지금 다니고 있는 회사에 MLOps Engineer 포지션으로 8월 9일에 입사하여 11월 19일에 수습기간 평가를 마치고 정직원이 되었다.
비전공자로 프로그래밍을 배우기 시작하여 정확히 1년 3개월 만에 취업에 성공하였다.
목표였던 올해 안에 취업하기도 달성해서 너무 좋다.
사실 적어도 2년 정도는 생각하고 있었고, 가능하면 올해 취업하고 싶었기 때문에 열심히 한 결과와 운이 꽤 따라줬던 것 같다.
42서울을 통해서 CS 기초지식과 문제를 해결하는 방법, 동료들과 함께 하는 방법을 배웠고, 아이펠을 통하여 배운 머신러닝/딥러닝에 대한 지식을 내가 하고자 하는 직무에 잘 녹여냈던 것 같다.
처음 합격 연락을 받고 입사하기 전에는 아무것도 모르는 내가 과연 회사에서 개발자로 일을 할 수 있을까? 라는 고민을 많이 했었다. 다행히 회사도 역시 사람이 사는 곳이었다. 오히려 처음 회사 코드를 봤을 땐, 이런 코드로도 회사가 돌아가는 구나 라는 생각이 들 정도였다. 물론 나는 삽질과 팔짱끼고 모니터만 쳐다보고 있는 매일이지만, 지난 달의 내가 해내지 못한 걸 이번 달의 나는 해내고 있는 것을 보면 내가 성장하고 있다는 것을 느낄 수 있다.
3개월간 일하면서 느낀 것은 일단 이 일이 내 적성에 잘 맞는다는 것이고, IT 기업이라고 해서 꼭 코드로만 문제를 해결할 필요는 없다는 것을 느꼈고, 사람 간의 의사소통이 중요하다고 느꼈다.
실제로 내가 짠 코드는 그렇게 많지 않을 것이다. 오히려 코드를 짜는 시간보다 같이 일하는 사람과 대화하고, 문제를 해결하는 방법에 대해 논의하는 시간이 더 많았을 것이다. 영업직을 했던 경험 덕분인지, 내가 생각했을 땐 의사소통에 큰 문제는 없었다고 생각한다.
3개월의 수습기간을 마치고 받은 평가에서는 대체로 긍정적으로 평가를 받아 무사히 정직원이 될 수 있었다. 평가 중 기억나는 평가가 있는데, 나를 처음 봤을 땐 남들의 이야기를 듣기 보다 내 의견을 더 피력하는데 주력하는 사람이었으나, 지금은 그런 부분이 빠지고 있어서 점점 더 협업하기 좋은 사람이 되어가고 있다는 평가였다. 수습기간 동안 내가 잘 하고 있는 게 맞나 싶었는데 다행히 잘 하고 있었던 것 같다.
지금 일하고있는 회사는 분위기나 문화, 같이 일하는 사람들이 너무 좋아서 지금 상태가 계속 유지된다면 회사가 계속 성장하여 상장하는 날 까지 계속 일해보고 싶다. 솔직히 회사 아이템에 대한 부분은 아직 잘 모르겠지만, 모든 스타트업이 다 그런거겠지 생각하고 재미라도 있으니 아무렴 뭐 어때.
이전부터 뭐든 실제로 서비스를 만들어보는 것이 중요하다고 생각하여 아이펠을 진행하면서도 틈틈이 프로젝트를 위한 공부를 따로 하고 있었다. 그러다가 GAN을 이용한 노드를 진행했을 때, '이거다!' 하고 느낌이 와서 실제로 프로젝트로 진행해보기로 했다.
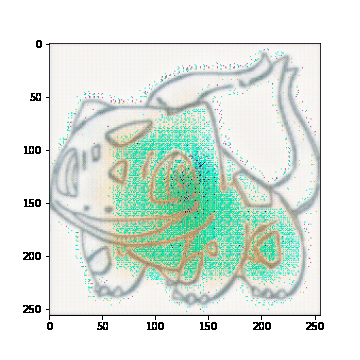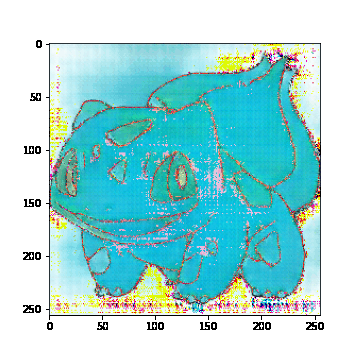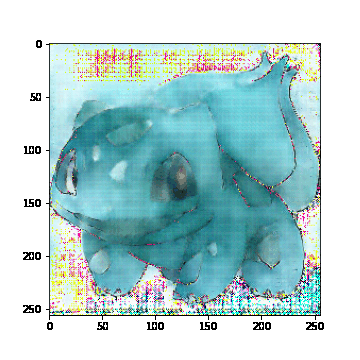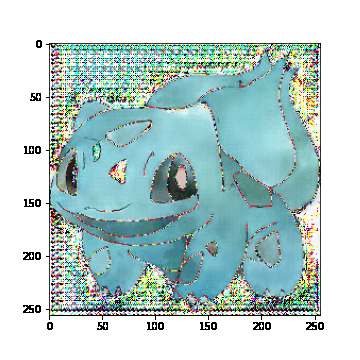
우선 기존에 아이펠 노드에서 진행한 모델은 내가 잘못 한건지, 노드가 잘못된건지 학습은 되는데 어딘가 이상한 결과물이 나와서 텐서플로 공식 튜토리얼을 보고 다시 모델을 만들어보았다.
실패한 학습 결과
데이터셋은 kaggle의 Sketch2Pokemon 데이터셋을 학습시켰다. train 이미지가 830장 밖에 되질 않았고, test 이미지도 train 이미지에 있는 중복 이미지여서 데이터가 부족하긴 했지만, 일단 서비스로 배포해보는 것에 의의를 두기로 했다.
프로젝트 진행은 다음과 같이 이루어졌다.
