티스토리가 Markdown 문법을 제대로 지원을 안 해서 다 깨져버리니까 깃헙 링크로 대체합니다.
티스토리가 Markdown 문법을 제대로 지원을 안 해서 다 깨져버리니까 깃헙 링크로 대체합니다.
문제 링크 : leetcode.com/problems/add-two-numbers/
Add Two Numbers - LeetCode
Level up your coding skills and quickly land a job. This is the best place to expand your knowledge and get prepared for your next interview.
leetcode.com
이 문제는 두 linked list의 값들을 역순으로 하여 더한 결과의 역순을 linked list로 반환하는 문제이다.
풀이방법
두 linked list와 반환해야 할 linked list사이의 규칙을 찾아보면 역순으로 연결되어 있기 때문에 linked list의 시작이 가장 낮은 자릿수인 것을 알 수 있다. 따라서 두 linked list를 동시에 탐색하면서 값을 더하여 새로운 linked list를 만들면 되는 것이다.
sum_list.val = (l1.val + l2.val)
sum_list = sum_list.next다만 여기서 주의해야 할 점은 l1.val + l2.val 의 값이 10을 넘었을 경우이다. 10을 넘었을 경우에는 다음 list에 값을 넘겨주어야 하므로 l1.val + l2.val 의 몫과 나머지를 따로 계산하여 몫은 다음 list로, 나머지는 value로 사용하면 된다.
remain_value = (l1.val + l2.val) // 10
sum_list = (l1.val + l2.val) % 10 # divmod 함수도 사용 가능
sum_list = sum_list.next
sum_list.val = remain_value그리고 l1, l2의 조건에 맞게 코드를 정리하면 된다.
"""
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def addTwoNumbers(self, l1: ListNode, l2: ListNode) -> ListNode:
sum_list = ListNode()
curr = sum_list
while l1 or l2:
if not l1:
remain_val = (curr.val + l2.val) // 10
curr.val = (curr.val + l2.val) % 10
l2 = l2.next
elif not l2:
remain_val = (curr.val + l1.val) // 10
curr.val = (curr.val + l1.val) % 10
l1 = l1.next
else:
remain_val = (curr.val + l1.val + l2.val) // 10
curr.val = (curr.val + l1.val + l2.val) % 10
l1 = l1.next
l2 = l2.next
if l1 or l2:
curr.next = ListNode()
curr = curr.next
curr.val = remain_val
# 마지막 자릿수 확인
if remain_val == 1:
curr.next = ListNode()
curr = curr.next
curr.val = remain_val
return sum_list다른 사람들의 코드를 보니 l1, l2가 동시에 존재할 때 먼저 while문을 돌리고, 그 다음 l1, l2 순서로 while문을 돌리는 쪽이 조금 더 가독성이 좋았다.
| [LeetCode] 328. Odd Even Linked List (0) | 2021.01.24 |
|---|---|
| [LeetCode] 24. Swap Nodes in Pairs (0) | 2021.01.24 |
| [LeetCode] 206. Reverse Linked List (0) | 2021.01.23 |
| [LeetCode] 21. Merge Two Sorted Lists (0) | 2021.01.23 |
| [LeetCode] 234. Palindrome Linked List (0) | 2021.01.23 |
문제 링크 : leetcode.com/problems/reverse-linked-list/
Reverse Linked List - LeetCode
Level up your coding skills and quickly land a job. This is the best place to expand your knowledge and get prepared for your next interview.
leetcode.com
이 문제는 linked list를 역순으로 반환하는 문제이다.
풀이방법
새로운 linked list를 만들고, 입력받은 linked list를 탐색하면서 새로운 linked list를 역순으로 연결되도록 하였다.
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def reverseList(self, head: ListNode) -> ListNode:
prev = None # 첫 Linked List 생성
# head List의 끝까지 탐색
while head:
temp = ListNode()
temp.val = head.val
temp.next = prev
prev = temp
head = head.next
return prev
| [LeetCode] 328. Odd Even Linked List (0) | 2021.01.24 |
|---|---|
| [LeetCode] 24. Swap Nodes in Pairs (0) | 2021.01.24 |
| [LeetCode] 2. Add Two Numbers (0) | 2021.01.23 |
| [LeetCode] 21. Merge Two Sorted Lists (0) | 2021.01.23 |
| [LeetCode] 234. Palindrome Linked List (0) | 2021.01.23 |
문제 링크 : https://leetcode.com/problems/merge-two-sorted-lists/
Merge Two Sorted Lists - LeetCode
Level up your coding skills and quickly land a job. This is the best place to expand your knowledge and get prepared for your next interview.
leetcode.com
이 문제는 정렬된 두 개의 linked list를 merge하여 정렬된 linked list를 반환하는 문제이다.
풀이방법
두 리스트가 이미 정렬이 되어있기 때문에 merge sort와 같은 방법으로 풀었다.
두 리스트 중 작은 쪽을 merge_list에 복사하는 작업을 반복하여 merge_list를 반환하였다.
l1, l2 리스트의 연결 자체를 바꾸는 방법도 가능할 것 같은데 새로운 merge_list를 만드는 쪽이 더 쉽고 직관적이어서 다음과 같이 풀이하였다.
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def mergeTwoLists(self, l1: ListNode, l2: ListNode) -> ListNode:
# 둘 다 빈 리스트일 때
if not l1 and not l2:
return None
merge_list = ListNode()
# curr = 현재 List 위치
curr = merge_list
while l1 or l2:
if not l1:
curr.val = l2.val
l2 = l2.next
elif not l2:
curr.val = l1.val
l1 = l1.next
elif l1.val > l2.val:
curr.val = l2.val
l2 = l2.next
elif l1.val <= l2.val:
curr.val = l1.val
l1 = l1.next
if l1 or l2:
curr.next = ListNode()
curr = curr.next
return merge_list
| [LeetCode] 328. Odd Even Linked List (0) | 2021.01.24 |
|---|---|
| [LeetCode] 24. Swap Nodes in Pairs (0) | 2021.01.24 |
| [LeetCode] 2. Add Two Numbers (0) | 2021.01.23 |
| [LeetCode] 206. Reverse Linked List (0) | 2021.01.23 |
| [LeetCode] 234. Palindrome Linked List (0) | 2021.01.23 |
문제 링크 : https://leetcode.com/problems/palindrome-linked-list/
Palindrome Linked List - LeetCode
Level up your coding skills and quickly land a job. This is the best place to expand your knowledge and get prepared for your next interview.
leetcode.com
이 문제는 linked list가 주어졌을 때, 해당 list가 팰린드롬인지 확인하는 문제이다.
