha1-artmbid-artname-plays.tsv'
col_names = ['user_id', 'artist_MBID', 'artist', 'play'] # 임의로 지정한 컬럼명
data = pd.read_csv(fname, sep='\t', names= col_names) # sep='\t'
data.head(10)
# 사용하는 컬럼 재정의
using_cols = ['user_id', 'artist', 'play']
data = data[using_cols]
data.head(10)
data['artist'] = data['artist'].str.lower() # 검색을 쉽게하기 위해 아티스트 문자열을 소문자로 변경
data.head(10)
# 첫 번째 유저 데이터 확인
condition = (data['user_id']== data.loc[0, 'user_id'])
data.loc[condition]
(2) 데이터 탐색
확인이 필요한 정보
유저수, 아티스트수, 인기 많은 아티스트
유저들이 몇 명의 아티스트를 듣고 있는지에 대한 통계
유저 play 횟수 중앙값에 대한 통계
# 유저 수
data['user_id'].nunique()
# 아티스트 수
data['artist'].nunique()
# 인기 많은 아티스트
artist_count = data.groupby('artist')['user_id'].count()
artist_count.sort_values(ascending=False).head(30)
# 유저별 몇 명의 아티스트를 듣고 있는지에 대한 통계
user_count = data.groupby('user_id')['artist'].count()
user_count.describe()
# 유저별 play횟수 중앙값에 대한 통계
user_median = data.groupby('user_id')['play'].median()
user_median.describe()
# 이름은 꼭 데이터셋에 있는 것으로
my_favorite = ['black eyed peas' , 'maroon5' ,'jason mraz' ,'coldplay' ,'beyoncé']
# 'zimin'이라는 user_id가 위 아티스트의 노래를 30회씩 들었다고 가정
my_playlist = pd.DataFrame({'user_id': ['zimin']*5, 'artist': my_favorite, 'play':[30]*5})
if not data.isin({'user_id':['zimin']})['user_id'].any(): # user_id에 'zimin'이라는 데이터가 없다면
data = data.append(my_playlist) # 위에 임의로 만든 my_favorite 데이터를 추가
data.tail(10) # 잘 추가되었는지 확인
(3) 모델에 활용하기 위한 전처리
데이터의 관리를 쉽게 하기 위해 indexing 작업을 해준다.
# 고유한 유저, 아티스트를 찾아내는 코드
user_unique = data['user_id'].unique()
artist_unique = data['artist'].unique()
# 유저, 아티스트 indexing 하는 코드 idx는 index의 약자
user_to_idx = {v:k for k,v in enumerate(user_unique)}
artist_to_idx = {v:k for k,v in enumerate(artist_unique)}
# 인덱싱이 잘 되었는지 확인해 봅니다.
print(user_to_idx['zimin']) # 358869명의 유저 중 마지막으로 추가된 유저이니 358868이 나와야 합니다.
print(artist_to_idx['black eyed peas'])
# indexing을 통해 데이터 컬럼 내 값을 바꾸는 코드
# dictionary 자료형의 get 함수는 https://wikidocs.net/16 을 참고하세요.
# user_to_idx.get을 통해 user_id 컬럼의 모든 값을 인덱싱한 Series를 구해 봅시다.
# 혹시 정상적으로 인덱싱되지 않은 row가 있다면 인덱스가 NaN이 될 테니 dropna()로 제거합니다.
temp_user_data = data['user_id'].map(user_to_idx.get).dropna()
if len(temp_user_data) == len(data): # 모든 row가 정상적으로 인덱싱되었다면
print('user_id column indexing OK!!')
data['user_id'] = temp_user_data # data['user_id']을 인덱싱된 Series로 교체해 줍니다.
else:
print('user_id column indexing Fail!!')
# artist_to_idx을 통해 artist 컬럼도 동일한 방식으로 인덱싱해 줍니다.
temp_artist_data = data['artist'].map(artist_to_idx.get).dropna()
if len(temp_artist_data) == len(data):
print('artist column indexing OK!!')
data['artist'] = temp_artist_data
else:
print('artist column indexing Fail!!')
data
사용자의 명시적/암묵적 평가
명시적 데이터(Explicit Data) : 좋아요, 평점과 같이 유저가 자신의 선호도를 직접(Explicit)표현한 데이터
암묵적 데이터(Implicit Data) : 유저가 간접적(Implicit)으로 선호, 취향을 나타내는 데이터. 검색기록, 방문페이지, 구매내역, 마우스 움직임 기록 등이 있다.
# 1회만 play한 데이터의 비율을 보는 코드
only_one = data[data['play']<2]
one, all_data = len(only_one), len(data)
print(f'{one},{all_data}')
print(f'Ratio of only_one over all data is {one/all_data:.2%}')
이번에 만들 모델에서는 암묵적 데이터의 해석을 위해 다음과 같은 규칙을 적용한다.
한 번이라도 들었으면 선호한다고 판단한다.
많이 재생한 아티스트에 대해 가중치를 주어서 더 확실히 좋아한다고 판단한다.
Matrix Factorization(MF)
추천시스템의 다양한 모델 중 Matrix Factorization(MF, 행렬분해) 모델을 사용할 것이다.
MF는 평가행렬 R을 P와 Q 두 개의 Feature Matrix로 분해하는 것이다. 아래 그림에서는 P가 사용자의 특성(Feature) 벡터고, Q는 영화의 특성 벡터가 된다. 두 벡터를 내적해서 얻어지는 값이 영화 선호도로 간주하는 것이다.
벡터를 잘 만드는 기준은 유저i의 벡터 와 아이템j의 벡터 를 내적했을 때 유저i가 아이템j에 대해 평가한 수치 와 비슷한지 확인하는 것이다.
Matrix Factorization 모델을 implicit 패키지를 사용하여 학습해보자.
implicit 패키지는 이전 스텝에서 설명한 암묵적(implicit) dataset을 사용하는 다양한 모델을 굉장히 빠르게 학습할 수 있는 패키지이다.
이 패키지에 구현된 als(AlternatingLeastSquares) 모델을 사용한다. Matrix Factorization에서 쪼개진 두 Feature Matrix를 한꺼번에 훈련하는 것은 잘 수렴하지 않기 때문에, 한쪽을 고정시키고 다른 쪽을 학습하는 방식을 번갈아 수행하는 AlternatingLeastSquares 방식이 효과적인 것으로 알려져 있다.
from implicit.als import AlternatingLeastSquares
import os
import numpy as np
# implicit 라이브러리에서 권장하고 있는 부분
os.environ['OPENBLAS_NUM_THREADS']='1'
os.environ['KMP_DUPLICATE_LIB_OK']='True'
os.environ['MKL_NUM_THREADS']='1'
# Implicit AlternatingLeastSquares 모델의 선언
als_model = AlternatingLeastSquares(factors=100, regularization=0.01, use_gpu=False, iterations=15, dtype=np.float32)
# als 모델은 input으로 (item X user 꼴의 matrix를 받기 때문에 Transpose해줍니다.)
csr_data_transpose = csr_data.T
csr_data_transpose
# 모델 훈련
als_model.fit(csr_data_transpose)
# 벡터값 확인
zimin, black_eyed_peas = user_to_idx['zimin'], artist_to_idx['black eyed peas']
zimin_vector, black_eyed_peas_vector = als_model.user_factors[zimin], als_model.item_factors[black_eyed_peas]
zimin_vector
black_eyed_peas_vector
# zimin과 black_eyed_peas를 내적하는 코드
np.dot(zimin_vector, black_eyed_peas_vector) # 0.5098079
# 다른 아티스트에 대한 선호도
queen = artist_to_idx['queen']
queen_vector = als_model.item_factors[queen]
np.dot(zimin_vector, queen_vector) # 0.3044492
비슷한 아티스트 찾기 + 유저에게 추천하기
(1) 비슷한 아티스트 찾기
AlternatingLeastSquares 클래스에 구현되어 있는 similar_items 메서드를 통하여 비슷한 아티스트를 찾는다.
# 비슷한 아티스트 찾기
favorite_artist = 'coldplay'
artist_id = artist_to_idx[favorite_artist]
similar_artist = als_model.similar_items(artist_id, N=15)
similar_artist
# #artist_to_idx 를 뒤집어, index로부터 artist 이름을 얻는 dict를 생성합니다.
idx_to_artist = {v:k for k,v in artist_to_idx.items()}
[idx_to_artist[i[0]] for i in similar_artist]
# 비슷한 아티스트를 찾아주는 함수
def get_similar_artist(artist_name: str):
artist_id = artist_to_idx[artist_name]
similar_artist = als_model.similar_items(artist_id)
similar_artist = [idx_to_artist[i[0]] for i in similar_artist]
return similar_artist
# 다른 아티스트 확인
get_similar_artist('2pac')
get_similar_artist('lady gaga')
특정 장르를 선호하는 사람들은 선호도가 집중되기 때문에 장르별 특성이 두드러진다.
(2) 유저에게 아티스트 추천하기
AlternatingLeastSquares 클래스에 구현되어 있는 recommend 메서드를 통하여 좋아할 만한 아티스트를 추천받는다. filter_already_liked_items 는 유저가 이미 평가한 아이템은 제외하는 Argument이다.
user = user_to_idx['zimin']
# recommend에서는 user*item CSR Matrix를 받습니다.
artist_recommended = als_model.recommend(user, csr_data, N=20, filter_already_liked_items=True)
artist_recommended
# index to artist
[idx_to_artist[i[0]] for i in artist_recommended]
# 추천 기여도 확인
rihanna = artist_to_idx['rihanna']
explain = als_model.explain(user, csr_data, itemid=rihanna)
[(idx_to_artist[i[0]], i[1]) for i in explain[1]]
(3) 마무리
추천시스템에서 Baseline으로 많이 사용되는 MF를 통해 아티스트를 추천하는 모델을 만들어보았다. 그러나 이 모델은 몇 가지 아쉬운 점이 있다.
유저, 아티스트에 대한 Meta정보를 반영하기 쉽지 않다. 예를 들어 연령대별로 음악 취향이 다를 수 있는데 이러한 부분을 반영하기 어렵다.
유저가 언제 play했는지 반영하기 어렵다. 10년 전에 재생된 노래랑 지금 재생되는 노래랑 비교해보자.
회고록
csr_data를 만드는데 왜인지 모르겠지만 unique로 뽑은 값을 shape에다 넣어줬더니 row index가 넘었다고 에러가 떴다. 그래서 shape를 넣지 않고 그냥 돌렸더니 생성이 되었고, 만들어진 csr_data의 shape를 확인해보니 unique값과 달랐다. 왜 그런지는 잘 모르겠다... NaN값이 있나..?
오늘 한 과제가 지금까지 한 과제 중에서 가장 어려웠던 것 같다. 아직 데이터 전처리에 익숙하지 않아서 그럴 수도 있지만 데이터 전처리가 거의 전부인 것 같다.
데이터 전처리만 잘 해도 반은 성공한다는 느낌이다. 애초에 데이터가 없으면 시작조차 할 수 없으니 데이터 전처리하는 방법과 pandas, numpy등 사용 방법에 대해 잘 익혀둬야 겠다.
모델을 훈련하여 실제로 추천받은 목록을 보니 토이스토리를 골랐을 때 토이스토리2, 벅스라이프, 알라딘 등을 추천해주는 걸 보면 만화애니메이션 장르쪽을 추천해주고 있다. 따라서 훈련이 잘 이루어졌다고 평가할 수 있을 것 같다.
csr_data를 만들 때 shape 에서 Error가 발생하는 이유를 알아냈다. 그 원인은 csr_data의 (row_ind, col_ind) parameter가 max(row_ind), max(col_ind)로 작동하여 row_ind와 col_ind의 index의 최댓값을 사용하기 때문이다. 물론 row와 col이 index 순으로 잘 정렬되어 있다면 이렇게 해도 문제가 없지만, 실제로는 movie_id의 중간에 빠진 index들이 있기 때문에 movie_id의 총 갯수인 3628개 보다 큰 max(row_ind)의 3953개가 parameter로 사용되는 것이다. user_id도 마찬가지로 unique한 값은 6040개지만, index가 1부터 시작하여 끝값은 6041이므로 총 6042개를 col_ind로 사용하게 된다. 이 부분은 수정해보려고 했으나, movie_id마다 이미 할당된 title이 있기 때문에 ratings DataFrame에 다시 movie_id에 맞는 title column을 더해주고 movie_id순으로 중복을 제거하고 sort하여 title에 다시 movie_id를 할당해 주는 작업이 너무 번거로워서 그만뒀다.
컴퓨터에는 감각기관이 없어서 우리가 쉽게 인지하는 시각, 촉각, 청각 정보들을 즉각적으로 판단하기 어렵다. 오직 0과 1의 조합으로 데이터를 표현해주어야 한다. 우리는 어떻게 컴퓨터에게 다양한 형태의 정보를 표현해줄 수 있을까?
우리는 어떤 벡터 공간(Vector Space)에다가 우리가 표현하고자 하는 정보를 Mapping하는 방법을 사용할 수 밖에 없다. 단어나 이미지 오브젝트나 무언가를 벡터로 표현한다면, 그것은 원점에서 출발한 벡터 공간상의 한 점이 될 것이다. 따라서, 우리가 하고 싶은 것은 점들 사이의 관계를 알아보는 것이다.
오늘 다루어 보고자 하는 '두 얼굴이 얼마나 닮았나'하는 문제는 두 얼굴 벡터 사이의 거리가 얼마나 되나 하는 문제로 치환된다. 중요한 것은 두 점 사이의 거리가 실제로 두 오브젝트 사이의 유사도를 정확하게 반영해야 한다는 것이다.