2021-03-28 : 프로젝트 시작
2021-03-28 ~ 2021-03-29 : 첫 번째 모델 학습 및 결과 확인
2021-03-29 ~ 2021-03-30 : 두 번째 모델 학습 및 결과 확인
2021-03-30 ~ 2021-04-01 : 모델 서비스화 진행 중
2021-04-02 : Ainize로 배포 완료
기존과의 차이점이라고 한다면 이미지를 Normalize 해주는 시점이 조금 다르다는 것이다. 아마 이 부분에서 문제가 생겨서 위와 같은 이미지가 학습된 것으로 보인다. 또한, 이미지 데이터를 다룰 때에는 항상 Normalize, Denormalize에 신경써야 하는 것 같다. 어떤 Activation Function을 사용하느냐에 따라 Normalize 범위를 [-1, 1]로 할지, [0, 1]로 할지가 결정되기 떄문이다. 이번에 사용된 모델에서는 tanh를 Activation Function으로 사용했기 때문에 [-1, 1]의 범위에서 Normalize 해주었다.
우선 시작부터 1000 epoch 정도를 돌려보고 시작하기로 했다.
학습 과정을 시각화 해본 결과, 400 epoch 정도 부터 큰 변화가 없는걸로 보아 local minima에 빠졌거나 학습이 종료된 것 같다.
750 epoch 의 checkpoint를 불러와서 기울기를 1/10으로 줄여서 50 epoch 정도 더 학습을 시켜보았으나 큰 변화는 없는 것 같다.
750 epoch 의 checkpoint를 불러와서 기울기를 10배로 늘려서 50 epoch 정도 더 학습을 시켰더니 오히려 원하지 않는 방향으로 학습이 진행되었다.
750 epoch에서의 learning rate 테스트는 자원이 남아서 학습이 종료됐을 때 learning rate를 조절하여 다시 학습시키면 어떻게 될까 궁금해서 진행해봤다.
좌 : Dicriminator loss / 우 : Generator lossTrain set에 있는 이미지 학습 결과
모델을 학습해본 결과, 두 Loss를 비교해봤을 때, disc_loss는 감소하고 gen_loss는 증가하는 것으로 보아 generator가 discriminator를 속이기 위한 이미지를 잘 생성하지 못하는 것으로 판단된다. 실제로 train과 test에 없는 전혀 새로운 이미지를 입력했을 때, 다음과 같이 잘 생성하지 못하는 결과를 보여줬다.
뒤틀린 황천의 피카츄
아무래도 기존에 있는 이미지는 원본이랑 비슷한 정도로 생성하는 것으로 보아 train set에 overfitting 된 것 같다. 추가로 다른 데이터셋을 더 활용하거나, 모델의 구조를 바꾸어서 다시 학습시켜봐야겠다.
프로젝트를 진행하면서 많은 문제점과 어려움을 겪었다. 우선 웹페이지에 이미지를 하나 띄우는 것 까진 쉬웠지만 생성된 이미지를 다시 화면에 출력하는 것이 이렇게 어려운 작업이 될 줄은 몰랐다. 프론트엔드 개발자들 대단해...
겪었던 문제점들을 정리해보면 다음과 같다.
프론트엔드/백엔드 지식이 전혀 없어서 HTML부터 공부해서 페이지를 제작함
Inference 결과 tensor object로 반환되어 해당 object를 바로 웹에서 rendering 가능한 방법을 찾다가 결국 이미지로 저장하여 rendering 하는 방식으로 진행
페이지는 정상적으로 만들어졌는데 계속해서 기존의 이미지를 가져옴 -> 브라우저 쿠키 문제
model의 크기가 100MB가 넘어가서 git lfs를 이용하여 git에 업로드 하였으나 Ainize에서 불러오지 못하는 문제가 발생
heroku에서 배포를 시도하였으나 메모리 용량 부족(500MB)으로 배포 실패
기본 git lfs 용량을 모두 사용하여 wget으로 바로 다운로드 가능한 무료 웹서버를 찾아보았지만 당장 쓸 수 있는 게 없어서 개인 웹서버 이용하여 모델 다운로드 후 Ainize로 배포
모델을 만들어서 학습시키고 실행 가능한 python 파일로 정리하는 것 까진 어렵지 않았는데 웹페이지를 구축하는 게 가장 어려웠다. 단순 텍스트 데이터가 아닌 이미지 데이터를 웹에서 띄우는 방법을 몰라 html을 공부해서 겨우 띄울 수 있게 되었는데 브라우저 캐시 때문에 정상작동 하는 걸 오작동으로 인식하여 다른 방법을 찾았다. 결국 프론트엔드를 공부하고 있는 sunhpark에게 도움을 요청하여 js로 웹페이지를 좀 더 깔끔하게 만드는 데 성공했다.
로컬에서 테스트 할 땐 잘 되었는데 막상 배포하려고 하니 적절한 서비스가 없었다. 우선 git에 모델 용량이 100MB를 초과해서 git lfs를 이용하여 Ainize로 배포를 시도하였으나 디버깅 하다가 git lfs 무료 사용량을 전부 사용하여 다른 서비스를 찾아보았다. heroku로 배포를 시도했을 땐 메모리 용량 부족으로 실패하였다.
마지막 남은 EC2는 1년만 무료여서 최후의 보루로 남겨두고 Ainize로 배포해보기 위하여 무료 파일 서버 서비스를 찾아보았지만 마땅한 게 없어서 결국 임시로 웹서버를 만들어서 Ainize에서 Dockerfile을 빌드할 때 모델을 받아올 수 있도록 하였고, 결국 성공하였다.
구글 드라이브나 네이버 클라우드 같은 곳에 파일을 업로드해서 wget으로 다운로드 받는 방법도 생각했었다. 그러나, wget으로 직접 다운로드 가능한 링크들이 아니어서 다른 방법을 찾았던건데, 나중에 찾아보니 구글 드라이브에 올린 파일도 wget으로 받을 수 있는 방법이 있었다. 당시엔 배포에 정신이 팔려 있어서 검색해볼 생각도 못 했나보다.
이번 프로젝트를 진행해보면서 왜 직접 해보는 것이 중요한지 확실하게 깨달았다. 아주 작은 토이 프로젝트였지만 어떻게 보면 프론트엔드와 백엔드 두 부분 모두 조금이나마 경험해볼 수 있었고, 직접 모델 설계부터 서비스까지 배포한 것은 MLOps라고 볼 수도 있지 않을까?
다음번엔 서버에 데이터 저장도 하고, 실제로 아마존 EC2나 GCP, Azure 같은 서비스를 이용하여 배포도 해보고, 좀 더 재미있는 아이디어를 가지고 팀원도 모아서 프로젝트를 진행해보도록 해야겠다.