풀이방법
해당 list가 팰린드롬인지 아닌지 T/F를 판단하는 문제이기 때문에 linked list의 value를 새로운 list를 만들어서 저장 후 팰린드롬인지 확인하였다.
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def isPalindrome(self, head: ListNode) -> bool:
val_list = []
curr = head
while curr:
val_list.append(curr.val)
curr = curr.next
return val_list == val_list[::-1]
| [LeetCode] 328. Odd Even Linked List (0) | 2021.01.24 |
|---|---|
| [LeetCode] 24. Swap Nodes in Pairs (0) | 2021.01.24 |
| [LeetCode] 2. Add Two Numbers (0) | 2021.01.23 |
| [LeetCode] 206. Reverse Linked List (0) | 2021.01.23 |
| [LeetCode] 21. Merge Two Sorted Lists (0) | 2021.01.23 |
# 처리해야 할 문장을 파이썬 리스트에 옮기기
sentences=['i am hungry', 'i like apple', 'i am so happy']
# 파이썬 split() 메소드를 이용해 단어 단위로 문장을 쪼개기
word_list = 'i am hungry'.split()
print(word_list)
index_to_word={} # 빈 딕셔너리를 만들어서
# 단어들을 하나씩 채워보자. 순서는 중요하지 않다.
# <BOS>, <PAD>, <UNK>는 관례적으로 딕셔너리 맨 앞에 넣어준다
index_to_word[0]='<PAD>' # 패딩용 단어
index_to_word[1]='<BOS>' # 문장의 시작지점
index_to_word[2]='<UNK>' # 사전에 없는(Unknown) 단어
index_to_word[3]='i'
index_to_word[4]='like'
index_to_word[5]='hungry'
index_to_word[6]='so'
index_to_word[7]='apple'
index_to_word[8]='happy'
print(index_to_word)
word_to_index={word:index for index, word in index_to_word.items()}
print(word_to_index)
# 문장 1개를 활용할 딕셔너리와 함께 주면, 단어 인덱스 리스트로 변환해 주는 함수
# 단, 모든 문장은 <BOS>로 시작하는 것으로 합니다.
def get_encoded_sentence(sentence, word_to_index):
return [word_to_index['<BOS>']]+[word_to_index[word] if word in word_to_index else word_to_index['<UNK>'] for word in sentence.split()]
# 여러 개의 문장 리스트를 한꺼번에 숫자 텐서로 encode해 주는 함수
def get_encoded_sentences(sentences, word_to_index):
return [get_encoded_sentence(sentence, word_to_index) for sentence in sentences]
# 숫자 벡터로 encode된 문장을 원래대로 decode하는 함수
def get_decoded_sentence(encoded_sentence, index_to_word):
return ' '.join(index_to_word[index] if index in index_to_word else '<UNK>' for index in encoded_sentence[1:]) #[1:]를 통해 <BOS>를 제외
# 여러개의 숫자 벡터로 encode된 문장을 한꺼번에 원래대로 decode하는 함수
def get_decoded_sentences(encoded_sentences, index_to_word):
return [get_decoded_sentence(encoded_sentence, index_to_word) for encoded_sentence in encoded_sentences]
# raw_inputs의 문장의 길이를 PAD를 이용하여 동일하게 만들기
raw_inputs = keras.preprocessing.sequence.pad_sequences(raw_inputs,
value=word_to_index['<PAD>'],
padding='post',
maxlen=5)
print(raw_inputs)
# Embedding
import numpy as np
import tensorflow as tf
vocab_size = len(word_to_index) # 위 예시에서 딕셔너리에 포함된 단어 개수는 10
word_vector_dim = 4 # 그림과 같이 4차원의 워드벡터를 가정
embedding = tf.keras.layers.Embedding(input_dim=vocab_size, output_dim=word_vector_dim, mask_zero=True)
# keras.preprocessing.sequence.pad_sequences를 통해 word vector를 모두 일정길이로 맞춰주어야
# embedding 레이어의 input이 될 수 있음에 주의
raw_inputs = np.array(get_encoded_sentences(sentences, word_to_index))
raw_inputs = keras.preprocessing.sequence.pad_sequences(raw_inputs,
value=word_to_index['<PAD>'],
padding='post',
maxlen=5)
output = embedding(raw_inputs)
print(output)# RNN 모델을 사용하여 텍스트 데이터 처리
model = keras.Sequential()
model.add(keras.layers.Embedding(vocab_size, word_vector_dim, input_shape=(None,)))
model.add(keras.layers.LSTM(8)) # 가장 널리 쓰이는 RNN인 LSTM 레이어를 사용
model.add(keras.layers.Dense(8, activation='relu'))
model.add(keras.layers.Dense(1, activation='sigmoid'))
model.summary()텍스트를 처리하기 위해 RNN이 아니라 1-D CNN을 사용할 수도 있다. 텍스트는 시퀀스 데이터이기 때문에 1-D CNN 으로 문장 전체를 한꺼번에 한 방향으로 스캔하여 발견되는 특징을 추출해서 문장을 분류하는 방식으로 사용된다. CNN 계열은 RNN 계열보다 병렬처리가 효율적이기 때문에 학습 속도도 훨씬 빠르게 진행된다는 장점이 있다.