만약 100x100픽셀의 컬러 사진이라면 RGB 3개의 채널까지 고려해 무려 3x100x100 = 30000차원의 벡터를 얼굴 개수만큼 비교해야 한다. 그러나 너무 높은 차원의 공간에서 비교는 사실상 무의미해지기 때문에 고차원 정보를 저차원으로 변환하면서 필요한 정보만을 보존하는 것이 바로 임베딩이다.
임베딩 벡터에 보존되어야 하는 정보는 상대적인 비교수치이다. 이 상대적인 비교수치를 딥러닝을 통해 학습할 수 있도록 해보자.
얼굴 임베딩 만들기
(1) 얼굴인식
이미지 속의 두 얼굴이 얼마나 닮았는지 알아보기 위해서는 우선 이미지 속에서 얼굴 영역만을 정확하게 인식해서 추출하는 작업이 필요하다.
이전에 dlib를 이용하여 얼굴 인식을 해보았기 때문에, 오늘은 dlib을 사용해서 만들어진 Face Recognition 라이브러리를 이용해서 과제를 진행할 예정이다. pip를 이용해 라이브러리를 설치한다.
2015년 구글에서 발표한 FaceNet은 일반적인 딥러닝 모델과 크게 다르지 않지만, 네트워크 뒤에 L2 Normalization을 거쳐 임베딩을 만들어내고 여기에 Triplet Loss를 사용하고 있다.
Triplet Loss는 유사한 것은 벡터를 가깝게 위치시키고, 다른 것은 벡터를 멀게 위치시키는 효과를 가져온다. 예를 들어, 같은 사람의 얼굴은 벡터를 가깝게 하고, 다른 사람의 얼굴은 벡터를 멀게 하는 것이다.
얼굴 임베딩 사이의 거리측정
얼굴 임베딩 공간의 시각화
임베딩 벡터를 numpy 배열로 보면 벡터들의 거리를 한 눈에 알기 어렵다. 따라서 시각화를 통해 쉽게 이해할 수 있다.
고차원의 데이터를 시각화하기 위해서는 차원을 축소해야 하는데, 그 방법에는 PCA, T-SNE 등이 있다. Tensorflow의 Projector는 고차원 벡터를 차원 축소 기법을 사용해서 눈으로 확인할 수 있게 해준다.
PCA(Principal Component Analysis, 주성분 분석) : 모든 차원 축에 따른 값의 변화도인 분산(Variance)를 확인한 뒤 그 중 변화가 가장 큰 주요한 축을 남기는 방법
T-SNE : 고차원 상에서 먼 거리를 저차원 상에서도 멀리 배치되도록 차원을 축소하는 방식. 먼저 random하게 목표하는 차원에 데이터를 배치 후, 각 데이터들을 고차원 상에서의 배치와 비교하면서 위치를 변경해준다.
가장 닮은 꼴 얼굴 찾아보기
우리가 만들고 싶은 함수는 name parameter로 특정 사람 이름을 주면 그 사람과 가장 닮은 이미지와 거리 정보를 가장 가까운 순으로 표시해주어야 한다.
나랑 닮은 연예인을 찾아보자
# 필요 module import
import os
import face_recognition
import numpy as np
import matplotlib.pyplot as plt
# directory의 file list 불러오기
dir_path = os.getenv('HOME')+'/aiffel/face_embedding/images/actor'
file_list = os.listdir(dir_path)
print ("file_list: {}".format(file_list))
# 얼굴 영역만 잘라서 출력하는 함수
def get_cropped_face(image_file):
image = face_recognition.load_image_file(image_file)
face_locations = face_recognition.face_locations(image)
if face_locations:
a, b, c, d = face_locations[0]
cropped_face = image[a:c,d:b,:]
return cropped_face
else:
return []
# 임베딩 벡터 구하기
image_file = os.path.join(dir_path, '내사진.jpg')
cropped_face = get_cropped_face(image_file) # 얼굴 영역을 구하는 함수(이전 스텝에서 구현)
# 이미지 확인
%matplotlib inline
plt.imshow(cropped_face)
# 얼굴 영역을 가지고 얼굴 임베딩 벡터를 구하는 함수
def get_face_embedding(face):
return face_recognition.face_encodings(face)
embedding = get_face_embedding(cropped_face)
embedding
# embedding dict 만드는 함수
def get_face_embedding_dict(dir_path):
file_list = os.listdir(dir_path)
embedding_dict = {}
cropped_dict = {}
for file in file_list:
img_path = os.path.join(dir_path, file)
face = get_cropped_face(img_path)
if face == []:
continue
embedding = get_face_embedding(face)
if len(embedding) > 0:
# splitext = file, extension
embedding_dict[os.path.splitext(file)[0]] = embedding[0]
cropped_dict[os.path.splitext(file)[0]] = face
return embedding_dict, cropped_dict
# embedding_dict 만들기
embedding_dict, cropped_dict = get_face_embedding_dict(dir_path)
embedding_dict['내사진']
# 두 얼굴 사이의 거리 구하기
def get_distance(name1, name2):
return np.linalg.norm(embedding_dict[name1]-embedding_dict[name2], ord=2)
# 내 사진으로 비교
get_distance('내사진','내사진1')
# name1과 name2의 거리를 비교하는 함수
def get_sort_key_func(name1):
def get_distance_from_name1(name2):
return get_distance(name1, name2)
return get_distance_from_name1
# 거리를 비교할 name1 미리 지정
sort_key_func = get_sort_key_func('내사진')
# 순위에 맞는 이미지 출력
def get_nearest_face_images(sorted_faces, top=5):
fig = plt.figure(figsize=(15, 5))
fig.add_subplot(2, top, 1)
plt.imshow(cropped_dict[sorted_faces[0][0]])
for i in range(1, top+1):
fig.add_subplot(2, top, i+5)
plt.imshow(cropped_dict[sorted_faces[i][0]])
# 가장 닮은 꼴 찾기
def get_nearest_face(name, top=5):
sort_key_func = get_sort_key_func(name)
sorted_faces = sorted(embedding_dict.items(), key=lambda x:sort_key_func(x[0]))
for i in range(top+1):
if i == 0:
continue
if sorted_faces[i]:
print(f'순위 {i} : 이름 ({sorted_faces[i][0]}), 거리({sort_key_func(sorted_faces[i][0])})')
return sorted_faces
# 순위 출력
sorted_faces = get_nearest_face('내사진')
# 순위에 따른 이미지 출력
get_nearest_face_images(sorted_faces)
회고록
임베딩이란 개념에 대해 지난 번에 한번 학습했었던 경험이 있다보니 이번 과제의 난이도가 조금 덜 어렵게 느껴진다.
고차원을 가지는 이미지를 저차원에서 시각화 하는 개념에 대해 조금 생소하게 느껴졌지만 tensowflow의 Projector로 확인해보니 바로 이해할 수 있었다.
한 사람에 한 장의 이미지 만으로는 아무래도 닮은 정도를 비교하기 어려운 것 같다. 나랑 거리가 가까운 연예인이라고 나온 결과를 내 사진과 비교해 보니 전혀 아닌듯 ㅎ...
오늘은 혼자서 matplotlib을 이용하여 결과를 조금 더 보기 좋게 꾸며봤다.
혹시나 해서 한국 연예인 얼굴 사진 Dataset이 있는지 찾아봤는데 보이질 않았다. 내가 못 찾는건지, 아니면 초상권 등으로 인해서 없는건지...
문장은 각 단어들이 문법이라는 규칙을 따라 배열되어 있기 때문에 시퀀스 데이터로 볼 수 있다.
문법은 복잡하기 때문에 문장 데이터를 이용한 인공지능을 만들 때에는 통계에 기반한 방법을 이용한다.
순환신경망(RNN)
나는 공부를 [ ]에서 빈 칸에는 한다 라는 단어가 들어갈 것이다. 문장에는 앞 뒤 문맥에 따라 통계적으로 많이 사용되는 단어들이 있다. 인공지능이 글을 이해하는 방식도 위와 같다. 문법적인 원리를 통해서가 아닌 수많은 글을 읽게하여 통계적으로 다음 단어는 어떤 것이 올지 예측하는 것이다. 이 방식에 가장 적합한 인공지능 모델 중 하나가 순환신경망(RNN)이다.
시작은 <start>라는 특수한 토큰을 앞에 추가하여 시작을 나타내고, <end>라는 토큰을 통해 문장의 끝을 나타낸다.
언어 모델
나는, 공부를, 한다 를 순차적으로 생성할 때, 우리는 공부를 다음이 한다인 것을 쉽게 할 수 있다. 나는 다음이 한다인 것은 어딘가 어색하게 느껴진다. 실제로 인공지능이 동작하는 방식도 순전히 운이다.
이것을 좀 더 확률적으로 표현해 보면 나는 공부를 다음에 한다가 나올 확률을 $p(한다|나는, 공부를)$라고 하면, $p(공부를|나는)$보다는 높게 나올 것이다. $p(한다|나는, 공부를, 열심히)$의 확률값은 더 높아질 것이다.
문장에서 단어 뒤에 다음 단어가 나올 확률이 높다는 것은 그 단어가 자연스럽다는 뜻이 된다. 확률이 낮다고 해서 자연스럽지 않은 것은 아니다. 단어 뒤에 올 수 있는 자연스러운 단어의 경우의 수가 워낙 많아서 불확실성이 높을 뿐이다.
n-1개의 단어 시퀀스 $w_1,⋯,w_{n-1}$이 주어졌을 때, n번째 단어 $w_n$으로 무엇이 올지 예측하는 확률 모델을 언어 모델(Language Model)이라고 부른다. 파라미터 $\theta$로 모델링 하는 언어 모델을 다음과 같이 표현할 수 있다.
언어 모델은 어떻게 학습시킬 수 있을까? 언어 모델의 학습 데이터는 어떻게 나누어야 할까? 답은 간단하다. 어떠한 텍스트도 언어 모델의 학습 데이터가 될 수 있다. x_train이 n-1번째까지의 단어 시퀀스고, y_train이 n번째 단어가 되는 데이터셋이면 얼마든지 학습 데이터로 사용할 수 있다. 이렇게 잘 훈련된 언어 모델은 훌륭한 문장 생성기가 된다.
인공지능 만들기
(1) 데이터 준비
import re
import numpy as np
import tensorflow as tf
import os
# 파일 열기
file_path = os.getenv('HOME') + '/aiffel/lyricist/data/shakespeare.txt'
with open(file_path, "r") as f:
raw_corpus = f.read().splitlines() # 텍스트를 라인 단위로 끊어서 list 형태로 읽어온다.
print(raw_corpus[:9])
데이터에서 우리가 원하는 것은 문장(대사)뿐이므로, 화자 이름이나 공백은 제거해주어야 한다.
# 문장 indexing
for idx, sentence in enumerate(raw_corpus):
if len(sentence) == 0: continue # 길이가 0인 문장은 스킵
if sentence[-1] == ":": continue # :로 끝나는 문장은 스킵
if idx > 9: break
print(sentence)
이제 문장을 단어로 나누어야 한다. 문장을 형태소로 나누는 것을 토큰화(Tokenize)라고 한다. 가장 간단한 방법은 띄어쓰기를 기준으로 나누는 것이다. 그러나 문장부호, 대소문자, 특수문자 등이 있기 때문에 따로 전처리를 먼저 해주어야 한다.
# 문장 전처리 함수
def preprocess_sentence(sentence):
sentence = sentence.lower().strip() # 소문자로 바꾸고 양쪽 공백을 삭제
# 정규식을 이용하여 문장 처리
sentence = re.sub(r"([?.!,¿])", r" \1 ", sentence) # 패턴의 특수문자를 만나면 특수문자 양쪽에 공백을 추가
sentence = re.sub(r'[" "]+', " ", sentence) # 공백 패턴을 만나면 스페이스 1개로 치환
sentence = re.sub(r"[^a-zA-Z?.!,¿]+", " ", sentence) # a-zA-Z?.!,¿ 패턴을 제외한 모든 문자(공백문자까지도)를 스페이스 1개로 치환
sentence = sentence.strip()
sentence = '<start> ' + sentence + ' <end>' # 문장 앞뒤로 <start>와 <end>를 단어처럼 붙여 줍니다
return sentence
print(preprocess_sentence("Hi, This @_is ;;;sample sentence?"))
우리가 구축해야할 데이터셋은 입력이 되는 소스 문장(Source Sentence)과 출력이 되는 타겟 문장(Target Sentence)으로 나누어야 한다.