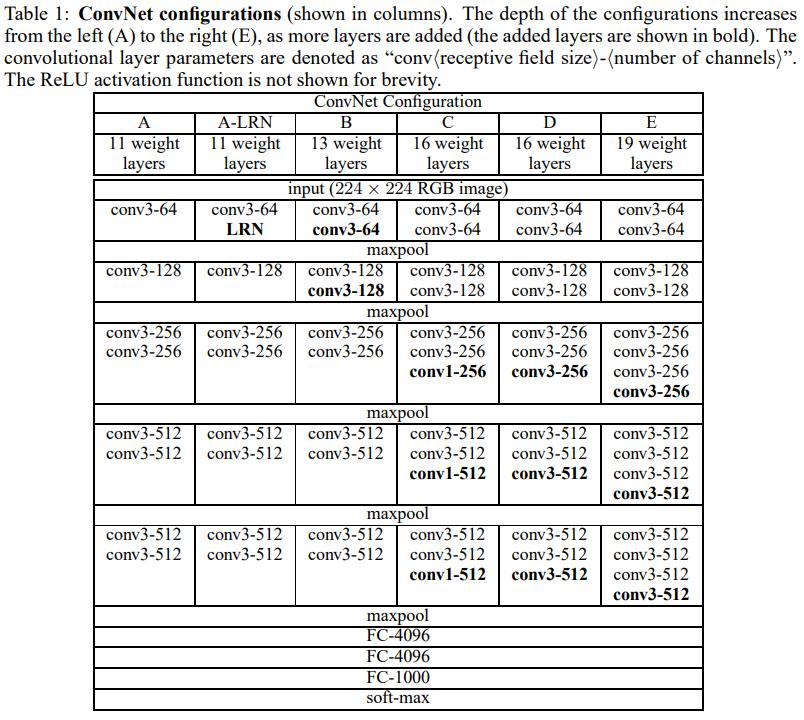
VGGNet은 2014년 ILSVRC(ImageNet Large Scale Visual Recognition Challenge)의 Classification+Localization 분야에서 1, 2등을 했을 만큼 당시에 Classification 분야에서 좋은 성능을 낸 대표적인 모델 중 하나이다. VGG는 Visual Geometry Group의 약자로 연구팀 이름으로, VGG뒤의 숫자는 신경망 모델의 깊이(레이어 수)를 나타낸다.
모델의 구조
Input : 224 x 224 RGB image
이미지 전처리 : train set의 RGB 평균값을 각 픽셀로 부터 계산하여 빼줌
filter : 3 x 3, 1 x 1(input channel 에서 linear transformation 할 때)
stride = 1, padding = same
max-pooling : 2 x 2, stride = 2
3개의 FC Layer : 4096 → 4096 → 1000(classification, softmax)
activation function : ReLU
total 144M parameter(VGG-19)
VGG Architecture
모델의 구성
아래의 표 1에서 볼 수 있듯이, A-E라는 이름의 모델들을 11개의 layer(8 conv. + 3FC layers) 부터 최대 19개의 layer(16 conv. + 3FC layers)까지 모델의 깊이를 변화시켜가며 실험을 진행하였다.
VGGNet은 이전에 7x7의 filter를 사용하는 모델들과 달리 상하좌우의 feature를 추출할 수 있는 가장 작은 크기의 filter인 3x3을 사용하였다. filter의 크기를 줄이는 대신 layer를 늘려 7x7 filter와 동일한 receptive field를 갖도록 했다.
출처 : Research Gate
3x3 filter를 사용함으로써 얻는 이점은 다음과 같다.
결정 함수의 비선형성 증가 7x7 filter를 사용했을 땐 activation function을 한 번 밖에 통과하지 않지만, 3x3 filter의 3개 layer를 사용했을 땐 activation function을 3번 통과하므로 함수의 비선형성이 증가하게 된다. 따라서 모델이 더 복잡한 특징도 추출할 수 있게 된다.
학습 파라미터 수의 감소 7x7 filter를 사용한 C채널의 학습 파라미터 수는 $7^2C^2$로 총 $49C^2$이다. 그러나 3x3 filter를 사용한 3개 layer의 학습 파라미터 수는 $3(3^2C^2)$으로 총 $27C^2$이다. 7x7과 3x3의 3layer는 동일한 receptive field를 가지지만 parameter 수는 약 81% 감소했다. 따라서 학습시간에 있어서 더 유리하게 된다.
모델 학습
VGGNet은 다음과 같은 최적화 방법을 사용하여 모델을 학습시켰다.
mini-batch gradient descent
Momentum (0.9)
batch_size = 256
weight decay (L2 = 5e10-4)
Dropout (0.5)
Initial learning rate = 0.01
모델을 학습하면서 validation set accuracy가 증가하지 않을 때 learning rate를 1/10으로 감소시켰으며, 370K iterations (74 epochs)를 진행하는 동안 3번의 learning rate 감소가 이루어졌다.
Initial weight는 N(0, 0.01^2)을 따르는 정규분포에서 sampling
Initial bias = 0
고정된 224x224의 image를 얻기 위해 train image를 random하게 crop하거나 rescale하였고, 더 나아가 augmentation을 위해 random하게 수평으로 flip하거나 RGB color를 shift 하였다.
평가
local response normalization (A-LRN network)을 사용한 것은 큰 효과가 없었다. 따라서 더 깊은 레이어(B-E)에서 normalization을 사용하지 않았다.
ConvNet의 깊이가 증가함에 따라 classification error가 감소하는 것을 확인할 수 있었다. 해당 Dataset에서는 19개의 layer로도 error rate가 saturated 되었지만, 더 큰 Dataset에서는 더 깊은 layer가 유용할 수 있다.
결론
ConvNet에서 layer의 깊이를 증가시키면 classification accuracy를 향상시키는 데 도움이 되며, ImageNet challenge dataset에 대한 state-of-the-art 성능을 얻을 수 있음을 증명하였다.
해당 모델을 코드로는 구현 해보았으나, 실제로 학습을 시켜보진 않았다. 150GB나 되는 ImageNet Dataset을 받아서 학습을 시킬 엄두가 나질 않았기 때문이다. ImageNet을 학습시키는 데 걸리는 시간은 P100 256개를 병렬로 연결해도 1시간이나 걸리는 것으로 알고 있는데, 단일 GPU를 사용하면 아마 몇 주 단위의 시간이 소요될 것이기 때문에 어쩔 수 없었다.