# 1DConv 모델을 사용하여 텍스트 데이터 처리
model = keras.Sequential()
model.add(keras.layers.Embedding(vocab_size, word_vector_dim, input_shape=(None,)))
model.add(keras.layers.Conv1D(16, 7, activation='relu'))
model.add(keras.layers.MaxPooling1D(5))
model.add(keras.layers.Conv1D(16, 7, activation='relu'))
model.add(keras.layers.GlobalMaxPooling1D())
model.add(keras.layers.Dense(8, activation='relu'))
model.add(keras.layers.Dense(1, activation='sigmoid'))
model.summary()아주 간단히는 GlobalMaxPooling1D() 레이어 하나만 사용하는 방법도 생각할 수 있다. 이 방식은 전체 문장 중 가장 중요한 단 하나의 특징만을 추출해서 문장의 긍정/부정을 평가하는 방식이다.
# GlobalMaxPooling1D 모델을 사용하여 텍스트 데이터 처리
model = keras.Sequential()
model.add(keras.layers.Embedding(vocab_size, word_vector_dim, input_shape=(None,)))
model.add(keras.layers.GlobalMaxPooling1D())
model.add(keras.layers.Dense(8, activation='relu'))
model.add(keras.layers.Dense(1, activation='sigmoid'))
model.summary()이 외에도 1-D CNN과 RNN을 섞어 쓴다거나, FFN(FeedForword Network) 레이어만으로 구성하거나, Transformer 레이어를 쓰는 등 다양한 시도를 해볼 수 있다.
IMDB Large Movie Dataset은 50000개의 영어로 작성된 영화 리뷰 텍스트로 구성되어 있으며, 긍정은 1, 부정은 0의 라벨이 달려있다. 이 중 25000개가 훈련용 데이터, 나머지 25000개를 테스트 데이터로 사용하도록 지정되어 있다.
import tensorflow as tf
from tensorflow import keras
import numpy as np
print(tf.__version__)
imdb = keras.datasets.imdb
# IMDB 데이터셋 다운로드
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=10000)
print("훈련 샘플 개수: {}, 테스트 개수: {}".format(len(x_train), len(x_test)))
# 데이터 확인
print(x_train[0]) # 1번째 리뷰데이터
print('라벨: ', y_train[0]) # 1번째 리뷰데이터의 라벨
print('1번째 리뷰 문장 길이: ', len(x_train[0]))
# word_index 가져오기
word_to_index = imdb.get_word_index()
index_to_word = {index:word for word, index in word_to_index.items()}
print(index_to_word[1]) # 'the' 가 출력
print(word_to_index['the']) # 1 이 출력
# decoding
print(get_decoded_sentence(x_train[0], index_to_word))
print('라벨: ', y_train[0]) # 1번째 리뷰데이터의 라벨
# 텍스트데이터 문장길이의 리스트를 생성한 후
total_data_text = list(x_train) + list(x_test)
# 문장길이의 평균값, 최대값, 표준편차를 계산
num_tokens = [len(tokens) for tokens in total_data_text]
num_tokens = np.array(num_tokens)
print('문장길이 평균 : ', np.mean(num_tokens))
print('문장길이 최대 : ', np.max(num_tokens))
print('문장길이 표준편차 : ', np.std(num_tokens))
# 예를들어, 최대 길이를 (평균 + 2*표준편차)로 한다면,
max_tokens = np.mean(num_tokens) + 2 * np.std(num_tokens)
maxlen = int(max_tokens)
print('pad_sequences maxlen : ', maxlen)
print('전체 문장의 {}%가 maxlen 설정값 이내에 포함됩니다. '.format(np.sum(num_tokens < max_tokens) / len(num_tokens)))
# padding
x_train = keras.preprocessing.sequence.pad_sequences(x_train,
value=word_to_index["<PAD>"],
padding='post', # 혹은 'pre'
maxlen=maxlen)
x_test = keras.preprocessing.sequence.pad_sequences(x_test,
value=word_to_index["<PAD>"],
padding='post', # 혹은 'pre'
maxlen=maxlen)
print(x_train.shape)vocab_size = 10000 # 어휘 사전의 크기입니다(10,000개의 단어)
word_vector_dim = 16 # 워드 벡터의 차원수 (변경가능한 하이퍼파라미터)
# model 설계
model = keras.Sequential()
model.add(keras.layers.Embedding(vocab_size, word_vector_dim, input_shape=(None,)))
model.add(keras.layers.LSTM(8)) # 가장 널리 쓰이는 RNN인 LSTM 레이어를 사용
model.add(keras.layers.Dense(8, activation='relu'))
model.add(keras.layers.Dense(1, activation='sigmoid')) # 최종 출력은 긍정/부정을 나타내는 1dim
model.summary()
# validation set 10000건 분리
x_val = x_train[:10000]
y_val = y_train[:10000]
# validation set을 제외한 나머지 15000건
partial_x_train = x_train[10000:]
partial_y_train = y_train[10000:]
print(partial_x_train.shape)
print(partial_y_train.shape)
# 모델 학습
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
epochs=20
history = model.fit(partial_x_train,
partial_y_train,
epochs=epochs,
batch_size=512,
validation_data=(x_val, y_val),
verbose=1)
# 모델 평가
results = model.evaluate(x_test, y_test, verbose=2)
print(results)
# 모델의 fitting 과정 중의 정보들이 history 변수에 저장
history_dict = history.history
print(history_dict.keys()) # epoch에 따른 그래프를 그려볼 수 있는 항목들
# 도식화 Training and Validation loss
import matplotlib.pyplot as plt
acc = history_dict['accuracy']
val_acc = history_dict['val_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
# "bo"는 "파란색 점"입니다
plt.plot(epochs, loss, 'bo', label='Training loss')
# b는 "파란 실선"입니다
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
# Training and Validation accuracy
plt.clf() # 그림을 초기화