언어 모델의 입력 문장 : <start> 나는 공부를 한다
언어 모델의 출력 문장 : 나는 공부를 한다 <end>
위에서 만든 전처리 함수에서 를 제거하면 소스 문장, 를 제거하면 타겟 문장이 된다.
corpus = []
# 모든 문장에 전처리 함수 적용
for sentence in raw_corpus:
if len(sentence) == 0: continue
if sentence[-1] == ":": continue
corpus.append(preprocess_sentence(sentence))
corpus[:10]
이제 문장을 컴퓨터가 이해할 수 있는 숫자로 변경해주어야 한다. 텐서플로우는 자연어 처리를 위한 여러 가지 모듈을 제공하며, tf.keras.preprocessing.text.Tokenizer 패키지는 데이터를 토큰화하고, dictionary를 만들어주며, 데이터를 숫자로 변환까지 한 번에 해준다. 이 과정을 벡터화(Vectorize)라고 하며, 변환된 숫자 데이터를 텐서(tensor)라고 한다.
def tokenize(corpus):
# 텐서플로우에서 제공하는 Tokenizer 패키지를 생성
tokenizer = tf.keras.preprocessing.text.Tokenizer(
num_words=7000, # 전체 단어의 개수
filters=' ', # 전처리 로직
oov_token="<unk>" # out-of-vocabulary, 사전에 없는 단어
)
tokenizer.fit_on_texts(corpus) # 우리가 구축한 corpus로부터 Tokenizer가 사전을 자동구축
# tokenizer를 활용하여 모델에 입력할 데이터셋을 구축
tensor = tokenizer.texts_to_sequences(corpus) # tokenizer는 구축한 사전으로부터 corpus를 해석해 Tensor로 변환
# 입력 데이터의 시퀀스 길이를 일정하게 맞추기 위한 padding 메소드
# maxlen의 디폴트값은 None. corpus의 가장 긴 문장을 기준으로 시퀀스 길이가 맞춰진다
tensor = tf.keras.preprocessing.sequence.pad_sequences(tensor, padding='post')
print(tensor,tokenizer)
return tensor, tokenizer
tensor, tokenizer = tokenize(corpus)
print(tensor[:3, :10]) # 생성된 텐서 데이터 확인
# 단어 사전의 index
for idx in tokenizer.index_word:
print(idx, ":", tokenizer.index_word[idx])
if idx >= 10: break
src_input = tensor[:, :-1] # tensor에서 마지막 토큰을 잘라내서 소스 문장을 생성. 마지막 토큰은 <end>가 아니라 <pad>일 가능성이 높다.
tgt_input = tensor[:, 1:] # tensor에서 <start>를 잘라내서 타겟 문장을 생성.
print(src_input[0])
print(tgt_input[0])
# 데이터셋 구축
BUFFER_SIZE = len(src_input)
BATCH_SIZE = 256
steps_per_epoch = len(src_input) // BATCH_SIZE
VOCAB_SIZE = tokenizer.num_words + 1 # 0:<pad>를 포함하여 dictionary 갯수 + 1
dataset = tf.data.Dataset.from_tensor_slices((src_input, tgt_input)).shuffle(BUFFER_SIZE)
dataset = dataset.batch(BATCH_SIZE, drop_remainder=True)
dataset
데이터셋 생성 과정 요약
정규표현식을 이용한 corpus 생성
tf.keras.preprocessing.text.Tokenizer를 이용해 corpus를 텐서로 변환
tf.data.Dataset.from_tensor_slices()를 이용해 corpus 텐서를 tf.data.Dataset객체로 변환
(2) 모델 학습하기
이번에 만들 모델의 구조는 다음과 같다.
# 모델 생성
class TextGenerator(tf.keras.Model):
def __init__(self, vocab_size, embedding_size, hidden_size):
super(TextGenerator, self).__init__()
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_size)
self.rnn_1 = tf.keras.layers.LSTM(hidden_size, return_sequences=True)
self.rnn_2 = tf.keras.layers.LSTM(hidden_size, return_sequences=True)
self.linear = tf.keras.layers.Dense(vocab_size)
def call(self, x):
out = self.embedding(x)
out = self.rnn_1(out)
out = self.rnn_2(out)
out = self.linear(out)
return out
embedding_size = 256 # 워드 벡터의 차원 수
hidden_size = 1024 # LSTM Layer의 hidden 차원 수
model = TextGenerator(tokenizer.num_words + 1, embedding_size , hidden_size)
# 모델의 데이터 확인
for src_sample, tgt_sample in dataset.take(1): break
model(src_sample)
# 모델의 최종 출력 shape는 (256, 20, 7001)
# 256은 batch_size, 20은 squence_length, 7001은 단어의 갯수(Dense Layer 출력 차원 수)
model.summary() # sequence_length를 모르기 때문에 Output shape를 정확하게 모른다.
# 모델 학습
optimizer = tf.keras.optimizers.Adam()
loss = tf.keras.losses.SparseCategoricalCrossentropy(
from_logits=True,
reduction='none'
)
model.compile(loss=loss, optimizer=optimizer)
model.fit(dataset, epochs=30)
위의 코드에서 embbeding_size 는 워드 벡터의 차원 수를 나타내는 parameter로, 단어가 추상적으로 표현되는 크기를 말한다. 예를 들어 크기가 2라면 다음과 같이 표현할 수 있다.
차갑다: [0.0, 1.0]
뜨겁다: [1.0, 0.0]
미지근하다: [0.5, 0.5]
(3) 모델 평가하기
인공지능을 통한 작문은 수치적으로 평가할 수 없기 때문에 사람이 직접 평가를 해야 한다.
# 문장 생성 함수
def generate_text(model, tokenizer, init_sentence="<start>", max_len=20):
# 테스트를 위해서 입력받은 init_sentence도 텐서로 변환
test_input = tokenizer.texts_to_sequences([init_sentence])
test_tensor = tf.convert_to_tensor(test_input, dtype=tf.int64)
end_token = tokenizer.word_index["<end>"]
# 단어를 하나씩 생성
while True:
predict = model(test_tensor) # 입력받은 문장
predict_word = tf.argmax(tf.nn.softmax(predict, axis=-1), axis=-1)[:, -1] # 예측한 단어가 새로 생성된 단어
# 우리 모델이 새롭게 예측한 단어를 입력 문장의 뒤에 붙이기
test_tensor = tf.concat([test_tensor,
tf.expand_dims(predict_word, axis=0)], axis=-1)
# 우리 모델이 <end>를 예측했거나, max_len에 도달하지 않았다면 while 루프를 또 돌면서 다음 단어를 예측
if predict_word.numpy()[0] == end_token: break
if test_tensor.shape[1] >= max_len: break
generated = ""
# 생성된 tensor 안에 있는 word index를 tokenizer.index_word 사전을 통해 실제 단어로 하나씩 변환
for word_index in test_tensor[0].numpy():
generated += tokenizer.index_word[word_index] + " "
return generated # 최종 생성된 자연어 문장
# 생성 함수 실행
generate_text(model, tokenizer, init_sentence="<start> i love")
회고록
range(n)도 reverse() 함수가 먹힌다는 걸 오늘 알았다...
예시에 주어진 train data 갯수는 124960인걸 보면 총 데이터는 156200개인 것 같은데 아무리 전처리 단계에서 조건에 맞게 처리해도 168000개 정도가 나온다. 아무튼 일단 돌려본다.
문장의 길이가 최대 15라는 이야기는 <start>, <end>를 포함하여 15가 되어야 하는 것 같아서 tokenize했을 때 문장의 길이가 13 이하인 것만 corpus로 만들었다.
학습 회차 별 생성된 문장 input : <start> i love
1회차 '<start> i love you , i love you <end> '
2회차 '<start> i love you , i m not gonna crack <end> '
3회차'<start> i love you to be a shot , i m not a man <end> '
4회차 '<start> i love you , i m not stunning , i m a fool <end> '
batch_size를 각각 256, 512, 1024로 늘려서 진행했는데, 1epoch당 걸리는 시간이 74s, 62s, 59s 정도로 batch_size 배수 만큼의 차이는 없었다. batch_size가 배로 늘어나면 걸리느 시간도 당연히 반으로 줄어들 것이라 생각했는데 오산이었다.
1회차는 tokenize 했을 때 length가 15 이하인 것을 train_data로 사용하였다.
2, 3, 4회차는 tokenize 했을 때 length가 13 이하인 것을 train_data로 사용하였다.
3회차는 2회차랑 동일한 데이터에 padding 을 post에서 pre로 변경하였다. RNN에서는 뒤에 padding을 넣는 것 보다 앞쪽에 padding을 넣어주는 쪽이 마지막 결과에 paddind이 미치는 영향이 적어지기 때문에 더 좋은 성능을 낼 수 있다고 알고있기 때문이다.
근데 실제로는 pre padding 쪽이 loss가 더 크게 나왔다. 확인해보니 이론상으로는 pre padding이 성능이 더 좋지만 실제로는 post padding쪽이 성능이 더 잘 나와서 post padding을 많이 쓴다고 한다.
batch_size를 변경해서 pre padding을 한 번 더 돌려보았더니 같은 조건에서의 post padding 보다 loss가 높았고 문장도 부자연스러웠다. 앞으로는 post padding을 사용해야겠다.
소리는 진동으로 인한 공기의 압축을 이야기하며, 압축이 얼마나됐느냐는 파동(Wave)로 나타낼 수 있다.
소리에서 얻을 수 있는 물리량
진폭(Amplitude) → 강도(Intensity)
주파수(Frequency) →소리의 높낮이(Pitch)
위상(Phase) → 음색
(2) 오디오 데이터의 디지털화
연속적인 아날로그 신호 중 가장 단순한 형태인 sin 함수를 수식으로 표현하면 다음과 같다.
# 아날로그 신호의 Sampling
import numpy as np
import matplotlib.pyplot as plt
def single_tone(frequecy, sampling_rate=16000, duration=1):
t = np.linspace(0, duration, int(sampling_rate))
y = np.sin(2 * np.pi * frequecy * t)
return y
y = single_tone(400)
# 시각화
plt.plot(y[:41])
plt.show()
# 시각화
plt.stem(y[:41])
plt.show()
일반적으로 사용하는 주파수 영역대는 16kHz, 44.1kHz이며, 16kHz는 보통 Speech에서 많이 사용되고, 44.1kHz는 Music에서 많이 사용한다.
나이키스트-섀넌 표본화에 따르면 Sampling rate는 최대 주파수의 2배 이상을 표본화 주파수로 사용해야 aliasing을 방지할 수 있다고 한다.
연속적인 아날로그 신호는 표본화(Sampling), 양자화(Quantizing), 부호화(Encoding)을 거쳐 이진 디지털 신호(Binary Digital Signal)로 변환시켜 인식한다.
(3) Wave Data 분석
Bits per Sample(bps)
샘플 하나마다의 소리의 세기를 몇 비트로 저장했는지 나타내는 단위
값이 커질 수록 세기를 정확하게 저장 가능
16bits의 경우, 2^16인 65,536 단계로 표현 가능
Sampling Frequency
소리로부터 초당 샘플링한 횟수를 의미
샘플링은 나이퀴스트 샘플링 룰에 따라서 복원해야 할 신호 주파수 2배 이상으로 샘플링
가청 주파수 20 ~ 24kHz를 복원하기 위해 사용하며, 음원에서는 44.1kHz를 많이 사용
Channel
각 채널별로 샘플링된 데이터가 따로 저장
2채널은 왼쪽(L)과 오른쪽(R), 1채널은 왼쪽(L) 데이터만 있으며 재생시엔 LR 동시출력
(4) 데이터셋 살펴보기
npz 파일로 이뤄진 데이터이며, 각각 데이터는 "wav_vals", "label_vals"로 저장되어 있다.
# 데이터 불러오기
import numpy as np
import os
data_path = os.getenv("HOME")+'/aiffel/speech_recognition/data/speech_wav_8000.npz'
speech_data = np.load(data_path)
print("Wave data shape : ", speech_data["wav_vals"].shape)
print("Label data shape : ", speech_data["label_vals"].shape)
# 데이터 확인
import IPython.display as ipd
import random
# 데이터 선택
rand = random.randint(0, len(speech_data["wav_vals"]))
print("rand num : ", rand)
sr = 8000 # 1초동안 재생되는 샘플의 갯수
data = speech_data["wav_vals"][rand]
print("Wave data shape : ", data.shape)
print("label : ", speech_data["label_vals"][rand])
ipd.Audio(data, rate=sr)
Train/Test 데이터셋 구성하기
(1) Label Data 처리
# 구분해야 할 Data Label list
target_list = ['yes', 'no', 'up', 'down', 'left', 'right', 'on', 'off', 'stop', 'go']
label_value = target_list
label_value.append('unknown')
label_value.append('silence')
print('LABEL : ', label_value)
new_label_value = dict()
for i, l in enumerate(label_value):
new_label_value[l] = i
label_value = new_label_value
print('Indexed LABEL : ', new_label_value)
# Label Data indexing
temp = []
for v in speech_data["label_vals"]:
temp.append(label_value[v[0]])
label_data = np.array(temp)
label_data
(2) 데이터 분리
# 사이킷런의 split 함수를 이용하여 데이터 분리
from sklearn.model_selection import train_test_split
sr = 8000
train_wav, test_wav, train_label, test_label = train_test_split(speech_data["wav_vals"],
label_data,
test_size=0.1,
shuffle=True)
print(train_wav)
train_wav = train_wav.reshape([-1, sr, 1]) # add channel for CNN
test_wav = test_wav.reshape([-1, sr, 1])
# 데이터셋 확인
print("train data : ", train_wav.shape)
print("train labels : ", train_label.shape)
print("test data : ", test_wav.shape)
print("test labels : ", test_label.shape)
# Hyper-parameter Setting
batch_size = 32
max_epochs = 10
# the save point
checkpoint_dir = os.getenv('HOME')+'/aiffel/speech_recognition/models/wav'
checkpoint_dir
(3) Data Setting
tf.data.Dataset을 이용해서 데이터셋을 구성한다.
tf.data.Dataset.from_tensor_slices 함수에 return 받기 원하는 데이터를 튜플(data, label) 형태로 넣어서 사용할 수 있다.
map함수는 dataset이 데이터를 불러올 때 마다 동작시킬 데이터 전처리 함수를 매핑해준다.