이 논문을 봤을 때, 딥러닝은 역시 컴퓨팅 파워가 중요하다고 생각했다. 과연 2014년 이전에는 deep network에 대한 인식이 없었을까? 물론 이전에도 deep network를 위한 시도는 있었으나 컴퓨팅 파워의 부족으로 ILSVRC의 dataset를 학습시킬 수 없었기 때문에 할 수 없었던 것으로 보인다. 분명 2021년인 지금도 엄청나게 깊은 deep network에 대한 시도는 계속 되고 있을 것이라고 생각한다. 다만 해당 network를 학습시킬 만한 컴퓨팅 파워가 부족하기 때문에 해당 network의 성능을 확인할 수 없을 뿐이라고 생각한다. 만약 딥러닝의 'deep'이 정말로 우리가 생각도 못할 만큼 'deep' 해야 한다면? 지금의 딥러닝 모델들이 이제 겨우 시작이라고 한다면?
텍스트 요약(Text Summarization)이란 위 그림과 같이 긴 길이의 문서(Document) 원문을 핵심 주제만으로 구성된 짧은 요약(Summary) 문장들로 변환하는 것을 말한다. 상대적으로 큰 텍스트인 뉴스 기사로 작은 텍스트인 뉴스 제목을 만들어내는 것이 텍스트 요약의 대표적인 예로 볼 수 있다.
이때 중요한 것은 요약 전후에 정보 손실 발생이 최소화되어야 한다는 점이다. 이것은 정보를 압축하는 과정과 같다. 비록 텍스트의 길이가 크게 줄어들었지만, 요약문은 문서 원문이 담고 있는 정보를 최대한 보존하고 있어야 한다. 이것은 원문의 길이가 길수록 만만치 않은 어려운 작업이 된다. 사람이 이 작업을 수행한다 하더라도 긴 문장을 정확하게 읽고 이해한 후, 그 의미를 손상하지 않는 짧은 다른 표현으로 원문을 번역해 내야 하는 것이다.
그렇다면 요약 문장을 만들어 내려면 어떤 방법을 사용하면 좋을까? 여기서 텍스트 요약은 크게 추출적 요약(Extractive Summarization)과 추상적 요약(Abstractive Summarization)의 두가지 접근으로 나누어볼 수 있다.
(1) 추출적 요약(Extractive Summarization)
첫번째 방식인 추출적 요약은 단어 그대로 원문에서 문장들을 추출해서 요약하는 방식이다. 가령, 10개의 문장으로 구성된 텍스트가 있다면, 그 중 핵심적인 문장 3개를 꺼내와서 3개의 문장으로 구성된 요약문을 만드는 식이다. 그런데 꺼내온 3개의 문장이 원문에서 중요한 문장일 수는 있어도, 3개의 문장의 연결이 자연스럽지 않을 수는 있다. 결과로 나온 문장들 간의 호응이 자연스럽지 않을 수 있다는 것이다. 딥 러닝보다는 주로 전통적인 머신 러닝 방식에 속하는 텍스트랭크(TextRank)와 같은 알고리즘을 사용한다.
(2) 추상적 요약(Abstractive Summarization)
두번째 방식인 추상적 요약은 추출적 요약보다 좀 더 흥미로운 접근을 사용한다. 원문으로부터 내용이 요약된 새로운 문장을 생성해내는 것이다. 여기서 새로운 문장이라는 것은 결과로 나온 문장이 원문에 원래 없던 문장일 수도 있다는 것을 의미한다. 자연어 처리 분야 중 자연어 생성(Natural Language Generation, NLG)의 영역인 셈이다. 반면, 추출적 요약은 원문을 구성하는 문장 중 어느 것이 요약문에 들어갈 핵심문장인지를 판별한다는 점에서 문장 분류(Text Classification) 문제로 볼 수 있을 것이다.
인공 신경망으로 텍스트 요약 훈련시키기
seq2seq 모델을 통해서 Abstractive summarization 방식의 텍스트 요약기를 만들어보자. seq2seq은 두 개의 RNN 아키텍처를 사용하여 입력 시퀀스로부터 출력 시퀀스를 생성해내는 자연어 생성 모델로 주로 뉴럴 기계번역에 사용되지만, 원문을 요약문으로 번역한다고 생각하면 충분히 사용 가능할 것이다.
seq2seq 개요
원문을 첫번째 RNN인 인코더로 입력하면, 인코더는 이를 하나의 고정된 벡터로 변환한다. 이 벡터를 문맥 정보를 가지고 있는 벡터라고 하여 컨텍스트 벡터(context vector)라고 한다. 두번째 RNN인 디코더는 이 컨텍스트 벡터를 전달받아 한 단어씩 생성해내서 요약 문장을 완성한다.
LSTM과 컨텍스트 벡터
LSTM이 바닐라 RNN과 다른 점은 다음 time step의 셀에 hidden state뿐만 아니라, cell state도 함께 전달한다는 점이다. 다시 말해, 인코더가 디코더에 전달하는 컨텍스트 벡터 또한 hidden state h와 cell state c 두 개의 값 모두 존재해야 한다는 뜻이다.
시작 토큰과 종료 토큰
[시작 토큰 SOS와 종료 토큰 EOS는 각각 start of a sequence와 end of a sequence를 나타낸다]
seq2seq 구조에서 디코더는 시작 토큰 SOS가 입력되면, 각 시점마다 단어를 생성하고 이 과정을 종료 토큰 EOS를 예측하는 순간까지 멈추지않는다. 다시 말해 훈련 데이터의 예측 대상 시퀀스의 앞, 뒤에는 시작 토큰과 종료 토큰을 넣어주는 전처리를 통해 어디서 멈춰야하는지 알려줄 필요가 있다.
어텐션 메커니즘을 통한 새로운 컨텍스트 벡터 사용하기
기존의 seq2seq는 인코더의 마지막 time step의 hidden state를 컨텍스트 벡터로 사용했다. 하지만 RNN 계열의 인공 신경망(바닐라 RNN, LSTM, GRU)의 한계로 인해 이 컨텍스트 정보에는 이미 입력 시퀀스의 많은 정보가 손실이 된 상태가 된다.
이와 달리, 어텐션 메커니즘(Attention Mechanism)은 인코더의 모든 step의 hidden state의 정보가 컨텍스트 벡터에 전부 반영되도록 하는 것이다. 하지만 인코더의 모든 hidden state가 동일한 비중으로 반영되는 것이 아니라, 디코더의 현재 time step의 예측에 인코더의 각 step이 얼마나 영향을 미치는지에 따른 가중합으로 계산되는 방식이다.