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()pip install gensim : 워드벡터를 다루는데 유용한 패키지
# 임베딩 레이어 생성
embedding_layer = model.layers[0]
weights = embedding_layer.get_weights()[0]
print(weights.shape) # shape: (vocab_size, embedding_dim)
# 학습한 Embedding 파라미터를 저장
import os
word2vec_file_path = os.getenv('HOME')+'/aiffel/sentiment_classification/word2vec.txt'
f = open(word2vec_file_path, 'w')
f.write('{} {}\n'.format(vocab_size-4, word_vector_dim)) # 몇개의 벡터를 얼마 사이즈로 기재할지
# 단어 개수(에서 특수문자 4개는 제외하고)만큼의 워드 벡터를 파일에 기록
vectors = model.get_weights()[0]
for i in range(4,vocab_size):
f.write('{} {}\n'.format(index_to_word[i], ' '.join(map(str, list(vectors[i, :])))))
f.close()
# gensim 에서 제공하는 패키지를 이용하여 임베딩 파라미터를 word vector로 사용
from gensim.models.keyedvectors import Word2VecKeyedVectors
word_vectors = Word2VecKeyedVectors.load_word2vec_format(word2vec_file_path, binary=False)
vector = word_vectors['computer']
vector
# 단어 유사도 분석
word_vectors.similar_by_word("love")감성분류 태스크를 잠깐 학습한 것 만으로는 워드벡터가 유의미하게 학습되기 어려운 것 같다. 이 정도의 훈련 데이터로는 워드벡터를 정교하게 학습시키기 어렵다고 한다. 따라서 구글에서 제공하는 Word2Vec라는 사전 학습된 워드 임베딩 모델을 활용해보자. 다운로드
# 모델 불러오기
from gensim.models import KeyedVectors
word2vec_path = os.getenv('HOME')+'/aiffel/sentiment_classification/GoogleNews-vectors-negative300.bin.gz'
word2vec = KeyedVectors.load_word2vec_format(word2vec_path, binary=True, limit=None)
vector = word2vec['computer']
vector # 300dim의 워드 벡터. limit으로 조건을 주어 로딩 가능
# 단어 유사도 분석
word2vec.similar_by_word("love")
# 임베딩 레이어 변경
vocab_size = 10000 # 어휘 사전의 크기입니다(10,000개의 단어)
word_vector_dim = 300 # 워드 벡터의 차원수 (변경가능한 하이퍼파라미터)
embedding_matrix = np.random.rand(vocab_size, word_vector_dim)
# embedding_matrix에 Word2Vec 워드벡터를 단어 하나씩마다 차례차례 카피
for i in range(4,vocab_size):
if index_to_word[i] in word2vec:
embedding_matrix[i] = word2vec[index_to_word[i]]
# 모델 설계
from tensorflow.keras.initializers import Constant
vocab_size = 10000 # 어휘 사전의 크기입니다(10,000개의 단어)
word_vector_dim = 300 # 워드 벡터의 차원수 (변경가능한 하이퍼파라미터)
# 모델 구성
model = keras.Sequential()
model.add(keras.layers.Embedding(vocab_size,
word_vector_dim,
embeddings_initializer=Constant(embedding_matrix), # 카피한 임베딩을 여기서 활용
input_length=maxlen,
trainable=True)) # trainable을 True로 주면 Fine-tuning
model.add(keras.layers.Conv1D(16, 7, activation='relu'))
model.add(keras.layers.MaxPooling1D(5))
model.add(keras.layers.Conv1D(16, 7, activation='relu'))
model.add(keras.layers.GlobalMaxPooling1D())
model.add(keras.layers.Dense(8, activation='relu'))
model.add(keras.layers.Dense(1, activation='sigmoid'))
model.summary()
# 모델 학습
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
epochs=20
history = model.fit(partial_x_train,
partial_y_train,
epochs=epochs,
batch_size=512,
validation_data=(x_val, y_val),
verbose=1)
# 모델 평가
results = model.evaluate(x_test, y_test, verbose=2)
print(results)이버 영화리뷰 감성분석 도전하기import pandas as pd
import urllib.request
%matplotlib inline
import matplotlib.pyplot as plt
import re
from konlpy.tag import Okt
from tensorflow import keras
from tensorflow.keras.preprocessing.text import Tokenizer
import numpy as np
from tensorflow.keras.preprocessing.sequence import pad_sequences
from collections import Counter
import os
# 데이터 읽기
train_data = pd.read_table('~/aiffel/sentiment_classification/ratings_train.txt')
test_data = pd.read_table('~/aiffel/sentiment_classification/ratings_test.txt')
train_data.head()data_loader를 직접 만들어보자. data_loader에서는 다음을 수행해야 한다.
from konlpy.tag import Mecab
tokenizer = Mecab()
stopwords = ['의','가','이','은','들','는','좀','잘','걍','과','도','를','으로','자','에','와','한','하다']
# load_data 함수
def load_data(train_data, test_data, num_words=10000):
train_data.drop_duplicates(subset=['document'], inplace=True)
train_data = train_data.dropna(how = 'any')
test_data.drop_duplicates(subset=['document'], inplace=True)
test_data = test_data.dropna(how = 'any')
x_train = []
for sentence in train_data['document']:
temp_x = tokenizer.morphs(sentence) # 토큰화
temp_x = [word for word in temp_x if word not in stopwords] # 불용어 제거
x_train.append(temp_x)
x_test = []
for sentence in test_data['document']:
temp_x = tokenizer.morphs(sentence) # 토큰화
temp_x = [word for word in temp_x if word not in stopwords] # 불용어 제거
x_test.append(temp_x)
words = np.concatenate(x_train).tolist()