# One-hot Encoding
def one_hot_label(wav, label):
label = tf.one_hot(label, depth=12)
return wav, label
# Dataset 함수 구성
import tensorflow as tf
# for train
train_dataset = tf.data.Dataset.from_tensor_slices((train_wav, train_label))
train_dataset = train_dataset.map(one_hot_label)
train_dataset = train_dataset.repeat().batch(batch_size=batch_size)
print(train_dataset)
# for test
test_dataset = tf.data.Dataset.from_tensor_slices((test_wav, test_label))
test_dataset = test_dataset.map(one_hot_label)
test_dataset = test_dataset.batch(batch_size=batch_size)
print(test_dataset)
Wave classification 모델 구현
(1) 모델 설계
audio는 1차원 데이터이기 때문에 데이터 형식에 맞게 모델을 구성해주어야 한다.
from tensorflow.keras import layers
input_tensor = layers.Input(shape=(sr, 1))
# 규정 상 삭제
output_tensor = layers.Dense(12)(x)
model_wav = tf.keras.Model(input_tensor, output_tensor)
model_wav.summary()
(2) Loss function
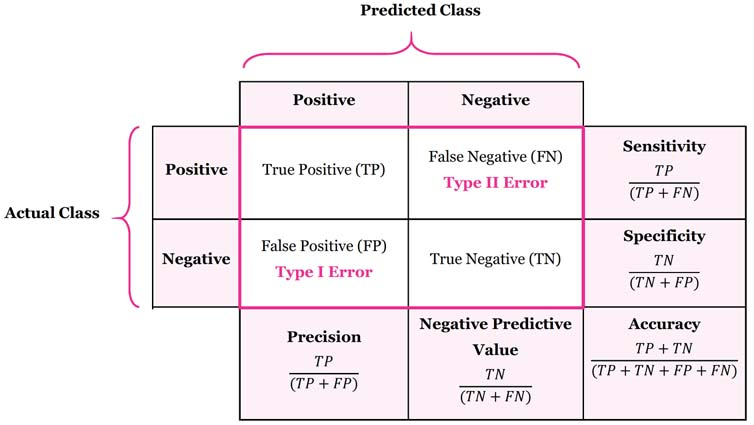
정답 label의 class가 12개이기 때문에 해당 class를 구분하기 위해서는 multi-class classification이 필요하며, 이를 수행하기 위한 Loss function으로는 Categorical Cross-Entropy loss function을 사용한다.
input_tensor = layers.Input(shape=(sr, 1))
# 규정 상 삭제
output_tensor = layers.Dense(12)(x)
model_wav_skip = tf.keras.Model(input_tensor, output_tensor)
model_wav_skip.summary()
# Optimization
optimizer=tf.keras.optimizers.Adam(1e-4)
model_wav_skip.compile(loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True),
optimizer=optimizer,
metrics=['accuracy'])
# checkpoint
checkpoint_dir = os.getenv('HOME')+'/aiffel/speech_recognition/models/wav_skip'
cp_callback = tf.keras.callbacks.ModelCheckpoint(checkpoint_dir,
save_weights_only=True,
monitor='val_loss',
mode='auto',
save_best_only=True,
verbose=1)
# 모델 학습
batch_size = 32 # 메모리가 남길래 batch_size 32에서 64로 변경 했었는데 터져서 다시 32로
history_wav_skip = model_wav_skip.fit(train_dataset, epochs=max_epochs,
steps_per_epoch=len(train_wav) // batch_size,
validation_data=test_dataset,
validation_steps=len(test_wav) // batch_size,
callbacks=[cp_callback]
)
# 시각화
import matplotlib.pyplot as plt
acc = history_wav_skip.history['accuracy']
val_acc = history_wav_skip.history['val_accuracy']
loss=history_wav_skip.history['loss']
val_loss=history_wav_skip.history['val_loss']
epochs_range = range(len(acc))
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
# 모델 평가
model_wav_skip.load_weights(checkpoint_dir)
results = model_wav_skip.evaluate(test_dataset)
# loss
print("loss value: {:.3f}".format(results[0]))
# accuracy
print("accuracy value: {:.4f}%".format(results[1]*100))
# 실제 확인 테스트
inv_label_value = {v: k for k, v in label_value.items()}
batch_index = np.random.choice(len(test_wav), size=1, replace=False)
batch_xs = test_wav[batch_index]
batch_ys = test_label[batch_index]
y_pred_ = model_wav_skip(batch_xs, training=False)
print("label : ", str(inv_label_value[batch_ys[0]]))
ipd.Audio(batch_xs.reshape(8000,), rate=8000)
# 예측 결과
if np.argmax(y_pred_) == batch_ys[0]:
print("y_pred: " + str(inv_label_value[np.argmax(y_pred_)]) + '(Correct!)')
else:
print("y_pred: " + str(inv_label_value[np.argmax(y_pred_)]) + '(Incorrect!)')
Spectrogram
waveform은 음성 데이터를 1차원 시계열 데이터로 해석하는 방법이다. 그러나 waveform은 많은 음원의 파형이 합성된 복합파이기 때문에 좀 더 뚜렷하게 다양한 파형들을 주파수 대역별로 나누어 해석할 수 있는 방법이 Spectrogram이다.
(1) 푸리에 변환 (Fourier transform)
푸리에 변환 식은 위와 같다. 그러나 이해하기 어려우니 아래 그림으로 보자.
(2) 오일러 공식
아래 cos과 sin은 주기와 주파수를 가지는 주기함수이다. 즉, 푸리에 변환은 입력 signal에 상관 없이 sin, cos과 같은 주기함수들의 합으로 항상 분해가 가능하다.
푸리에 변환이 끝나면 실수부와 허수부를 가지는 복소수가 얻어진다. 복소수의 절댓값은 Spectrum magnitude(주파수의 강도)라고 부르며, angle은 phase spectrum(주파수의 위상)이라고 부른다.
(3) STFT(Short Time Fourier Transform)
FFT(Fast Fourier Transform)는 시간의 흐름에 따라 신호의 주파수가 변했을 때, 어느 시간대에 주파수가 변하는지 모른다. 따라서 STFT는 시간의 길이를 나눠서 푸리에 변환을 한다.
N은 FFT size이고, Window를 얼마나 많은 주파수 밴드로 나누는 가를 의미한다.
Duration은 sampling rate를 window로 나눈 값이다. duration은 신호주기보다 5배 이상 길게 잡아야 한다. T(window)=5T(signal). ex) 440Hz의 window size = 5(1/440)
$\omega$(n)는 window 함수를 나타낸다. 일반적으로는 hann window 가 많이 쓰인다.
n은 window size다. window 함수에 들어가는 sample의 양으로 n이 작을수록 low-frequency resolution, high-time resolution을 가지게 되고, n이 길어지면 high-frequency, low-time resolution을 가지게 된다.
H는 hop size를 의미한다. window가 겹치는 사이즈이며, 일반적으로 1/4정도를 겹치게 한다.
(4) Spectrogram 이란?
wav 데이터를 해석하는 방법 중 하나로, 일정 시간동안 wav 데이터 안의 다양한 주파수들이 얼마나 포함되어 있는 지를 보여준다. STFT를 이용하여 Spectrogram을 그릴 수 있다.
# 필요한 library import
import numpy as np
import os
import librosa
import librosa.display
import IPython.display as ipd
import matplotlib.pyplot as plt
import random
# data load
data_path = os.getenv("HOME")+'/aiffel/speech_recognition/data/speech_wav_8000.npz'
speech_data = np.load(data_path)
# data list 확인
list(speech_data)
# wav to spectrum function
def wav2spec(wav, fft_size=258): # spectrogram shape을 맞추기위해서 size 변형
D = np.abs(librosa.stft(wav, n_fft=fft_size))
return D
# wav data를 spectrum data로 변환
temp = []
for i in speech_data['wav_vals']:
temp.append(wav2spec(i))
new_speech_data = np.array(temp)
# shape 확인
new_speech_data.shape
# 구분해야 할 Data Label list
target_list = ['yes', 'no', 'up', 'down', 'left', 'right', 'on', 'off', 'stop', 'go']
label_value = target_list
label_value.append('unknown')
label_value.append('silence')
print('LABEL : ', label_value)
new_label_value = dict()
for i, l in enumerate(label_value):
new_label_value[l] = i
label_value = new_label_value
print('Indexed LABEL : ', new_label_value)
# Label Data indexing
temp = []
for v in speech_data["label_vals"]:
temp.append(label_value[v[0]])
label_data = np.array(temp)
label_data
# 사이킷런의 split 함수를 이용하여 데이터 분리
from sklearn.model_selection import train_test_split
sr = 16380
# 메모리 부족으로 커널 자꾸 죽어서 train_size 줄여서 train 진행
train_wav, test_wav, train_label, test_label = train_test_split(new_speech_data,
label_data,
test_size=0.2,
shuffle=True)
print(train_wav)
train_wav = train_wav.reshape([-1, sr, 1]) # add channel for CNN
test_wav = test_wav.reshape([-1, sr, 1])
# 데이터셋 확인
print("train data : ", train_wav.shape)
print("train labels : ", train_label.shape)
print("test data : ", test_wav.shape)
print("test labels : ", test_label.shape)
# Hyper-parameter Setting
batch_size = 32 # 메모리 부족으로 32 이상 불가
max_epochs = 10
# the save point
checkpoint_dir = os.getenv('HOME')+'/aiffel/speech_recognition/models/wav'
checkpoint_dir
# One-hot Encoding
def one_hot_label(wav, label):
label = tf.one_hot(label, depth=12)
return wav, label
# Dataset 함수 구성
import tensorflow as tf
# for train
train_dataset = tf.data.Dataset.from_tensor_slices((train_wav, train_label))
train_dataset = train_dataset.map(one_hot_label)
train_dataset = train_dataset.repeat().batch(batch_size=batch_size)
print(train_dataset)
# for test
test_dataset = tf.data.Dataset.from_tensor_slices((test_wav, test_label))
test_dataset = test_dataset.map(one_hot_label)
test_dataset = test_dataset.batch(batch_size=batch_size)
print(test_dataset)
# 모델 설계
from tensorflow.keras import layers
input_tensor = layers.Input(shape=(sr, 1))
# 규정 상 삭제
output_tensor = layers.Dense(12)(x)
model_wav = tf.keras.Model(input_tensor, output_tensor)
model_wav.summary()
# optimizer 설정
optimizer=tf.keras.optimizers.Adam(1e-4)
model_wav.compile(loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True),
optimizer=optimizer,
metrics=['accuracy'])
# callback 설정
cp_callback = tf.keras.callbacks.ModelCheckpoint(checkpoint_dir,
save_weights_only=True,
monitor='val_loss',
mode='auto',
save_best_only=True,
verbose=1)
# 모델 훈련
history_wav = model_wav.fit(train_dataset, epochs=max_epochs,
steps_per_epoch=len(train_wav) // batch_size,
validation_data=test_dataset,
validation_steps=len(test_wav) // batch_size,
callbacks=[cp_callback]
)
# 훈련 결과 시각화
import matplotlib.pyplot as plt
acc = history_wav.history['accuracy']
val_acc = history_wav.history['val_accuracy']
loss=history_wav.history['loss']
val_loss=history_wav.history['val_loss']
epochs_range = range(len(acc))
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
# checkpoint callback 함수에서 저장한 weight 불러오기
model_wav.load_weights(checkpoint_dir)
# test 데이터와 비교
results = model_wav.evaluate(test_dataset)
# loss
print("loss value: {:.3f}".format(results[0]))
# accuracy
print("accuracy value: {:.4f}%".format(results[1]*100))
# 예측 데이터
inv_label_value = {v: k for k, v in label_value.items()}
batch_index = np.random.choice(len(test_wav), size=1, replace=False)
batch_xs = test_wav[batch_index]
batch_ys = test_label[batch_index]
y_pred_ = model_wav(batch_xs, training=False)
print("label : ", str(inv_label_value[batch_ys[0]]))
ipd.Audio(batch_xs.reshape(16380,), rate=16380)
# 실제 데이터가 맞는지 확인
if np.argmax(y_pred_) == batch_ys[0]:
print("y_pred: " + str(inv_label_value[np.argmax(y_pred_)]) + '(Correct!)')
else:
print("y_pred: " + str(inv_label_value[np.argmax(y_pred_)]) + '(Incorrect!)')