여기서 주의해야 할 것은, 컨텍스트 벡터를 구성하기 위한 인코더 hidden state의 가중치 값은 디코더의 현재 스텝이 어디냐에 따라 계속 달라진다는 점이다. 즉, 디코더의 현재 문장 생성 부위가 주어부인지 술어부인지 목적어인지 등에 따라 인코더가 입력 데이터를 해석한 컨텍스트 벡터가 다른 값이 된다. 이와 달리, 기본적인 seq2seq 모델에서 컨텍스트 벡터는 디코더의 현재 스텝 위치에 무관하게 한번 계산되면 고정값을 가진다.
인물사진 모드란, 피사체를 촬영할 때 배경이 흐려지는 효과를 넣어주는 것을 이야기 한다. 물론 DSLR의 아웃포커스 효과와는 다른 방식으로 구현한다.
핸드폰 카메라의 인물사진 모드는 듀얼 카메라를 이용해 아웃포커싱 기능을 흉내낸다.
DSLR에서는 사진을 촬영할 때 피사계 심도(depth of field, DOF)를 얕게 하여 초점이 맞은 피사체를 제외한 배경을 흐리게 만든다.
핸드폰 인물사진 모드는 화각이 다른 두 렌즈를 사용한다. 일반(광각) 렌즈에서는 배경을 촬영하고 망원 렌즈에서는 인물을 촬영한 뒤 배경을 흐리게 처리한 후 망원 렌즈의 인물과 적절하게 합성한다.
인물사진 모드에서 사용되는 용어
한국에서는 배경을 흐리게 하는 기술을 주로 '아웃포커싱'이라고 표현한다. 하지만 아웃포커싱은 한국에서만 사용하는 용어이고 정확한 영어 표현은 얕은 피사계 심도(shallow depth of field) 또는 셸로우 포커스(shallow focus) 라고 한다.
학습 목표
딥러닝을 이용하여 핸드폰 인물 사진 모드를 모방해본다.
셸로우 포커스 만들기
(1) 사진준비
하나의 카메라로 셸로우 포커스(shallow focus)를 만드는 방법은 다음과 같다.
이미지 세그멘테이션(Image segmentation) 기술을 이용하면 하나의 이미지에서 배경과 사람을 분리할 수 있다. 분리된 배경을 블러(blur)처리 후 사람 이미지와 다시 합하면 아웃포커싱 효과를 적용한 인물사진을 얻을 수 있다.
# 필요 모듈 import
import cv2
import numpy as np
import os
from glob import glob
from os.path import join
import tarfile
import urllib
from matplotlib import pyplot as plt
import tensorflow as tf
# 이미지 불러오기
import os
img_path = os.getenv('HOME')+'/aiffel/human_segmentation/images/2017.jpg' # 본인이 선택한 이미지의 경로에 맞게 바꿔 주세요.
img_orig = cv2.imread(img_path)
print (img_orig.shape)
(2) 세그멘테이션으로 사람 분리하기
배경에만 렌즈흐림 효과를 주기 위해서는 이미지에서 사람과 배경을 분리해야 한다. 흔히 포토샵으로 '누끼 따기'와 같은 작업을 이야기한다.
세그멘테이션(Segmentation)이란?
이미지에서 픽셀 단위로 관심 객체를 추출하는 방법을 이미지 세그멘테이션(image segmentation) 이라고 한다. 이미지 세그멘테이션은 모든 픽셀에 라벨(label)을 할당하고 같은 라벨은 "공통적인 특징"을 가진다고 가정한다. 이 때 공통 특징은 물리적 의미가 없을 수도 있다. 픽셀이 비슷하게 생겼다는 사실은 인식하지만, 우리가 아는 것처럼 실제 물체 단위로 인식하지 않을 수 있다. 물론 세그멘테이션에는 여러 가지 세부 태스크가 있으며, 태스크에 따라 다양한 기준으로 객체를 추출한다.
시멘틱 세그맨테이션(Semantic segmentation)이란?
세그멘테이션 중에서도 특히 우리가 인식하는 세계처럼 물리적 의미 단위로 인식하는 세그멘테이션을 시맨틱 세그멘테이션 이라고 한다. 쉽게 설명하면 이미지에서 픽셀을 사람, 자동차, 비행기 등의 물리적 단위로 분류(classification)하는 방법이라고 할 수 있다.
인스턴스 세그멘테이션(Instance segmentation)이란?
시맨틱 세그멘테이션은 '사람'이라는 추상적인 정보를 이미지에서 추출해내는 방법이다. 그래서 사람이 누구인지 관계없이 같은 라벨로 표현이 된다. 더 나아가서 인스턴스 세그멘테이션은 사람 개개인 별로 다른 라벨을 가지게 한다. 여러 사람이 한 이미지에 등장할 때 각 객체를 분할해서 인식하자는 것이 목표이다.
이미지 세그멘테이션의 간단한 알고리즘 : 워터쉐드 세그멘테이션(watershed segmentation)
이미지에서 영역을 분할하는 가장 간단한 방법은 물체의 '경계'를 나누는 것이다. 이미지는 그레이스케일(grayscale)로 변환하면 0~255의 값을 가지기 때문에 픽셀 값을 이용해서 각 위치의 높고 낮음을 구분할 수 있다. 따라서 낮은 부분부터 서서히 '물'을 채워 나간다고 생각할 때 각 영역에서 점점 물이 차오르다가 넘치는 시점을 경계선으로 만들면 물체를 서로 구분할 수 있게 된다.
(3) 시멘틱 세그멘테이션 다뤄보기
세그멘테이션 문제에는 FCN, SegNet, U-Net 등 많은 모델이 사용된다. 오늘은 그 중에서 DeepLab이라는 세그멘테이션 모델을 만들고 모델에 이미지를 입력할 것이다. DeepLab 알고리즘(DeepLab v3+)은 세그멘테이션 모델 중에서도 성능이 매우 좋아 최근까지도 많이 사용되고 있다.