counter = Counter(words)
counter = counter.most_common(10000-4)
vocab = ['<PAD>', '<BOS>', '<UNK>', '<UNUSED>'] + [key for key, _ in counter]
word_to_index = {word:index for index, word in enumerate(vocab)}
def wordlist_to_indexlist(wordlist):
return [word_to_index[word] if word in word_to_index else word_to_index['<UNK>'] for word in wordlist]
x_train = list(map(wordlist_to_indexlist, x_train))
x_test = list(map(wordlist_to_indexlist, x_test))
return x_train, np.array(list(train_data['label'])), x_test, np.array(list(test_data['label'])), word_to_index
x_train, y_train, x_test, y_test, word_to_index = load_data(train_data, test_data)
index_to_word = {index:word for word, index in word_to_index.items()}
# 문장 1개를 활용할 딕셔너리와 함께 주면, 단어 인덱스 리스트 벡터로 변환해 주는 함수
# 단, 모든 문장은 <BOS>로 시작
def get_encoded_sentence(sentence, word_to_index):
return [word_to_index['<BOS>']]+[word_to_index[word] if word in word_to_index else word_to_index['<UNK>'] for word in sentence.split()]
# 여러 개의 문장 리스트를 한꺼번에 단어 인덱스 리스트 벡터로 encode해 주는 함수
def get_encoded_sentences(sentences, word_to_index):
return [get_encoded_sentence(sentence, word_to_index) for sentence in sentences]
# 숫자 벡터로 encode된 문장을 원래대로 decode하는 함수
def get_decoded_sentence(encoded_sentence, index_to_word):
return ' '.join(index_to_word[index] if index in index_to_word else '<UNK>' for index in encoded_sentence[1:]) #[1:]를 통해 <BOS>를 제외
# 여러개의 숫자 벡터로 encode된 문장을 한꺼번에 원래대로 decode하는 함수
def get_decoded_sentences(encoded_sentences, index_to_word):
return [get_decoded_sentence(encoded_sentence, index_to_word) for encoded_sentence in encoded_sentences]
print("훈련 샘플 개수: {}, 테스트 개수: {}".format(len(x_train), len(x_test)))
# decoding
print(get_decoded_sentence(x_train[0], index_to_word))
print('라벨: ', y_train[0]) # 1번째 리뷰데이터의 라벨
# 텍스트데이터 문장길이의 리스트를 생성한 후
total_data_text = list(x_train) + list(x_test)
# 문장길이의 평균값, 최대값, 표준편차를 계산
num_tokens = [len(tokens) for tokens in total_data_text]
num_tokens = np.array(num_tokens)
print('문장길이 평균 : ', np.mean(num_tokens))
print('문장길이 최대 : ', np.max(num_tokens))
print('문장길이 표준편차 : ', np.std(num_tokens))
plt.clf()
plt.hist([len(s) for s in total_data_text], bins=100)
plt.xlabel('length of samples')
plt.ylabel('number of samples')
plt.show()
# 예를들어, 최대 길이를 (평균 + 2*표준편차)로 가정
max_tokens = np.mean(num_tokens) + 2 * np.std(num_tokens)
maxlen = int(max_tokens)
print('pad_sequences maxlen : ', maxlen)
print('전체 문장의 {}%가 maxlen 설정값 이내에 포함됩니다. '.format(np.sum(num_tokens < max_tokens) / len(num_tokens)))
# padding
x_train = keras.preprocessing.sequence.pad_sequences(x_train,
value=word_to_index["<PAD>"],
padding='pre', # 혹은 'pre'
maxlen=maxlen)
x_test = keras.preprocessing.sequence.pad_sequences(x_test,
value=word_to_index["<PAD>"],
padding='pre', # 혹은 'pre'
maxlen=maxlen)
print(x_train.shape)
vocab_size = 10000 # 어휘 사전의 크기입니다(10,000개의 단어)
word_vector_dim = 32 # 워드 벡터의 차원수 (변경가능한 하이퍼파라미터)
# 모델 설계
model = keras.Sequential()
model.add(keras.layers.Embedding(vocab_size, word_vector_dim, input_shape=(None,)))
model.add(keras.layers.LSTM(16))
model.add(keras.layers.Dense(8, activation='relu'))
model.add(keras.layers.Dense(1, activation='sigmoid'))
model.summary()
# validation set 10000건 분리
x_val = x_train[:10000]
y_val = y_train[:10000]
# validation set을 제외한 나머지 15000건
partial_x_train = x_train[10000:]
partial_y_train = y_train[10000:]
print(partial_x_train.shape)
print(partial_y_train.shape)
# 모델 학습
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
epochs=10
history = model.fit(partial_x_train,
partial_y_train,
epochs=epochs,
batch_size=512,
validation_data=(x_val, y_val),
verbose=1)
# 모델 평가
results = model.evaluate(x_test, y_test, verbose=2)
print(results)
# 모델의 fitting 과정 중의 정보들이 history 변수에 저장
history_dict = history.history
print(history_dict.keys()) # epoch에 따른 그래프를 그려볼 수 있는 항목들
acc = history_dict['accuracy']
val_acc = history_dict['val_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
# "bo"는 "파란색 점"
plt.plot(epochs, loss, 'bo', label='Training loss')
# b는 "파란 실선"
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
# Training and Validation accuracy
plt.clf() # 그림을 초기화
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()Pre-trained된 Word2Vec Embedding을 이용하여 정확도를 올려보자.