2D Layer 로 변환하여 학습해보기
# 필요한 Library import
import numpy as np
import os
import librosa
import IPython.display as ipd
import random
# data load
data_path = os.getenv("HOME")+'/aiffel/speech_recognition/data/speech_wav_8000.npz'
speech_data = np.load(data_path)
# data list 확인
list(speech_data)
# wav to spectrum function
def wav2spec(wav, fft_size=258): # spectrogram shape을 맞추기위해서 size 변형
D = np.abs(librosa.stft(wav, n_fft=fft_size))
return D
# wav data를 spectrum data로 변환
temp = []
for i in speech_data['wav_vals']:
temp.append(wav2spec(i))
new_speech_data = np.array(temp)
# shape 확인
new_speech_data.shape
# 구분해야 할 Data Label list
target_list = ['yes', 'no', 'up', 'down', 'left', 'right', 'on', 'off', 'stop', 'go']
label_value = target_list
label_value.append('unknown')
label_value.append('silence')
print('LABEL : ', label_value)
new_label_value = dict()
for i, l in enumerate(label_value):
new_label_value[l] = i
label_value = new_label_value
print('Indexed LABEL : ', new_label_value)
# Label Data indexing
temp = []
for v in speech_data["label_vals"]:
temp.append(label_value[v[0]])
label_data = np.array(temp)
label_data
# 사이킷런의 split 함수를 이용하여 데이터 분리
from sklearn.model_selection import train_test_split
train_wav, test_wav, train_label, test_label = train_test_split(new_speech_data,
label_data,
test_size=0.2,
shuffle=True)
print(train_wav)
# 데이터셋 확인
print("train data : ", train_wav.shape)
print("train labels : ", train_label.shape)
print("test data : ", test_wav.shape)
print("test labels : ", test_label.shape)
# Hyper-parameter Setting
batch_size = 32
max_epochs = 10
# the save point
checkpoint_dir = os.getenv('HOME')+'/aiffel/speech_recognition/models/wav'
checkpoint_dir
# One-hot Encoding
def one_hot_label(wav, label):
label = tf.one_hot(label, depth=12)
return wav, label
# Dataset 함수 구성
import tensorflow as tf
# for train
train_dataset = tf.data.Dataset.from_tensor_slices((train_wav, train_label))
train_dataset = train_dataset.map(one_hot_label)
train_dataset = train_dataset.repeat().batch(batch_size=batch_size)
print(train_dataset)
# for test
test_dataset = tf.data.Dataset.from_tensor_slices((test_wav, test_label))
test_dataset = test_dataset.map(one_hot_label)
test_dataset = test_dataset.batch(batch_size=batch_size)
print(test_dataset)
# 모델 설계
from tensorflow.keras import layers
input_tensor = layers.Input(shape=(130, 126, 1))
# 규정 상 삭제
output_tensor = layers.Dense(12)(x)
model_wav = tf.keras.Model(input_tensor, output_tensor)
model_wav.summary()
# optimizer 설정
optimizer=tf.keras.optimizers.Adam(1e-4)
model_wav.compile(loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True),
optimizer=optimizer,
metrics=['accuracy'])
# callback 설정
cp_callback = tf.keras.callbacks.ModelCheckpoint(checkpoint_dir,
save_weights_only=True,
monitor='val_loss',
mode='auto',
save_best_only=True,
verbose=1)
# 모델 훈련
history_wav = model_wav.fit(train_dataset, epochs=max_epochs,
steps_per_epoch=len(train_wav) // batch_size,
validation_data=test_dataset,
validation_steps=len(test_wav) // batch_size,
callbacks=[cp_callback]
)
# 훈련 결과 시각화
acc = history_wav.history['accuracy']
val_acc = history_wav.history['val_accuracy']
loss=history_wav.history['loss']
val_loss=history_wav.history['val_loss']
epochs_range = range(len(acc))
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
# checkpoint callback 함수에서 저장한 weight 불러오기
model_wav.load_weights(checkpoint_dir)
# test 데이터와 비교
results = model_wav.evaluate(test_dataset)
# loss
print("loss value: {:.3f}".format(results[0]))
# accuracy
print("accuracy value: {:.4f}%".format(results[1]*100))
# 예측 데이터
inv_label_value = {v: k for k, v in label_value.items()}
batch_index = np.random.choice(len(test_wav), size=1, replace=False)
batch_xs = test_wav[batch_index]
batch_ys = test_label[batch_index]
y_pred_ = model_wav(batch_xs, training=False)
print("label : ", str(inv_label_value[batch_ys[0]]))
ipd.Audio(batch_xs.reshape(16380,), rate=16380)
# 실제 데이터가 맞는지 확인
if np.argmax(y_pred_) == batch_ys[0]:
print("y_pred: " + str(inv_label_value[np.argmax(y_pred_)]) + '(Correct!)')
else:
print("y_pred: " + str(inv_label_value[np.argmax(y_pred_)]) + '(Incorrect!)')
회고록
예전에 음악에 관심이 많았을 때 더 좋은 음질로 노래를 듣기 위해서 공부했을 때의 지식이 과제를 해결하는데 많은 도움이 된 것 같다.
Wave Classification은 아무래도 데이터가 많아서 그런지 Image Classification이나 NLP보다 훨씬 parameter도 많고 시간도 오래 걸리는 것 같다.
skip-connection 모델을 알고 있다는 전제하의 학습 노드였는데 사실 잘 몰라서 조금 더 찾아봐야 할 것 같다.
skip-connection 을 이용하니까 overfitting은 줄어들은 것 같지만 실제로 정확도에는 큰 차이가 없는 것 같다.
LMS 할 땐 batch_size를 32로 해도 메모리가 남길래 64로 변경해서 진행했었는데, Spectrum으로 변경하니까 parameter 수가 훨씬 많아져서 그런지 batch_size를 32로 조정해도 커널이 자꾸 죽어서 train_size를 줄이는 방향으로 겨우 model을 train시켰다.
Spectrum을 1D-array로 reshape하여 train한 결과는 약 91%의 정확도가 나왔다!
1D-array에 Skip-connect을 적용해봤더니 적용하기 전과 큰 차이는 없는 것 같다.
2D-array로 reshape하여 2D-Conv Layer로 model을 train했더니 무려 96%의 정확도가 나왔다! 확실히 차원이 올라갈 수록 특징을 잡아내는 능력은 향상되는 것 같다. 대신 parameter의 수가 어마어마해져서 1epoch당 거의 5분 이상 걸려서 10epoch을 모두 진행하는 데 거의 1시간 정도가 걸렸다.
1D-array보다 2D-array쪽이 epoch을 거듭할 수록 train_loss와 val_loss의 차이가 벌어지는 정도가 덜했다. Overfitting이 덜하다는 의미인 것 같다. 실제로 결과도 더 좋았다.
SNS 등에서 얻을 수 있는 광범위한 분량의 텍스트 데이터는 소비자들의 개인적, 감성적 반응이 잘 담겨있을 뿐만 아니라 실시간 트렌드를 빠르게 반영할 수 있는 데이터이다.
텍스트 감성분석 접근법
기계학습 기반
감성사전 기반
사전 기반의 감성분석이 기계학습 기반 접근법 대비 가지는 한계점
분석 대상에 따라 같은 단어지만 반대의 극성을 가지는 가능성에 대응하기 어려움
긍정과 부정의 원인이 되는 대상의 속성 기반 감정분석이 어려움
텍스트에 감성분석 기법을 적용하면 데이터를 정형화하여 유용한 의사결정 보조자료로 사용 가능
자연어 처리의 가장 대표적인 기법 : 워드 임베딩(Word Embedding)
(2) 텍스트 데이터의 특징
텍스트는 숫자 행렬로 변환할 필요가 없다.
텍스트에는 입력 순서가 중요하다.
(3) 텍스트를 숫자로 표현하는 방법
# 처리해야 할 문장을 파이썬 리스트에 옮기기
sentences=['i am hungry', 'i like apple', 'i am so happy']
# 파이썬 split() 메소드를 이용해 단어 단위로 문장을 쪼개기
word_list = 'i am hungry'.split()
print(word_list)
index_to_word={} # 빈 딕셔너리를 만들어서
# 단어들을 하나씩 채워보자. 순서는 중요하지 않다.
# <BOS>, <PAD>, <UNK>는 관례적으로 딕셔너리 맨 앞에 넣어준다
index_to_word[0]='<PAD>' # 패딩용 단어
index_to_word[1]='<BOS>' # 문장의 시작지점
index_to_word[2]='<UNK>' # 사전에 없는(Unknown) 단어
index_to_word[3]='i'
index_to_word[4]='like'
index_to_word[5]='hungry'
index_to_word[6]='so'
index_to_word[7]='apple'
index_to_word[8]='happy'
print(index_to_word)
word_to_index={word:index for index, word in index_to_word.items()}
print(word_to_index)
# 문장 1개를 활용할 딕셔너리와 함께 주면, 단어 인덱스 리스트로 변환해 주는 함수
# 단, 모든 문장은 <BOS>로 시작하는 것으로 합니다.
def get_encoded_sentence(sentence, word_to_index):
return [word_to_index['<BOS>']]+[word_to_index[word] if word in word_to_index else word_to_index['<UNK>'] for word in sentence.split()]
# 여러 개의 문장 리스트를 한꺼번에 숫자 텐서로 encode해 주는 함수
def get_encoded_sentences(sentences, word_to_index):
return [get_encoded_sentence(sentence, word_to_index) for sentence in sentences]
# 숫자 벡터로 encode된 문장을 원래대로 decode하는 함수
def get_decoded_sentence(encoded_sentence, index_to_word):
return ' '.join(index_to_word[index] if index in index_to_word else '<UNK>' for index in encoded_sentence[1:]) #[1:]를 통해 <BOS>를 제외
# 여러개의 숫자 벡터로 encode된 문장을 한꺼번에 원래대로 decode하는 함수
def get_decoded_sentences(encoded_sentences, index_to_word):
return [get_decoded_sentence(encoded_sentence, index_to_word) for encoded_sentence in encoded_sentences]
# raw_inputs의 문장의 길이를 PAD를 이용하여 동일하게 만들기
raw_inputs = keras.preprocessing.sequence.pad_sequences(raw_inputs,
value=word_to_index['<PAD>'],
padding='post',
maxlen=5)
print(raw_inputs)
# Embedding
import numpy as np
import tensorflow as tf
vocab_size = len(word_to_index) # 위 예시에서 딕셔너리에 포함된 단어 개수는 10
word_vector_dim = 4 # 그림과 같이 4차원의 워드벡터를 가정
embedding = tf.keras.layers.Embedding(input_dim=vocab_size, output_dim=word_vector_dim, mask_zero=True)
# keras.preprocessing.sequence.pad_sequences를 통해 word vector를 모두 일정길이로 맞춰주어야
# embedding 레이어의 input이 될 수 있음에 주의
raw_inputs = np.array(get_encoded_sentences(sentences, word_to_index))
raw_inputs = keras.preprocessing.sequence.pad_sequences(raw_inputs,
value=word_to_index['<PAD>'],
padding='post',
maxlen=5)
output = embedding(raw_inputs)
print(output)
(5) 시퀀스 데이터를 다루는 RNN(Recurrnet Neural Network)
# RNN 모델을 사용하여 텍스트 데이터 처리
model = keras.Sequential()
model.add(keras.layers.Embedding(vocab_size, word_vector_dim, input_shape=(None,)))
model.add(keras.layers.LSTM(8)) # 가장 널리 쓰이는 RNN인 LSTM 레이어를 사용
model.add(keras.layers.Dense(8, activation='relu'))
model.add(keras.layers.Dense(1, activation='sigmoid'))
model.summary()
텍스트를 처리하기 위해 RNN이 아니라 1-D CNN을 사용할 수도 있다. 텍스트는 시퀀스 데이터이기 때문에 1-D CNN 으로 문장 전체를 한꺼번에 한 방향으로 스캔하여 발견되는 특징을 추출해서 문장을 분류하는 방식으로 사용된다. CNN 계열은 RNN 계열보다 병렬처리가 효율적이기 때문에 학습 속도도 훨씬 빠르게 진행된다는 장점이 있다.
# 1DConv 모델을 사용하여 텍스트 데이터 처리
model = keras.Sequential()
model.add(keras.layers.Embedding(vocab_size, word_vector_dim, input_shape=(None,)))
model.add(keras.layers.Conv1D(16, 7, activation='relu'))
model.add(keras.layers.MaxPooling1D(5))
model.add(keras.layers.Conv1D(16, 7, activation='relu'))
model.add(keras.layers.GlobalMaxPooling1D())
model.add(keras.layers.Dense(8, activation='relu'))
model.add(keras.layers.Dense(1, activation='sigmoid'))
model.summary()
아주 간단히는 GlobalMaxPooling1D() 레이어 하나만 사용하는 방법도 생각할 수 있다. 이 방식은 전체 문장 중 가장 중요한 단 하나의 특징만을 추출해서 문장의 긍정/부정을 평가하는 방식이다.
# GlobalMaxPooling1D 모델을 사용하여 텍스트 데이터 처리
model = keras.Sequential()
model.add(keras.layers.Embedding(vocab_size, word_vector_dim, input_shape=(None,)))
model.add(keras.layers.GlobalMaxPooling1D())
model.add(keras.layers.Dense(8, activation='relu'))
model.add(keras.layers.Dense(1, activation='sigmoid'))
model.summary()
이 외에도 1-D CNN과 RNN을 섞어 쓴다거나, FFN(FeedForword Network) 레이어만으로 구성하거나, Transformer 레이어를 쓰는 등 다양한 시도를 해볼 수 있다.