# DeepLabModel Class 정의
class DeepLabModel(object):
INPUT_TENSOR_NAME = 'ImageTensor:0'
OUTPUT_TENSOR_NAME = 'SemanticPredictions:0'
INPUT_SIZE = 513
FROZEN_GRAPH_NAME = 'frozen_inference_graph'
# __init__()에서 모델 구조를 직접 구현하는 대신, tar file에서 읽어들인 그래프구조 graph_def를
# tf.compat.v1.import_graph_def를 통해 불러들여 활용하게 됩니다.
def __init__(self, tarball_path):
self.graph = tf.Graph()
graph_def = None
tar_file = tarfile.open(tarball_path)
for tar_info in tar_file.getmembers():
if self.FROZEN_GRAPH_NAME in os.path.basename(tar_info.name):
file_handle = tar_file.extractfile(tar_info)
graph_def = tf.compat.v1.GraphDef.FromString(file_handle.read())
break
tar_file.close()
with self.graph.as_default():
tf.compat.v1.import_graph_def(graph_def, name='')
self.sess = tf.compat.v1.Session(graph=self.graph)
# 이미지를 전처리하여 Tensorflow 입력으로 사용 가능한 shape의 Numpy Array로 변환합니다.
def preprocess(self, img_orig):
height, width = img_orig.shape[:2]
resize_ratio = 1.0 * self.INPUT_SIZE / max(width, height)
target_size = (int(resize_ratio * width), int(resize_ratio * height))
resized_image = cv2.resize(img_orig, target_size)
resized_rgb = cv2.cvtColor(resized_image, cv2.COLOR_BGR2RGB)
img_input = resized_rgb
return img_input
def run(self, image):
img_input = self.preprocess(image)
# Tensorflow V1에서는 model(input) 방식이 아니라 sess.run(feed_dict={input...}) 방식을 활용합니다.
batch_seg_map = self.sess.run(
self.OUTPUT_TENSOR_NAME,
feed_dict={self.INPUT_TENSOR_NAME: [img_input]})
seg_map = batch_seg_map[0]
return cv2.cvtColor(img_input, cv2.COLOR_RGB2BGR), seg_map
preprocess()는 전처리, run()은 실제로 세그멘테이셔는 하는 함수이다. input tensor를 만들기 위해 전처리를 하고, 적절한 크기로 resize하여 OpenCV의 BGR 채널은 RGB로 수정 후 run()함수의 input parameter로 사용된다.
# Model 다운로드
# define model and download & load pretrained weight
_DOWNLOAD_URL_PREFIX = 'http://download.tensorflow.org/models/'
model_dir = os.getenv('HOME')+'/aiffel/human_segmentation/models'
tf.io.gfile.makedirs(model_dir)
print ('temp directory:', model_dir)
download_path = os.path.join(model_dir, 'deeplab_model.tar.gz')
if not os.path.exists(download_path):
urllib.request.urlretrieve(_DOWNLOAD_URL_PREFIX + 'deeplabv3_mnv2_pascal_train_aug_2018_01_29.tar.gz',
download_path)
MODEL = DeepLabModel(download_path)
print('model loaded successfully!')
위 코드는 구글이 제공하는 pretrained weight이다. 이 모델은 PASCAL VOC 2012라는 대형 데이터셋으로 학습된 v3 버전이다.
# 이미지 resize
img_resized, seg_map = MODEL.run(img_orig)
print (img_orig.shape, img_resized.shape, seg_map.max()) # cv2는 채널을 HWC 순서로 표시
# seg_map.max() 의 의미는 물체로 인식된 라벨 중 가장 큰 값을 뜻하며, label의 수와 일치
# PASCAL VOC로 학습된 label
LABEL_NAMES = [
'background', 'aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus',
'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike',
'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tv'
]
len(LABEL_NAMES)
# 사람을 찾아 시각화
img_show = img_resized.copy()
seg_map = np.where(seg_map == 15, 15, 0) # 예측 중 사람만 추출 person의 label은 15
img_mask = seg_map * (255/seg_map.max()) # 255 normalization
img_mask = img_mask.astype(np.uint8)
color_mask = cv2.applyColorMap(img_mask, cv2.COLORMAP_JET)
img_show = cv2.addWeighted(img_show, 0.6, color_mask, 0.35, 0.0)
plt.imshow(cv2.cvtColor(img_show, cv2.COLOR_BGR2RGB))
plt.show()
(4) 세그멘테이션 결과를 원래 크기로 복원하기
DeepLab 모델을 사용하기 위해 이미지 크기를 작게 resize했기 때문에 원래 크기로 복원해야 한다.
cv2.resize() 함수를 이용하여 원래 크기로 복원하였다. 크기를 키울 때 보간(interpolation)을 고려해야 하는데, cv2.INTER_NEAREST를 이용하면 깔끔하게 처리할 수 있지만 더 정확하게 확대하기 위해 cv2.INTER_LINEAR를 사용하였다.
결과적으로 img_mask_up 은 경계가 블러된 픽셀값 0~255의 이미지를 얻는다. 확실한 경계를 다시 정하기 위해 중간값인 128을 기준으로 임계값(threshold)을 설정하여 128 이하의 값은 0으로 128 이상의 값은 255로 만들었다.
(5) 배경 흐리게 하기
# 배경 이미지 얻기
img_mask_color = cv2.cvtColor(img_mask_up, cv2.COLOR_GRAY2BGR)
img_bg_mask = cv2.bitwise_not(img_mask_color)
img_bg = cv2.bitwise_and(img_orig, img_bg_mask)
plt.imshow(img_bg)
plt.show()
bitwise_not : not 연산하여 이미지 반전
bitwise_and : 배경과 and 연산하여 배경만 있는 이미지를 얻을 수 있다.
# 이미지 블러처리
img_bg_blur = cv2.blur(img_bg, (13,13))
plt.imshow(cv2.cvtColor(img_bg_blur, cv2.COLOR_BGR2RGB))
plt.show()
(6) 흐린 배경과 원본 영상 합성
# 255인 부분만 원본을 가져온 후 나머지는 blur 이미지
img_concat = np.where(img_mask_color==255, img_orig, img_bg_blur)
plt.imshow(cv2.cvtColor(img_concat, cv2.COLOR_BGR2RGB))
plt.show()
회고록
평소에 사진을 취미로 하고 있어서 이번 과제를 이해하는 것이 어렵지 않았다.
이미지 세그멘테이션에 대해 단어만 알고 정확히 어떤 역할을 하는 기술인지 잘 몰랐는데 이번 학습을 통해 확실하게 알 수 있었다.