import gensim
word2vec_path = os.getenv('HOME')+'/aiffel/sentiment_classification/ko.bin'
pre_word2vec = gensim.models.Word2Vec.load(word2vec_path)
vector = pre_word2vec.wv.most_similar("강아지")
vector
pre_word2vec['강아지'].shape
# 임베딩 레이어 변경
vocab_size = 10000 # 어휘 사전의 크기입니다(10,000개의 단어)
word_vector_dim = 200 # 워드 벡터의 차원수 (변경가능한 하이퍼파라미터)
embedding_matrix = np.random.rand(vocab_size, word_vector_dim)
# embedding_matrix에 Word2Vec 워드벡터를 단어 하나씩마다 차례차례 카피
for i in range(4,vocab_size):
if index_to_word[i] in pre_word2vec:
embedding_matrix[i] = pre_word2vec[index_to_word[i]]
# 모델 설계
from tensorflow.keras.initializers import Constant
vocab_size = 10000 # 어휘 사전의 크기입니다(10,000개의 단어)
word_vector_dim = 200 # 워드 벡터의 차원수 (변경가능한 하이퍼파라미터)
# 모델 구성
model = keras.Sequential()
model.add(keras.layers.Embedding(vocab_size,
word_vector_dim,
embeddings_initializer=Constant(embedding_matrix), # 카피한 임베딩을 여기서 활용
input_length=maxlen,
trainable=True)) # trainable을 True로 주면 Fine-tuning
model.add(keras.layers.LSTM(16))
model.add(keras.layers.Dense(8, activation='relu'))
model.add(keras.layers.Dense(1, activation='sigmoid'))
model.summary()
# 모델 학습
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
epochs=15
history = model.fit(partial_x_train,
partial_y_train,
epochs=epochs,
batch_size=4096,
validation_data=(x_val, y_val),
verbose=1)
# 모델 평가
results = model.evaluate(x_test, y_test, verbose=2)
print(results)
# 모델의 fitting 과정 중의 정보들이 history 변수에 저장
history_dict = history.history
print(history_dict.keys()) # epoch에 따른 그래프를 그려볼 수 있는 항목들
# 도식화 Training and Validation loss
import matplotlib.pyplot as plt
acc = history_dict['accuracy']
val_acc = history_dict['val_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
# "bo"는 "파란색 점"입니다
plt.plot(epochs, loss, 'bo', label='Training loss')
# b는 "파란 실선"입니다
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
# Training and Validation accuracy
plt.clf() # 그림을 초기화합니다
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()유용한 링크
https://dbr.donga.com/article/view/1202/article_no/8891/ac/magazine
https://ratsgo.github.io/natural language processing/2019/09/12/embedding/ 한국어 임베딩
| [SSAC X AIFFEL] 작사가 인공지능 만들기 (0) | 2021.02.08 |
|---|---|
| [SSAC X AIFFEL] 인공지능 모델로 음성 단어 구분하기 (1) | 2021.01.29 |
| [SSAC X AIFFEL] 카메라 스티커 앱 만들기 첫걸음 (2) | 2021.01.13 |
| [SSAC X AIFFEL] 사이킷런(scikit-learn): Iris 품종 분류해보기 (0) | 2021.01.08 |
| [SSAC X AIFFEL] 첫 딥러닝 모델: 가위바위보 분류기 (0) | 2021.01.05 |
이 글은 42seoul의 ft_server 과제를 해결하기 위한 자료로 작성되었습니다.
참고문서(kkang) https://github.com/Kkan9ma/42cursus/tree/master/02_ft_server_docs
작동 환경 : masOS(Catalina) 10.15.5 / Windows10 WSL2 Ubuntu
Docker 설치
Container 생성
nginx 설치
SSL Protocol 사용
php-fpm 설치
MySQL과 phpmyadmin 설치
Wordpress 설치
Autoindex 적용
Docker 설치
Container 생성
Docker Container는 Docker image를 바탕으로 생성된다.
Docker image를 받은 후 docker run 명령어로 container를 생성할 수 있다.
Docker image를 받기 위해서는 docker pull 명령어를 사용하여 image를 다운로드 할 수 있다.
2.1 debian image pull 하기*
Mandatory Part에서 container의 OS는 debian buster 여야 한다고 명시되어 있다. 따라서 debian buster image를 pull 하여 container를 생성한다.
debian buster는 debian OS의 하나의 버전으로 debian 10에 해당하는 버전 이름이다.
Docker에선 pull 명령어를 사용하여 image를 다운로드 할 수 있다.
처음 docker images 명령어를 입력하면 아무것도 없는 것을 확인할 수 있다.

docker pull debian:buster 명령어를 입력하여 image를 다운로드 한다.

2.2 image 확인 및 containner 생성하기*
image 확인
docker images 명령어로 잘 다운로드 되었는지 확인한다.

container 생성
docker run -it -p 80:80 -p 443:443 —name test debian:buster 명령어로 container를 생성한다.

- docker run 명령어 형태
- `$ docker run [OPTIONS] IMAGE[:TAG|@DIGEST] [COMMAND] [ARG...]` (도커 홈페이지)
[OPTIONS]
-i : Keep STDIN open even if not attached (interactive의 약자로 docker 내부에서 표준입력으로 command를 입력받을 수 있도록 한다.)
-t : Allocate a pseudo-TTY (가상의 터미널을 사용)
--name : 컨테이너의 이름을 정하는 역할. 본 예시에선 test로 명명한다.
-p : Publish a container's port(s) to the host (컨테이너와 호스트의 포트를 연결해준다)http : 80번 port 사용
https : 443번 port 사용
container 확인
다른 터미널 탭을 띄워 docker ps 명령어를 통해 현재 container 상태를 확인할 수 있다.

container 에 접속한 상태에서 exit 명령어를 통하여 container 를 종료할 수 있다. 종료했을 경우에 docker ps -a 명령어를 통해 종료된 것을 확인할 수 있다.

container를 종료했을 때, container에 다시 접속하고 싶다면 아래 명령어로 가능하다.
(1)
- docker start 'CONTAINER ID'
- docker attach 'CONTAINER ID'
(2)
- docker start -i 'CONTAINER ID'nginx 설치
APT(Advanced Packaging Tool)을 이용하여 container 내부에서 과제를 해결하는데 필요한 프로그램들을 설치해준다.
apt-get update -y, apt-get upgrade -y 명령어를 통해 APT를 최신버전으로 업데이트 해준다.
3.1 nginx 설치하기*
apt-get install nginx -y 명령어로 nginx 를 설치해준다.
3.2 nginx 시작, 상태 조회하기*
nginx는 항상 background에서 작동하고 있어야 하는 프로그램이다.
etc/init.d 폴더에 daemon 형태로 프로그램을 저장해둔다.
daemon 형태로 저장된 프로그램을 조작하는 명령어는 service 이다.
service nginx start // nginx 시작
service nginx status // nginx 상태 조회service 명령어를 이용하여 nginx 를 시작한 후, 브라우저에서 localhost 또는 localhost:80 으로 접속하여 상태를 확인한다.

해당 페이지가 제대로 뜨지 않을 경우, https 로 접속하지 않았는지 확인
만약 해당 방법으로도 조회가 되지 않을 경우, apt-get install curl 명령어를 이용하여 curl 설치하여 curl localhost 명령어를 사용하여 소스가 조회되는지 확인한다.
SSL Protocol 사용
4.1 SSL Protocol 이란?
전송 계층 보안(Transport Layer Security, TLS, 과거 명칭: 보안 소켓 레이어/Secure Sockets Layer, SSL)은 컴퓨터 네트워크에 통신 보안을 제공하기 위해 설계된 암호 규약이다.