IMDB 영화리뷰 감성분석
(1) IMDB 데이터셋 분석
IMDB Large Movie Dataset은 50000개의 영어로 작성된 영화 리뷰 텍스트로 구성되어 있으며, 긍정은 1, 부정은 0의 라벨이 달려있다. 이 중 25000개가 훈련용 데이터, 나머지 25000개를 테스트 데이터로 사용하도록 지정되어 있다.
import tensorflow as tf
from tensorflow import keras
import numpy as np
print(tf.__version__)
imdb = keras.datasets.imdb
# IMDB 데이터셋 다운로드
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=10000)
print("훈련 샘플 개수: {}, 테스트 개수: {}".format(len(x_train), len(x_test)))
# 데이터 확인
print(x_train[0]) # 1번째 리뷰데이터
print('라벨: ', y_train[0]) # 1번째 리뷰데이터의 라벨
print('1번째 리뷰 문장 길이: ', len(x_train[0]))
# word_index 가져오기
word_to_index = imdb.get_word_index()
index_to_word = {index:word for word, index in word_to_index.items()}
print(index_to_word[1]) # 'the' 가 출력
print(word_to_index['the']) # 1 이 출력
# decoding
print(get_decoded_sentence(x_train[0], index_to_word))
print('라벨: ', y_train[0]) # 1번째 리뷰데이터의 라벨
# 텍스트데이터 문장길이의 리스트를 생성한 후
total_data_text = list(x_train) + list(x_test)
# 문장길이의 평균값, 최대값, 표준편차를 계산
num_tokens = [len(tokens) for tokens in total_data_text]
num_tokens = np.array(num_tokens)
print('문장길이 평균 : ', np.mean(num_tokens))
print('문장길이 최대 : ', np.max(num_tokens))
print('문장길이 표준편차 : ', np.std(num_tokens))
# 예를들어, 최대 길이를 (평균 + 2*표준편차)로 한다면,
max_tokens = np.mean(num_tokens) + 2 * np.std(num_tokens)
maxlen = int(max_tokens)
print('pad_sequences maxlen : ', maxlen)
print('전체 문장의 {}%가 maxlen 설정값 이내에 포함됩니다. '.format(np.sum(num_tokens < max_tokens) / len(num_tokens)))
# padding
x_train = keras.preprocessing.sequence.pad_sequences(x_train,
value=word_to_index["<PAD>"],
padding='post', # 혹은 'pre'
maxlen=maxlen)
x_test = keras.preprocessing.sequence.pad_sequences(x_test,
value=word_to_index["<PAD>"],
padding='post', # 혹은 'pre'
maxlen=maxlen)
print(x_train.shape)
(2) 딥러닝 모델 설계와 훈련
vocab_size = 10000 # 어휘 사전의 크기입니다(10,000개의 단어)
word_vector_dim = 16 # 워드 벡터의 차원수 (변경가능한 하이퍼파라미터)
# model 설계
model = keras.Sequential()
model.add(keras.layers.Embedding(vocab_size, word_vector_dim, input_shape=(None,)))
model.add(keras.layers.LSTM(8)) # 가장 널리 쓰이는 RNN인 LSTM 레이어를 사용
model.add(keras.layers.Dense(8, activation='relu'))
model.add(keras.layers.Dense(1, activation='sigmoid')) # 최종 출력은 긍정/부정을 나타내는 1dim
model.summary()
# validation set 10000건 분리
x_val = x_train[:10000]
y_val = y_train[:10000]
# validation set을 제외한 나머지 15000건
partial_x_train = x_train[10000:]
partial_y_train = y_train[10000:]
print(partial_x_train.shape)
print(partial_y_train.shape)
# 모델 학습
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
epochs=20
history = model.fit(partial_x_train,
partial_y_train,
epochs=epochs,
batch_size=512,
validation_data=(x_val, y_val),
verbose=1)
# 모델 평가
results = model.evaluate(x_test, y_test, verbose=2)
print(results)
# 모델의 fitting 과정 중의 정보들이 history 변수에 저장
history_dict = history.history
print(history_dict.keys()) # epoch에 따른 그래프를 그려볼 수 있는 항목들
# 도식화 Training and Validation loss
import matplotlib.pyplot as plt
acc = history_dict['accuracy']
val_acc = history_dict['val_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
# "bo"는 "파란색 점"입니다
plt.plot(epochs, loss, 'bo', label='Training loss')
# b는 "파란 실선"입니다
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
# Training and Validation accuracy
plt.clf() # 그림을 초기화
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
(3) Word2Vec의 적용
pip install gensim : 워드벡터를 다루는데 유용한 패키지
# 임베딩 레이어 생성
embedding_layer = model.layers[0]
weights = embedding_layer.get_weights()[0]
print(weights.shape) # shape: (vocab_size, embedding_dim)
# 학습한 Embedding 파라미터를 저장
import os
word2vec_file_path = os.getenv('HOME')+'/aiffel/sentiment_classification/word2vec.txt'
f = open(word2vec_file_path, 'w')
f.write('{} {}\n'.format(vocab_size-4, word_vector_dim)) # 몇개의 벡터를 얼마 사이즈로 기재할지
# 단어 개수(에서 특수문자 4개는 제외하고)만큼의 워드 벡터를 파일에 기록
vectors = model.get_weights()[0]
for i in range(4,vocab_size):
f.write('{} {}\n'.format(index_to_word[i], ' '.join(map(str, list(vectors[i, :])))))
f.close()
# gensim 에서 제공하는 패키지를 이용하여 임베딩 파라미터를 word vector로 사용
from gensim.models.keyedvectors import Word2VecKeyedVectors
word_vectors = Word2VecKeyedVectors.load_word2vec_format(word2vec_file_path, binary=False)
vector = word_vectors['computer']
vector
# 단어 유사도 분석
word_vectors.similar_by_word("love")
감성분류 태스크를 잠깐 학습한 것 만으로는 워드벡터가 유의미하게 학습되기 어려운 것 같다. 이 정도의 훈련 데이터로는 워드벡터를 정교하게 학습시키기 어렵다고 한다. 따라서 구글에서 제공하는 Word2Vec라는 사전 학습된 워드 임베딩 모델을 활용해보자. 다운로드
# 모델 불러오기
from gensim.models import KeyedVectors
word2vec_path = os.getenv('HOME')+'/aiffel/sentiment_classification/GoogleNews-vectors-negative300.bin.gz'
word2vec = KeyedVectors.load_word2vec_format(word2vec_path, binary=True, limit=None)
vector = word2vec['computer']
vector # 300dim의 워드 벡터. limit으로 조건을 주어 로딩 가능
# 단어 유사도 분석
word2vec.similar_by_word("love")
# 임베딩 레이어 변경
vocab_size = 10000 # 어휘 사전의 크기입니다(10,000개의 단어)
word_vector_dim = 300 # 워드 벡터의 차원수 (변경가능한 하이퍼파라미터)
embedding_matrix = np.random.rand(vocab_size, word_vector_dim)
# embedding_matrix에 Word2Vec 워드벡터를 단어 하나씩마다 차례차례 카피
for i in range(4,vocab_size):
if index_to_word[i] in word2vec:
embedding_matrix[i] = word2vec[index_to_word[i]]
# 모델 설계
from tensorflow.keras.initializers import Constant
vocab_size = 10000 # 어휘 사전의 크기입니다(10,000개의 단어)
word_vector_dim = 300 # 워드 벡터의 차원수 (변경가능한 하이퍼파라미터)
# 모델 구성
model = keras.Sequential()
model.add(keras.layers.Embedding(vocab_size,
word_vector_dim,
embeddings_initializer=Constant(embedding_matrix), # 카피한 임베딩을 여기서 활용
input_length=maxlen,
trainable=True)) # trainable을 True로 주면 Fine-tuning
model.add(keras.layers.Conv1D(16, 7, activation='relu'))
model.add(keras.layers.MaxPooling1D(5))
model.add(keras.layers.Conv1D(16, 7, activation='relu'))
model.add(keras.layers.GlobalMaxPooling1D())
model.add(keras.layers.Dense(8, activation='relu'))
model.add(keras.layers.Dense(1, activation='sigmoid'))
model.summary()
# 모델 학습
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
epochs=20
history = model.fit(partial_x_train,
partial_y_train,
epochs=epochs,
batch_size=512,
validation_data=(x_val, y_val),
verbose=1)
# 모델 평가
results = model.evaluate(x_test, y_test, verbose=2)
print(results)이버 영화리뷰 감성분석 도전하기
(1) 데이터 준비와 확인
import pandas as pd
import urllib.request
%matplotlib inline
import matplotlib.pyplot as plt
import re
from konlpy.tag import Okt
from tensorflow import keras
from tensorflow.keras.preprocessing.text import Tokenizer
import numpy as np
from tensorflow.keras.preprocessing.sequence import pad_sequences
from collections import Counter
import os
# 데이터 읽기
train_data = pd.read_table('~/aiffel/sentiment_classification/ratings_train.txt')
test_data = pd.read_table('~/aiffel/sentiment_classification/ratings_test.txt')
train_data.head()
(2) 데이터 로더 구성
data_loader를 직접 만들어보자. data_loader에서는 다음을 수행해야 한다.
from konlpy.tag import Mecab
tokenizer = Mecab()
stopwords = ['의','가','이','은','들','는','좀','잘','걍','과','도','를','으로','자','에','와','한','하다']
# load_data 함수
def load_data(train_data, test_data, num_words=10000):
train_data.drop_duplicates(subset=['document'], inplace=True)
train_data = train_data.dropna(how = 'any')
test_data.drop_duplicates(subset=['document'], inplace=True)
test_data = test_data.dropna(how = 'any')
x_train = []
for sentence in train_data['document']:
temp_x = tokenizer.morphs(sentence) # 토큰화
temp_x = [word for word in temp_x if word not in stopwords] # 불용어 제거
x_train.append(temp_x)
x_test = []
for sentence in test_data['document']:
temp_x = tokenizer.morphs(sentence) # 토큰화
temp_x = [word for word in temp_x if word not in stopwords] # 불용어 제거
x_test.append(temp_x)
words = np.concatenate(x_train).tolist()
counter = Counter(words)
counter = counter.most_common(10000-4)
vocab = ['<PAD>', '<BOS>', '<UNK>', '<UNUSED>'] + [key for key, _ in counter]
word_to_index = {word:index for index, word in enumerate(vocab)}
def wordlist_to_indexlist(wordlist):
return [word_to_index[word] if word in word_to_index else word_to_index['<UNK>'] for word in wordlist]
x_train = list(map(wordlist_to_indexlist, x_train))
x_test = list(map(wordlist_to_indexlist, x_test))
return x_train, np.array(list(train_data['label'])), x_test, np.array(list(test_data['label'])), word_to_index
x_train, y_train, x_test, y_test, word_to_index = load_data(train_data, test_data)
index_to_word = {index:word for word, index in word_to_index.items()}
# 문장 1개를 활용할 딕셔너리와 함께 주면, 단어 인덱스 리스트 벡터로 변환해 주는 함수
# 단, 모든 문장은 <BOS>로 시작
def get_encoded_sentence(sentence, word_to_index):
return [word_to_index['<BOS>']]+[word_to_index[word] if word in word_to_index else word_to_index['<UNK>'] for word in sentence.split()]
# 여러 개의 문장 리스트를 한꺼번에 단어 인덱스 리스트 벡터로 encode해 주는 함수
def get_encoded_sentences(sentences, word_to_index):
return [get_encoded_sentence(sentence, word_to_index) for sentence in sentences]
# 숫자 벡터로 encode된 문장을 원래대로 decode하는 함수
def get_decoded_sentence(encoded_sentence, index_to_word):
return ' '.join(index_to_word[index] if index in index_to_word else '<UNK>' for index in encoded_sentence[1:]) #[1:]를 통해 <BOS>를 제외
# 여러개의 숫자 벡터로 encode된 문장을 한꺼번에 원래대로 decode하는 함수
def get_decoded_sentences(encoded_sentences, index_to_word):
return [get_decoded_sentence(encoded_sentence, index_to_word) for encoded_sentence in encoded_sentences]
print("훈련 샘플 개수: {}, 테스트 개수: {}".format(len(x_train), len(x_test)))
# decoding
print(get_decoded_sentence(x_train[0], index_to_word))
print('라벨: ', y_train[0]) # 1번째 리뷰데이터의 라벨
# 텍스트데이터 문장길이의 리스트를 생성한 후
total_data_text = list(x_train) + list(x_test)
# 문장길이의 평균값, 최대값, 표준편차를 계산
num_tokens = [len(tokens) for tokens in total_data_text]
num_tokens = np.array(num_tokens)
print('문장길이 평균 : ', np.mean(num_tokens))
print('문장길이 최대 : ', np.max(num_tokens))
print('문장길이 표준편차 : ', np.std(num_tokens))
plt.clf()
plt.hist([len(s) for s in total_data_text], bins=100)
plt.xlabel('length of samples')
plt.ylabel('number of samples')
plt.show()
# 예를들어, 최대 길이를 (평균 + 2*표준편차)로 가정
max_tokens = np.mean(num_tokens) + 2 * np.std(num_tokens)
maxlen = int(max_tokens)
print('pad_sequences maxlen : ', maxlen)
print('전체 문장의 {}%가 maxlen 설정값 이내에 포함됩니다. '.format(np.sum(num_tokens < max_tokens) / len(num_tokens)))
# padding
x_train = keras.preprocessing.sequence.pad_sequences(x_train,
value=word_to_index["<PAD>"],
padding='pre', # 혹은 'pre'
maxlen=maxlen)
x_test = keras.preprocessing.sequence.pad_sequences(x_test,
value=word_to_index["<PAD>"],
padding='pre', # 혹은 'pre'
maxlen=maxlen)
print(x_train.shape)
vocab_size = 10000 # 어휘 사전의 크기입니다(10,000개의 단어)
word_vector_dim = 32 # 워드 벡터의 차원수 (변경가능한 하이퍼파라미터)
# 모델 설계
model = keras.Sequential()
model.add(keras.layers.Embedding(vocab_size, word_vector_dim, input_shape=(None,)))
model.add(keras.layers.LSTM(16))
model.add(keras.layers.Dense(8, activation='relu'))
model.add(keras.layers.Dense(1, activation='sigmoid'))
model.summary()
# validation set 10000건 분리
x_val = x_train[:10000]
y_val = y_train[:10000]
# validation set을 제외한 나머지 15000건
partial_x_train = x_train[10000:]
partial_y_train = y_train[10000:]
print(partial_x_train.shape)
print(partial_y_train.shape)
# 모델 학습
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
epochs=10
history = model.fit(partial_x_train,
partial_y_train,
epochs=epochs,
batch_size=512,
validation_data=(x_val, y_val),
verbose=1)
# 모델 평가
results = model.evaluate(x_test, y_test, verbose=2)
print(results)
# 모델의 fitting 과정 중의 정보들이 history 변수에 저장
history_dict = history.history
print(history_dict.keys()) # epoch에 따른 그래프를 그려볼 수 있는 항목들
acc = history_dict['accuracy']
val_acc = history_dict['val_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
# "bo"는 "파란색 점"
plt.plot(epochs, loss, 'bo', label='Training loss')
# b는 "파란 실선"
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
# Training and Validation accuracy
plt.clf() # 그림을 초기화
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
(3) gensim을 이용하여 사전학습 된 모델 이용하기
Pre-trained된 Word2Vec Embedding을 이용하여 정확도를 올려보자.