이미지를 블러처리 하는 과정에서 인물과 배경의 경계 부분도 같이 블러처리 되어버리기 때문에 나중에 이미지를 병합하는 과정에서 배경에 있는 인물 영역이 실제 사진의 인물 영역보다 넓어져 병합 후의 이미지에서 경계 주위로 그림자(?)가 지는 것 같은 현상을 볼 수 있었다.
앞으로 자율주행이나 인공지능을 이용해서 자동화 할 수 있는 부분에는 어디든 사용될 수 있을 법한 그런 기술인 것 같다.
이 기술을 이용해서 병, 캔, 플라스틱 과 같은 재활용 쓰레기를 구분할 수 있다고 하면, 환경 분야에서도 쓸 수 있지 않을까...? 그 정도로 구분하는 것은 어려울 것 같긴 하다.
jupyter notebook에서 생성된 이미지를 깔끔하게 보이도록 정리하려고 html을 이용하여 사진을 정렬했었는데 github에선 html style이 무시된다는 것을 알게되어 3시간 정도를 이미지 정렬하는 데 썼다... 결국 안 된다는 것을 깨닫고 pyplot을 이용해서 비교하였다.
오늘은 아이펠 첫 Exploration 노드를 진행하였다. 나는 이론보다는 실전파라 더 기대가 되는 날이었다. 매번 인터넷으로만 보던 딥러닝 모델을 내가 직접 구현해볼 수 있는 아주 좋은 기회였다. 물론 처음부터 모든 코드를 내가 짠 것은 아니지만, 지금은 어떻게 작동을 하는지 그 원리를 이해하고 익히는 것이 중요하다고 생각한다. 처음에는 노드를 열심히 따라가면서 코드를 하나하나 실행시켜 보는 것으로 시작해서, 가위바위보를 분류하는 모델은 앞서 모델링되어있는 자료를 참고하여 내가 직접 복붙(?)한 코드이다. 물론 MNIST를 이용한 숫자 분류와는 조금 다른 부분이 있어서 해당 부분만 수정할 줄 안다면 그다지 어렵지 않은 과제였다. 라고 생각했던 때가 있었지...
How to make?
일반적으로 딥러닝 기술은 "데이터 준비 → 딥러닝 네트워크 설계 → 학습 → 테스트(평가)" 순으로 이루어진다.
1. 데이터 준비
MINIST 숫자 손글씨 Dataset 불러들이기
import tensorflow as tf
from tensorflow import keras
import numpy as np
import matplotlib.pyplot as plt
print(tf.__version__) # Tensorflow의 버전 출력
mnist = keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
print(len(x_train)) # x_train 배열의 크기를 출력
plt.imshow(x_train[1], cmap=plt.cm.binary)
plt.show() # x_train의 1번째 이미지를 출력
print(y_train[1]) # x_train[1]에 대응하는 실제 숫자값
index = 10000
plt.imshow(x_train[index], cmap=plt.cm.binary)
plt.show()
print(f'{index} 번째 이미지의 숫자는 바로 {y_train[index]} 입니다.')
print(x_train.shape) # x_train 이미지의 (count, x, y)
print(x_test.shape)
Data 전처리 하기
인공지능 모델을 훈련시킬 때, 값이 너무 커지거나 하는 것을 방지하기 위해 정수 연산보다는 0~1 사이의 값으로 정규화 시켜주는 것이 좋다.
실제 테스트 데이터를 이용하여 테스트를 진행해본 결과, 99.1% 로 소폭 하락하였다. MNIST 데이터셋 참고문헌을 보면 학습용 데이터와 시험용 데이터의 손글씨 주인이 다른 것을 알 수 있다.
어떤 데이터를 잘못 추론했는지 확인해보기
model.evalutate() 대신 model.predict()를 사용하면 model이 입력값을 보고 실제로 추론한 확률분포를 출력할 수 있다.
predicted_result = model.predict(x_test_reshaped) # model이 추론한 확률값.
predicted_labels = np.argmax(predicted_result, axis=1)
idx = 0 # 1번째 x_test를 살펴보자.
print('model.predict() 결과 : ', predicted_result[idx])
print('model이 추론한 가장 가능성이 높은 결과 : ', predicted_labels[idx])
print('실제 데이터의 라벨 : ', y_test[idx])
# 실제 데이터 확인
plt.imshow(x_test[idx],cmap=plt.cm.binary)
plt.show()
추론 결과는 벡터 형태로, 추론 결과가 각각 0, 1, 2, ..., 7, 8, 9 일 확률을 의미한다.
아래 코드는 추론해낸 숫자와 실제 값이 다른 경우를 확인해보는 코드이다.
import random
wrong_predict_list=[]
for i, _ in enumerate(predicted_labels):
# i번째 test_labels과 y_test이 다른 경우만 모아 봅시다.
if predicted_labels[i] != y_test[i]:
wrong_predict_list.append(i)
# wrong_predict_list 에서 랜덤하게 5개만 뽑아봅시다.
samples = random.choices(population=wrong_predict_list, k=5)
for n in samples:
print("예측확률분포: " + str(predicted_result[n]))
print("라벨: " + str(y_test[n]) + ", 예측결과: " + str(predicted_labels[n]))
plt.imshow(x_test[n], cmap=plt.cm.binary)
plt.show()
5. 더 좋은 네트워크 만들어 보기
딥러닝 네트워크 구조 자체는 바꾸지 않으면서도 인식률을 올릴 수 있는 방법은 Hyperparameter 들을 바꿔보는 것이다. Conv2D 레이어에서 입력 이미지의 특징 수를 증감시켜보거나, Dense 레이어에서 뉴런 수를 바꾸어보거나, epoch 값을 변경해볼 수 있다.
Title
n_channel_1
n_channel_2
n_dense
n_train_epoch
loss
accuracy
1
16
32
32
10
0.0417
0.9889
2
1
32
32
10
0.0636
0.9793
3
2
32
32
10
0.0420
0.9865
4
4
32
32
10
0.0405
0.9886
5
8
32
32
10
0.0360
0.9885
6
32
32
32
10
0.0322
0.9903
7
64
32
32
10
0.0325
0.9914
8
128
32
32
10
0.0320
0.9912
9
16
1
32
10
0.1800
0.9437
10
16
64
32
10
0.0322
0.9912
11
16
128
32
10
0.0348
0.9917
12
16
32
64
10
0.0430
0.9888
13
16
32
128
10
0.0327
0.9916
14
16
32
32
15
0.0427
0.9900
15
16
32
32
20
0.0523
0.9884
16
64
128
128
15
0.0503
0.9901
각각의 Hyperparameter 별로 최적의 값을 찾아서 해당 값들만으로 테스트해보면 가장 좋은 결과가 나올 것 이라고 예상했는데 현실은 아니었다. 이래서 딥러닝이 어려운 것 같다.