자세한 내용은 링크 참조
4.2 SSL 인증서 만들기*
인증서는 공개키 기반 구조이므로, 개인키부터 만들어 진행해야 한다.
인증서를 만드는 과정은 개인키 생성, CSR 만들기, 인증서 만들기 순서로 진행한다.
CSR(인증서 서명 요청 : Certificate Signing Request)을 만들기위해 openssl을 설치한다.
apt-get install openssl -y
openssl 명령어 구조
openssl req -out <CSR 파일> -keyout <개인키 파일> rsa:<키 비트 수>
openssl req -newkey rsa:4096 -nodes -x509 -keyout localhost.dev.key -out localhost.dev.crt -days 365 -subj "/C=KR/ST=Seoul/L=Seoul/O=42Seoul/OU=Hyulee/CN=localhost"openssl 옵션
.key 파일명을 지정.crt 파일명을 지정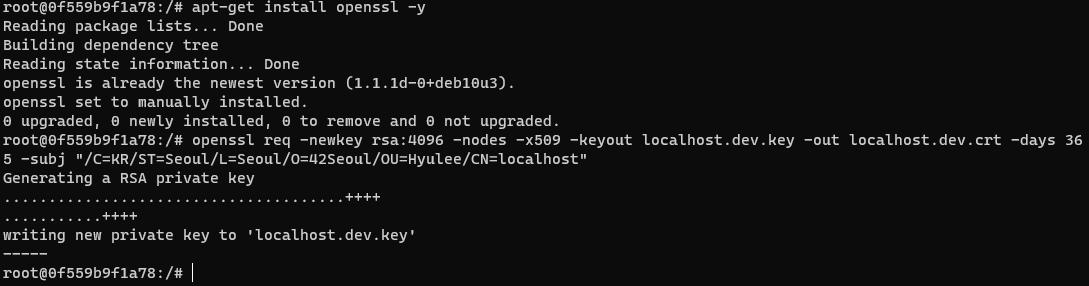
4.3 Nginx에 SSL Protocol을 추가하기*
우선 mv 명령어로 만든 키를 지정된 위치로 옮긴 후, 보안을 위해 권한 설정을 해준다.
mv localhost.dev.crt etc/ssl/certs/
mv localhost.dev.key etc/ssl/private/
chmod 600 etc/ssl/certs/localhost.dev.crt etc/ssl/private/localhost.dev.key현재 http로는 접속 가능하나 https로의 접속은 불가능한 상태이다. 따라서 https로 접속을 가능하게 하기 위해 nginx 설정을 바꾸어준다.
/etc/nginx/sites-available/default 파일을 수정하여 SSL Protocol 설정 뿐만 아니라 http로 접속했을 때, https로 redirection 해주는 작업까지 필요로 한다.
server {
listen 80 default_server;
listen [::]:80 default_server;
server_name localhost;
return 301 https://$server_name$request_uri;
root /var/www/html;
# Add index.php to the list if you are using PHP
index index.html index.htm index.php;
location / {
# First attempt to serve request as file, then
# as directory, then fall back to displaying a 404.
try_files $uri $uri/ =404;
}
# pass PHP scripts to FastCGI server
#
#location ~ \.php$ {
# include snippets/fastcgi-php.conf;
#
# # With php-fpm (or other unix sockets):
# fastcgi_pass unix:/run/php/php7.3-fpm.sock;
# # With php-cgi (or other tcp sockets):
# fastcgi_pass 127.0.0.1:9000;
#}
# deny access to .htaccess files, if Apache's document root
# concurs with nginx's one
#
#location ~ /\.ht {
# deny all;
#}
}
server {
# SSL configuration
listen 443;
listen [::]:443;
ssl on;
ssl_certificate /etc/ssl/certs/localhost.dev.crt;
ssl_certificate_key /etc/ssl/private/localhost.dev.key;
root /var/www/html;
# Add index.php to the list if you are using PHP
index index.html index.htm index.php;
server_name _;
location / {
# First attempt to serve request as file, then
# as directory, then fall back to displaying a 404.
try_files $uri $uri/ =404;
}
# pass PHP scripts to FastCGI server
#
# location ~ \.php$ {
# # include snippets/fastcgi-php.conf;
# # With php-fpm (or other unix sockets):
# fastcgi_pass unix:/run/php/php7.3-fpm.sock;
# # With php-cgi (or other tcp sockets):
# fastcgi_pass 127.0.0.1:9000;
}
# deny access to .htaccess files, if Apache's document root
# concurs with nginx's one
#
#location ~ /\.ht {
# deny all;
#}
}설정 후 service nginx reload 명령어를 통해 설정이 적용된 nginx를 다시 불러온다.
http로 접속해도 https로 접속되는 것을 확인할 수 있다.
접속했을 때 경고가 뜨는 원인은 공인된 인증서가 아니기 때문이다.
php-fpm 설치
서버와 다른 프로그램간의 상호작용을 위해 먼저 php-fpm을 설치한다.
5.1 PHP 란?
php는 프로그래밍 언어의 일종으로, 원래는 동적 웹 페이지를 만들기 위해 설계되었으며 이를 구현하기 위해 PHP로 작성된 코드를 HTML 소스 문서 안에 넣으면 PHP 처리 기능이 있는 웹 서버에서 해당 코드를 인식하여 작성자가 원하는 웹 페이지를 생성한다. 근래에는 PHP 코드와 HTML을 별도 파일로 분리하여 작성하는 경우가 일반적이며, PHP 또한 웹서버가 아닌 php-fpm(PHP FastCGI Process Manager)을 통해 실행하는 경우가 늘어나고 있다.
5.1.1 php-fpm 이란?*
php-fpm( PHP FastCGI Process Manager)
php-fpm은 FastCGI다.
요청할 때마다 새로운 프로세스 생성하는 CGI는 상대적으로 느리다.
그래서 요청할 때마다 새로운 프로세스를 생성하는 것이 아니라 이미 생성한 프로세스를 재활용하는 방법을 사용하는 것이 고안되었다.
즉, CGI보다 좀 더 빠른 버전이라고 할 수 있다.
php-fpm는 php를 FastCGI 방식으로 동작하도록 하는 솔루션인데, 주로 Nginx와 함께 사용된다.