import gensim
word2vec_path = os.getenv('HOME')+'/aiffel/sentiment_classification/ko.bin'
pre_word2vec = gensim.models.Word2Vec.load(word2vec_path)
vector = pre_word2vec.wv.most_similar("강아지")
vector
pre_word2vec['강아지'].shape
# 임베딩 레이어 변경
vocab_size = 10000 # 어휘 사전의 크기입니다(10,000개의 단어)
word_vector_dim = 200 # 워드 벡터의 차원수 (변경가능한 하이퍼파라미터)
embedding_matrix = np.random.rand(vocab_size, word_vector_dim)
# embedding_matrix에 Word2Vec 워드벡터를 단어 하나씩마다 차례차례 카피
for i in range(4,vocab_size):
if index_to_word[i] in pre_word2vec:
embedding_matrix[i] = pre_word2vec[index_to_word[i]]
# 모델 설계
from tensorflow.keras.initializers import Constant
vocab_size = 10000 # 어휘 사전의 크기입니다(10,000개의 단어)
word_vector_dim = 200 # 워드 벡터의 차원수 (변경가능한 하이퍼파라미터)
# 모델 구성
model = keras.Sequential()
model.add(keras.layers.Embedding(vocab_size,
word_vector_dim,
embeddings_initializer=Constant(embedding_matrix), # 카피한 임베딩을 여기서 활용
input_length=maxlen,
trainable=True)) # trainable을 True로 주면 Fine-tuning
model.add(keras.layers.LSTM(16))
model.add(keras.layers.Dense(8, activation='relu'))
model.add(keras.layers.Dense(1, activation='sigmoid'))
model.summary()
# 모델 학습
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
epochs=15
history = model.fit(partial_x_train,
partial_y_train,
epochs=epochs,
batch_size=4096,
validation_data=(x_val, y_val),
verbose=1)
# 모델 평가
results = model.evaluate(x_test, y_test, verbose=2)
print(results)
# 모델의 fitting 과정 중의 정보들이 history 변수에 저장
history_dict = history.history
print(history_dict.keys()) # epoch에 따른 그래프를 그려볼 수 있는 항목들
# 도식화 Training and Validation loss
import matplotlib.pyplot as plt
acc = history_dict['accuracy']
val_acc = history_dict['val_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
# "bo"는 "파란색 점"입니다
plt.plot(epochs, loss, 'bo', label='Training loss')
# b는 "파란 실선"입니다
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
# Training and Validation accuracy
plt.clf() # 그림을 초기화합니다
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
회고록
stateful과 stateless에 대해 몰랐을 땐 손님이 계속 이전의 선택지를 이야기 해주기 때문에 손님이 state를 결정한다고 생각했는데 직원이 기억하지 못하여 손님이 선택지를 이야기해주는 것이어서 state를 결정하는 것은 직원이었다.
RNN 활용 시 pad_sequences의 padding 방식은 post와 pre중 post가 추후 0으로 padding된 부분의 연산을 수행하지 않아도 될 것 같아서 post 방식이 유리할 것으로 예상했지만, 실제로는 RNN의 가장 마지막 입력이 최종 state 값에 가장 영향을 많이 미치기 때문에 마지막 입력이 무의미한 padding으로 채워지는 것은 비효율 적이라고 한다. 따라서 pre가 훨씬 유리하며 10% 이상의 테스트 성능 차이를 보인다고 한다.
정확도를 85%로 올리기 위해 LSTM, 1-D Conv, GlobalMaxPooling 등 다양한 모델에서 각종 Hyperparameter를 이것저것 변화시켜 보았지만 85%는 넘을 수가 없었다. 결국 Word2Vec를 이용하여 Pre-Trained된 Word2Vec Embedding 모델을 사용하였지만 이 모델에서도 유일하게 LSTM 만 85%를 아슬아슬하게 넘을 수 있었다.
아직 머신러닝이나 딥러닝의 모델을 설계하는 정확한 이해 없이 정확도를 올리려고 하니까 너무 어려운 것 같다. 물론 아직 배우기 시작하는 단계라서 어쩔 수 없다고 생각은 하지만 모델 설계에 대한 공부도 따로 해야겠다.
일단 이미지 인식과 자연어 처리 둘 다 경험은 해봤으니 앞으로 어떤 분야에 집중을 할지 고민해봐야겠다.
카메라앱 만들기를 통해 동영상 처리, 검출, 키포인트 추정, 추적, 카메라 원근 의 기술을 다룬다.
간단한 스티커부터 시작해서 각도 변화가 가능하고 거리 변화에 강건한 스티커 까지 만들 수 있다.
얼굴인식 카메라의 흐름을 이해할 수 있다.
dlib 라이브러리를 사용할 수 있다.
이미지 배열의 인덱싱 예외 처리를 할 수 있다.
1. 카메라 스티커 앱 만들기
스티커를 세밀하고 자연스럽게 적용하기 위해서는 눈, 코, 입, 귀와 같은 얼굴 각각의 위치를 아는 것이 중요하다. 이들을 찾아내는 기술을 랜드마크(landmark)또는 조정(alignment)이라고 한다. 조금 더 큰 범위로는 keypoint detection 이라고 부른다.
얼굴이 포함된 사진을 준비한다.
사진으로무터 얼굴 영역(face landmark)를 찾아낸다. (landmark를 찾기 위해서는 얼굴의 bounding box를 먼저 찾아야 한다.)
찾아진 영역으로부터 머리에 왕관 스티커를 붙여넣는다.
(1) 사진 준비하기
# 관련 패키지 설치
pip install opencv-python
pip install cmake
pip install dlib
# 필요 라이브러리 import
import cv2
import matplotlib.pyplot as plt
import numpy as np
print("🌫🛸")
# opencv로 이미지 읽어오기
import os
my_image_path = os.getenv('HOME')+'/aiffel/camera_sticker/images/image.jpg'
img_bgr = cv2.imread(my_image_path) #- OpenCV로 이미지를 읽어서
img_bgr = cv2.resize(img_bgr, (480, 640)) # 640x360의 크기로 Resize
img_show = img_bgr.copy() #- 출력용 이미지 별도 보관
plt.imshow(img_bgr)
plt.show()
# plt.imshow 이전에 RGB 이미지로 변경
# opencv는 RGB 대신 BGR을 사용하기 때문에 RGB로 변경해주어야 한다.
img_rgb = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB)
plt.imshow(img_rgb)
plt.show()
(2) 얼굴 검출 (Face Detection)
Object detection 기술을 이용해서 얼굴의 위치를 찾는다. dlib 의 face detector는 HOG(Histogram of Oriented Gradient) feature를 사용해서 SVM(Support Vector Machine)의 sliding window로 얼굴을 찾는다.
# hog detector 선언
import dlib
detector_hog = dlib.get_frontal_face_detector()
# bounding box 추출
img_rgb = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB)
dlib_rects = detector_hog(img_rgb, 1) #- (image, num of img pyramid)
# 찾은 얼굴영역 출력
print(dlib_rects) # 찾은 얼굴영역 좌표
for dlib_rect in dlib_rects:
l = dlib_rect.left()
t = dlib_rect.top()
r = dlib_rect.right()
b = dlib_rect.bottom()
cv2.rectangle(img_show, (l,t), (r,b), (0,255,0), 2, lineType=cv2.LINE_AA)
img_show_rgb = cv2.cvtColor(img_show, cv2.COLOR_BGR2RGB)
plt.imshow(img_show_rgb)
plt.show()
(3) 얼굴 랜드마크 (Face Landmark)
이목구비의 위치를 추론하는 것을 face landmark localization 기술이라고 한다. face landmark는 detection의 결과물인 bounding box로 잘라낸(crop) 얼굴 이미지를 이용한다.
Object keypoint estimation 알고리즘 : 객체 내부의 점을 찾는 기술
top-down : bounding box를 찾고 box 내부의 keypoint를 예측
bottom-up : 이미지 전체의 keypoint를 먼저 찾고 point 관계를 이용해 군집화 해서 box 생성
Dlib landmark localization
# Dlib 제공 모델 사용
wget http://dlib.net/files/shape_predictor_68_face_landmarks.dat.bz2
mv shape_predictor_68_face_landmarks.dat.bz2 ~/aiffel/camera_sticker/models
cd ~/aiffel/camera_sticker && bzip2 -d ./models/shape_predictor_68_face_landmarks.dat.bz2
# landmark 모델 불러오기
import os
model_path = os.getenv('HOME')+'/aiffel/camera_sticker/models/shape_predictor_68_face_landmarks.dat'
landmark_predictor = dlib.shape_predictor(model_path)
# landmark 찾기
list_landmarks = []
for dlib_rect in dlib_rects:
points = landmark_predictor(img_rgb, dlib_rect)
list_points = list(map(lambda p: (p.x, p.y), points.parts()))
list_landmarks.append(list_points)
print(len(list_landmarks[0]))
# landmark 출력
for landmark in list_landmarks:
for idx, point in enumerate(list_points):
cv2.circle(img_show, point, 2, (0, 255, 255), -1) # yellow
img_show_rgb = cv2.cvtColor(img_show, cv2.COLOR_BGR2RGB)
plt.imshow(img_show_rgb)
plt.show()
(4) 스티커 적용하기
적절한 랜드마크를 기준으로 하여 스티커 이미지를 구현한다.
# 좌표 확인
for dlib_rect, landmark in zip(dlib_rects, list_landmarks):
print (landmark[30]) # nose center index : 30
x = landmark[30][0]
y = landmark[30][1] - dlib_rect.width()//2
w = dlib_rect.width()
h = dlib_rect.width()
print ('(x,y) : (%d,%d)'%(x,y))
print ('(w,h) : (%d,%d)'%(w,h))
# 스티커 이미지 Read
import os
sticker_path = os.getenv('HOME')+'/aiffel/camera_sticker/images/king.png'
img_sticker = cv2.imread(sticker_path)
img_sticker = cv2.resize(img_sticker, (w,h))
print (img_sticker.shape)
# 스티커 이미지 좌표
refined_x = x - w // 2 # left
refined_y = y - h # top
print ('(x,y) : (%d,%d)'%(refined_x, refined_y))
# y좌표가 음수일 때, -y만큼 이미지를 잘라준 후 y 경계값은 0으로 설정
#img_sticker = img_sticker[-refined_y:]
#print (img_sticker.shape)
#refined_y = 0
#print ('(x,y) : (%d,%d)'%(refined_x, refined_y))
# 원본에 스티커 적용
sticker_area = img_show[refined_y:refined_y+img_sticker.shape[0], refined_x:refined_x+img_sticker.shape[1]]
img_show[refined_y:refined_y+img_sticker.shape[0], refined_x:refined_x+img_sticker.shape[1]] = \
np.where(img_sticker==0,sticker_area,img_sticker).astype(np.uint8)
# 결과 이미지 출력
plt.imshow(cv2.cvtColor(img_show, cv2.COLOR_BGR2RGB))
plt.show()
# bounding box 제거 후 이미지
sticker_area = img_bgr[refined_y:refined_y+img_sticker.shape[0], refined_x:refined_x+img_sticker.shape[1]]
img_bgr[refined_y:refined_y+img_sticker.shape[0], refined_x:refined_x+img_sticker.shape[1]] = \
np.where(img_sticker==0,sticker_area,img_sticker).astype(np.uint8)
plt.imshow(cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB))
plt.show()
2. 고양이 수염 스티커 만들기
이번엔 귀여운 고양이 수염 스티커를 만들어보자.