6. 프로젝트: 가위바위보 분류기 만들기
오늘 배운 내용을 바탕으로 가위바위보 분류기를 만들어보자.
데이터 준비
1. 데이터 만들기
데이터는 구글의 teachable machine 사이트를 이용하면 쉽게 만들어볼 수 있다.
여러 각도에서
여러 크기로
다른 사람과 함께
만들면 더 좋은 데이터를 얻을 수 있다.
다운받은 이미지의 크기는 224x224 이다.
2. 데이터 불러오기 + Resize 하기
MNIST 데이터셋의 경우 이미지 크기가 28x28이었기 때문에 우리의 이미지도 28x28 로 만들어야 한다. 이미지를 Resize 하기 위해 PIL 라이브러리를 사용한다.
# PIL 라이브러리가 설치되어 있지 않다면 설치
!pip install pillow
from PIL import Image
import os, glob
print("PIL 라이브러리 import 완료!")
# 이미지 Resize 하기
# 가위 이미지가 저장된 디렉토리 아래의 모든 jpg 파일을 읽어들여서
image_dir_path = os.getenv("HOME") + "/aiffel/rock_scissor_paper/train/scissor"
print("이미지 디렉토리 경로: ", image_dir_path)
images=glob.glob(image_dir_path + "/*.jpg")
# 파일마다 모두 28x28 사이즈로 바꾸어 저장
target_size=(28,28)
for img in images:
old_img=Image.open(img)
new_img=old_img.resize(target_size,Image.ANTIALIAS)
new_img.save(img,"JPEG")
print("가위 이미지 resize 완료!")
# load_data 함수
def load_data(img_path, number):
# 가위 : 0, 바위 : 1, 보 : 2
number_of_data=number # 가위바위보 이미지 개수 총합
img_size=28
color=3
#이미지 데이터와 라벨(가위 : 0, 바위 : 1, 보 : 2) 데이터를 담을 행렬(matrix) 영역을 생성
imgs=np.zeros(number_of_data*img_size*img_size*color,dtype=np.int32).reshape(number_of_data,img_size,img_size,color)
labels=np.zeros(number_of_data,dtype=np.int32)
idx=0
for file in glob.iglob(img_path+'/scissor/*.jpg'):
img = np.array(Image.open(file),dtype=np.int32)
imgs[idx,:,:,:]=img # 데이터 영역에 이미지 행렬을 복사
labels[idx]=0 # 가위 : 0
idx=idx+1
for file in glob.iglob(img_path+'/rock/*.jpg'):
img = np.array(Image.open(file),dtype=np.int32)
imgs[idx,:,:,:]=img # 데이터 영역에 이미지 행렬을 복사
labels[idx]=1 # 바위 : 1
idx=idx+1
for file in glob.iglob(img_path+'/paper/*.jpg'):
img = np.array(Image.open(file),dtype=np.int32)
imgs[idx,:,:,:]=img # 데이터 영역에 이미지 행렬을 복사
labels[idx]=2 # 보 : 2
idx=idx+1
print("학습데이터(x_train)의 이미지 개수는",idx,"입니다.")
return imgs, labels
image_dir_path = os.getenv("HOME") + "/aiffel/rock_scissor_paper"
(x_train, y_train)=load_data(image_dir_path, 2100)
x_train_norm = x_train/255.0 # 입력은 0~1 사이의 값으로 정규화
print("x_train shape: {}".format(x_train.shape))
print("y_train shape: {}".format(y_train.shape))
# 불러온 이미지 확인
import matplotlib.pyplot as plt
plt.imshow(x_train[0])
print('라벨: ', y_train[0])
# 딥러닝 네트워크 설계
import tensorflow as tf
from tensorflow import keras
import numpy as np
n_channel_1=16
n_channel_2=32
n_dense=64
n_train_epoch=15
model=keras.models.Sequential()
model.add(keras.layers.Conv2D(n_channel_1, (3,3), activation='relu', input_shape=(28,28,3)))
model.add(keras.layers.MaxPool2D(2,2))
model.add(keras.layers.Conv2D(n_channel_2, (3,3), activation='relu'))
model.add(keras.layers.MaxPooling2D((2,2)))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(n_dense, activation='relu'))
model.add(keras.layers.Dense(3, activation='softmax'))
model.summary()
# 모델 학습
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train_reshaped, y_train, epochs=n_train_epoch)
# 테스트 이미지
image_dir_path = os.getenv("HOME") + "/aiffel/rock_scissor_paper/test/testset1"
(x_test, y_test)=load_data(image_dir_path, 300)
x_test_norm = x_test/255.0 # 입력은 0~1 사이의 값으로 정규화
print("x_train shape: {}".format(x_test.shape))
print("y_train shape: {}".format(y_test.shape))
# 불러온 이미지 확인
import matplotlib.pyplot as plt
plt.imshow(x_test[0])
print('라벨: ', y_test[0])
# 모델 테스트
test_loss, test_accuracy = model.evaluate(x_test_reshaped, y_test, verbose=2)
print("test_loss: {} ".format(test_loss))
print("test_accuracy: {}".format(test_accuracy))
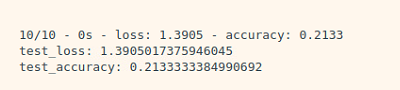
처음 100개의 데이터 가지고 실행했을 때 결과는 처참했다...
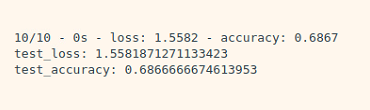
총 10명 분량을 train set으로 사용하고 test를 돌렸을 때 가장 잘 나온 결과!
오늘은 Layer를 추가하지 않고 단순히 Hyperparameter만 조정하여 인식률을 높이는 것을 목표로 했다. 우선 데이터가 부족한 것 같아서 10명 보다 더 많은 데이터를 추가해보면 좋을 것 같다. 아직 첫 모델이라 많이 부족했지만, 그래도 뭔가 목표가 있고 무엇을 해야 하는지 알게 되면 딥러닝이 조금 더 재밌어질 것 같다.