# 필요 라이브러리 import
import cv2
import matplotlib.pyplot as plt
import numpy as np
import os
import dlib
import math
print("🌫🛸")
# opencv로 이미지 불러오기
my_image_path = os.getenv('HOME')+'/aiffel/camera_sticker/images/images01.jpg'
img_bgr = cv2.imread(my_image_path) #- OpenCV로 이미지를 읽어서
#img_bgr = cv2.resize(img_bgr, (img_bgr.shape[0] // 16 * 5, img_bgr.shape[1] // 9 * 5)) # Resize
img_bgr_orig = img_bgr.copy()
img_show = img_bgr.copy() #- 출력용 이미지 별도 보관
plt.imshow(img_bgr)
plt.show()
# RGB 변환
img_rgb = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB)
plt.imshow(img_rgb)
plt.show()
# HOG Detector 선언
detector_hog = dlib.get_frontal_face_detector()
# Bounding box 추출
dlib_rects = detector_hog(img_rgb, 1) #- (image, num of img pyramid)
# 찾은 얼굴 영역 좌표
print(dlib_rects)
for dlib_rect in dlib_rects:
l = dlib_rect.left()
t = dlib_rect.top()
r = dlib_rect.right()
b = dlib_rect.bottom()
cv2.rectangle(img_show, (l,t), (r,b), (0,255,0), 2, lineType=cv2.LINE_AA)
img_show_rgb = cv2.cvtColor(img_show, cv2.COLOR_BGR2RGB)
plt.imshow(img_show_rgb)
plt.show()
# landmark model 불러오기
model_path = os.getenv('HOME')+'/aiffel/camera_sticker/models/shape_predictor_68_face_landmarks.dat'
landmark_predictor = dlib.shape_predictor(model_path)
# landmark 찾기
list_landmarks = []
for dlib_rect in dlib_rects:
points = landmark_predictor(img_rgb, dlib_rect)
list_points = list(map(lambda p: (p.x, p.y), points.parts()))
list_landmarks.append(list_points)
print(len(list_landmarks[0])) # landmark 갯수 확인
# landmark 출력
for landmark in list_landmarks:
for idx, point in enumerate(list_points):
cv2.circle(img_show, point, 2, (0, 255, 255), -1) # yellow
img_show_rgb = cv2.cvtColor(img_show, cv2.COLOR_BGR2RGB)
plt.imshow(img_show_rgb)
plt.show()
# 좌표 확인
for dlib_rect, landmark in zip(dlib_rects, list_landmarks):
print (landmark[30]) # nose center index : 30
x = landmark[30][0]
y = landmark[30][1]
w = dlib_rect.width()
h = dlib_rect.width()
print ('(x,y) : (%d,%d)'%(x,y))
print ('(w,h) : (%d,%d)'%(w,h))
# 스티커 이미지 Read
sticker_path = os.getenv('HOME')+'/aiffel/camera_sticker/images/cat-whiskers.png'
img_sticker = cv2.imread(sticker_path)
img_sticker = cv2.resize(img_sticker, (w, h))
img_sticker_rgb = cv2.cvtColor(img_sticker, cv2.COLOR_BGR2RGB)
plt.imshow(img_sticker_rgb)
plt.show
print (img_sticker.shape)
# 스티커 이미지 좌표
refined_x = x - w // 2 # left
refined_y = y - h // 2 # top
print ('(x,y) : (%d,%d)'%(refined_x, refined_y))
# y좌표가 음수일 때, -y만큼 이미지를 잘라준 후 y 경계값은 0으로 설정
if refined_y < 0:
img_sticker = img_sticker[-refined_y:]
refined_y = 0
print (img_sticker.shape)
print ('(x,y) : (%d,%d)'%(refined_x, refined_y))
# 원본에 스티커 적용
sticker_area = img_show[refined_y:refined_y+img_sticker.shape[0], refined_x:refined_x+img_sticker.shape[1]]
img_show[refined_y:refined_y+img_sticker.shape[0], refined_x:refined_x+img_sticker.shape[1]] = \
np.where(img_sticker==255,sticker_area,img_sticker).astype(np.uint8)
# 결과 이미지 출력
plt.imshow(cv2.cvtColor(img_show, cv2.COLOR_BGR2RGB))
plt.show()
# 불투명도 조절
sticker_area = img_bgr_orig[refined_y:refined_y+img_sticker.shape[0], refined_x:refined_x+img_sticker.shape[1]]
img_bgr[refined_y:refined_y+img_sticker.shape[0], refined_x:refined_x+img_sticker.shape[1]] = \
cv2.addWeighted(sticker_area, 0.5, np.where(img_sticker==255,sticker_area,img_sticker).astype(np.uint8), 0.5, 0)
plt.imshow(cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB))
plt.show()
# vector 계산
landmark = list_landmarks[0]
v1 = np.array([0, -1])
v2 = np.array([abs(landmark[33][0] - landmark[27][0]), abs(landmark[33][1] - landmark[27][1])])
unit_vector_1 = v1 / np.linalg.norm(v1)
unit_vector_2 = v2 / np.linalg.norm(v2)
dot_product = np.dot(unit_vector_1, unit_vector_2)
angle = np.arccos(dot_product)
# 회전 변환
rows, cols = img_sticker.shape[:2]
img_sticker_rot = cv2.warpAffine(img_sticker, cv2.getRotationMatrix2D((cols/2, rows/2), math.degrees(angle), 1), (cols, rows))
plt.imshow(img_sticker_rot)
plt.show
# 회전 후 불투명도 조절 -> 실패
sticker_area = img_bgr_orig[refined_y:refined_y+img_sticker.shape[0], refined_x:refined_x+img_sticker.shape[1]]
img_bgr[refined_y:refined_y+img_sticker.shape[0], refined_x:refined_x+img_sticker.shape[1]] = \
cv2.addWeighted(sticker_area, 0.5, np.where(img_sticker_rot==255,sticker_area,img_sticker_rot).astype(np.uint8), 0.5, 0)
plt.imshow(cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB))
plt.show()
오늘 과제는 구현하는 것 까지는 어렵지 않았지만 기능을 추가하면서 어려움을 느꼈다. 특히 투명도를 조절하는 부분이나 각도를 조절하는 부분이 가장 어려웠던 것 같다. 당연하게도 얼굴 각도가 변하면 그에 맞게 스티커도 변형시켜주어야 해서 회전시키는 것 까지는 좋은 시도였으나, 회전시켜야 할 벡터를 잘못 구하였다. 나는 코를 중심으로 스티커를 적용시켰기 때문에 얼굴의 각도에 따라 회전시키면 된다고 생각했다. 따라서 27, 33번 landmark를 두 점으로 하는 벡터에 수직인 벡터를 구한 후 x축에 평행한 벡터와의 각을 구해야 했으나 다른 벡터를 구하고 있었다.
멀리서 촬영한 이미지나 옆으로 누워서 촬영한 이미지는 아무래도 얼굴의 선이나 눈, 코, 입과같은 특징을 찾아내기 어려워서 그런 것 같다.
만약 이것을 실제로 앱으로 만들었을 때, 실행 속도나 정확도는 크게 중요하지 않을 것 같다. 물론 실행 속도가 느리면 느리다고 불평하기야 하겠지만 기능에 문제가 있는 것은 아니니 괜찮지 않을까...? 정확도는 가끔 정확하지 않은 쪽이 더 재미를 주는 경우도 있기 때문에 사람들에게 즐거움을 줄 수 있는 오류라면 괜찮다고 생각한다. 물론 개발자한테는 아니겠지만
# datasets 불러오기
from sklearn.datasets import load_iris
iris = load_iris()
print(type(dir(iris))) # dir()는 객체가 어떤 변수와 메서드를 가지고 있는지 나열함
# 메서드 확인
iris.keys()
iris_data = iris.data # iris.method 로 해당 메소드를 불러올 수 있다.
# shape는 배열의 형상 정보를 출력
print(iris_data.shape)
# 각 label의 이름
iris.target_names
# 데이터셋에 대한 설명
print(iris.DESCR)
# 각 feature의 이름
iris.feature_names
# datasets의 저장된 경로
iris.filename
# pandas 불러오기
import pandas as pd
print(pd.__version__) # pandas version 확인
# DataFreame 자료형으로 변환하기
iris_df = pd.DataFrame(data=iris_data, columns=iris.feature_names)
iris_df["label"] = iris.target
(3) train, test 데이터 분리
# train_test_split 함수를 이용하여 train set과 test set으로 나누기
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(iris_data,
iris_label,
test_size=0.2,
random_state=7)
print(f'x_train 개수: {len(x_train)}, x_test 개수: {len(x_test)}')
# Decision Tree 사용하기
from sklearn.tree import DecisionTreeClassifier
decision_tree = DecisionTreeClassifier(random_state=32)
print(decision_tree._estimator_type) # decision_tree 의 type 확인
decision_tree.fit(x_train, y_train)
y_pred = decision_tree.predict(x_test)
print(classification_report(y_test, y_pred))
# Random Forest
from sklearn.ensemble import RandomForestClassifier
random_forest = RandomForestClassifier(random_state=32)
random_forest.fit(x_train, y_train)
y_pred = random_forest.predict(x_test)
print(classification_report(y_test, y_pred))
# Support Vector Machine (SVM)
from sklearn import svm
svm_model = svm.SVC()
svm_model.fit(x_train, y_train)
y_pred = svm_model.predict(x_test)
print(classification_report(y_test, y_pred))
단순히 라이브러리에서 데이터와 함수를 불러오는 것 만으로도 쉽게 머신러닝 모델을 만들 수 있다.
2. 데이터의 불균형으로 인한 정확도의 오류
(1) 믿을 수 있는 데이터인가?
사이킷런 라이브러리를 이용하여 만든 머신러닝 모델들은 모두 괜찮은 정확도를 보여주었다. 그러나 이 데이터가 정말로 믿을 수 있는, 유효한 데이터인가?
예를 들어, test set의 정답 레이블이 [0, 0, 0, 0, 1, 0, 0, 0, 0, 0] 이라고 할 때, 모델의 학습이 잘못되어서 제대로 판단할 수 없지만 출력값은 0으로 처리한다고 하면 이 모델의 정확도는 90%라고 할 수 있을까?
이것을 판단하기 위해서 Confusion Matrix(혼동 행렬)에 대해 알아보자.
(2) Confusion Matrix
혼동 행렬은 주로 알고리즘 분류 알고리즘의 성능을 시각화 할 수 있는 표이다. 따라서 해당 모델이 True를 얼만큼 True라고 판단했는지, False를 얼만큼 False라고 판단했는지 쉽게 확인할 수 있다.
알고리즘의 성능을 판단할 때에는 어디에 적용되는 알고리즘인가를 먼저 생각한 후에 판단할 수 있다. 예를 들어, 스팸 메일을 분류한다고 할 때, 스팸 메일은 정상 메일로 분류되어도 괜찮지만, 정상 메일은 스팸 메일로 분류되어서는 안된다. 또는 환자의 암을 진단할 때, 음성을 양성으로 진단하는 것 보다 양성을 음성으로 진단하는 것은 큰 문제를 일으킬 수 있다. 따라서 상황에 맞는 지표를 활용할 줄 알아야 한다.
추가로, F1 Score 라는 지표도 있는데, 해당 지표는 Precision과 Recall(Sensitivity)의 조화평균이며, Precision과 Recall이 얼마나 균형을 이루는지 쉽게 알 수 있는 지표이다.
3. 다른 모델 분류해보기
이번에는 사이킷런에 있는 다른 데이터셋을 공부한 모델을 이용하여 학습시켜보고 결과를 예측해보자.
(1) digits 분류하기
# (1) 필요한 모듈 import
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn import svm
from sklearn.linear_model import SGDClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
from sklearn.metrics import recall_score
# (2) 데이터 준비
digits = load_digits()
digits_data = digits.data
digits_label = digits.target
# (3) train, test 데이터 분리
x_train, x_test, y_train, y_test = train_test_split(digits_data,
digits_label,
test_size=0.2,
random_state=7)
# 정규화
x_train_norm, x_test_norm = x_train / np.max(x_train), x_test / np.max(x_test)
# (4) 모델 학습 및 예측
# Decision Tree
decision_tree = DecisionTreeClassifier(random_state=32)
decision_tree.fit(x_train_norm, y_train)
decision_tree_y_pred = decision_tree.predict(x_test_norm)
print(classification_report(y_test, decision_tree_y_pred))
# RandomForest
random_forest = RandomForestClassifier(random_state=32)
random_forest.fit(x_train_norm, y_train)
random_forest_y_pred = random_forest.predict(x_test_norm)
print(classification_report(y_test, random_forest_y_pred))
# SVM
svm_model = svm.SVC()
svm_model.fit(x_train_norm, y_train)
svm_y_pred = svm_model.predict(x_test_norm)
print(classification_report(y_test, svm_y_pred))
# SGD
sgd_model = SGDClassifier()
sgd_model.fit(x_train_norm, y_train)
sgd_y_pred = sgd_model.predict(x_test_norm)
print(classification_report(y_test, sgd_y_pred))
# Logistic Regression
logistic_model = LogisticRegression(max_iter=256)
logistic_model.fit(x_train_norm, y_train)
logistic_y_pred = logistic_model.predict(x_test_norm)
print(classification_report(y_test, logistic_y_pred))
예상 결과
이미지 파일은 2차원 배열이기 때문에 SVM을 이용하여 한 차원 늘려서 Date를 Clustering 한다면 가장 좋은 결과를 얻을 것이다.
숫자 인식은 해당 숫자를 정확한 숫자로 인식한 결과값만이 의미가 있다고 생각하기 때문에 Recall 값을 비교하여 성능을 판단할 것이다.
예상한 것과 마찬가지로 Random Forest가 가장 우수한 성능을 보여준다. 아무래도 Feature의 종류가 많아 이진 분류 문제에 정확도를 더 높여줄 수 있었던 것 같다. 물론 Logisitc Regression도 충분히 좋은 성능을 보여주었다.
이번엔 머신러닝의 가장 기본적인 모델들에 대해서 학습하였다. 라이브러리를 이용해서 직접 간단한 학습 모델도 구현해보면서 각 모델들에 대한 이해력이 높아졌다. 모델의 성능을 나타낼 때, 정확도가 중요한 것은 알고 있었지만 성능을 나타내는 지표에 이렇게 많은 지표들이 있다는 것은 처음 알게되었다. 생각해보면 당연한 사실이어서 개념이 어렵지는 않았다. 앞으로도 이 정도의 학습량이라면 충분히 문제없이 따라갈 수 있을 것 같다.