5.2 CGI 란?*
CGI(Common Gate Interface)란 서버와 외부 스크립트 또는 프로그램과 상호작용할 때 이루어지는 입출력을 정의한 표준이다.
이 표준에 맞추어 만들어진 것이 CGI 스크립트 또는 CGI 프로그램으로, CGI 프로그램은 어떤 프로그래밍 언어로도 만들 수 있다.
두 개 이상의 컴퓨터간의 자료들을 주고받는 프로그램 또는 주고받는 것 자체를 의미한다고 할 수 있다.
웹페이지는 HTML언어에 의해서 기본적으로 만들어진다. 하지만 HTML만으로 모든 정보를 다 처리할 수는 없다. 왜냐하면 HTML언어는 서버로부터 HTML문서를 보여주는 역할만 할 뿐, 사용자의 동작을 바로 반영하여 업로드할 수는 없기 때문이다.
따라서 홈페이지를 서버-클라이언트 모두 양방향으로 구성할 필요성이 있는 것이다.
이를 해결한 여러 방법 중 하나가 외부 프로그램을 수행하여 그 결과를 HTML형태로 보여주는 방식인 CGI다.
넓은 의미로는 CGI를 수행하는 프로그램을 CGI라고 하기도 한다.
그 대표적인 예가 방명록, 게시판, 메모장 등이다.
5.3 php-fpm 설치하기*
apt-get install php-fpm 명령어로 php-fpm을 설치한다.
설치가 완료되었으면, nginx의 default 파일을 수정하여 php-fpm과 연동한다.
5.4 nginx 에 적용하기*
apt-get install php-fpm 명령어로 php-fpm을 설치한다.
설치가 완료되었으면, nginx의 default 파일을 수정하여 php-fpm과 연동한다.
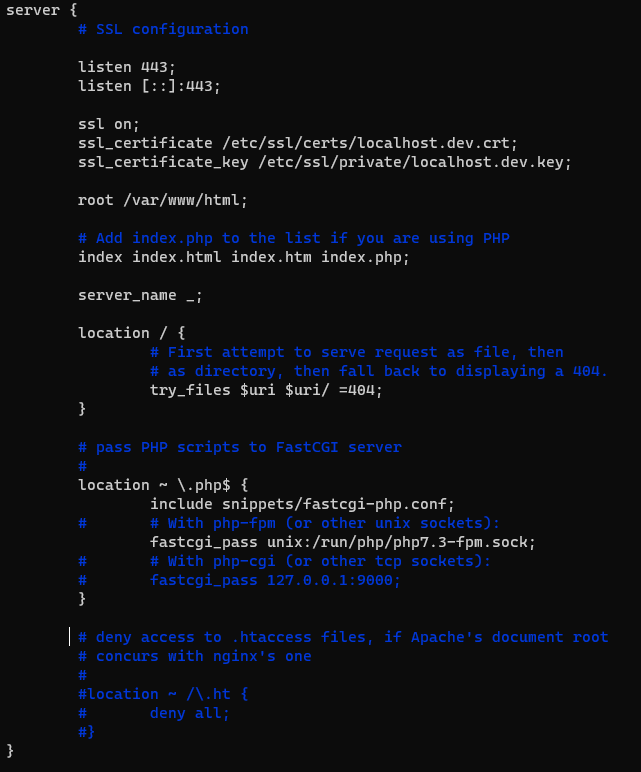
fastcgi_pass 편집 시, 설치된 php-fpm의 버전과 맞게 기재해주어야 한다. 이번 케이스에선 설치된 php-fpm의 버전은 7.3이므로, php7.3-fpm.sock으로 설정하였다.
또한 현재 상황은 redirection된 경우이기 때문에 https 설정인 listen 443이 있는 블록에 설정해주어야 한다.
5.5 적용되었는지 확인하기*
service php7.3-fpm start 명령어로 php-fpm 을 실행시킨다.
phpinfo()는 PHP 정보와 설정을 표로 정리해서 보여주는 함수이다.
echo "<?php phpinfo(); ?>" > /var/www/html/phpinfo.php 명령어를 통해 /var/www/html에 phpinfo.php 라는 파일을 만들어 내용을 작성한다.
service nginx reload 명령어로 nginx를 재시작 한다.
https://localhost/phpinfo.php 로 접속하여 잘 적용되었는지 확인한다.
MySQL과 phpmyadmin 설치
SQL Database가 Wordpress와 phpmyadmin과 연동될 수 있도록 MySQL과 phpmyadmin을 설치한다.
6.1 MySQL 이란?*
MySQL은 데이터베이스 관리 시스템이다.
데이터베이스 관리 시스템(영어: database management system, DBMS)은 다수의 사용자들이 데이터베이스 내의 데이터를 접근할 수 있도록 해주는 소프트웨어 도구의 집합이다.
DBMS은 사용자 또는 다른 프로그램의 요구를 처리하고 적절히 응답하여 데이터를 사용할 수 있도록 해준다.
6.2 phpmyadmin 이란?*
phpMyAdmin은 MySQL을 월드 와이드 웹 상에서 관리할 목적으로 PHP로 작성한 오픈 소스 도구이다.
데이터베이스, 테이블, 필드, 열의 작성, 수정, 삭제, 또 SQL 상태 실행, 사용자 및 사용 권한 관리 등의 다양한 작업을 수행할 수 있다. 특히 웹 호스팅 서비스를 위한 가장 대중적인 MySQL 관리 도구 가운데 하나가 되었다.
6.3 설치하기*
6.3.1 MariaDB(MySQL) 설치*
Debian OS에서는 MySQL과 거의 동일한 프로그램인 MariaDB를 default로 사용하고 있다. 따라서 MariaDB를 설치한다.
apt-get install mariadb-server php-mysql 명령어로 MariaDB를 설치할 수 있다.
6.3.2 phpmyadmin 설치*
phpmyadmin은 APT로 설치할 수 없다. 따라서 wget이라는 프로그램을 이용하여 URL로 부터 파일을 다운받아서 설치한다.
apt-get install wget // 명령어로 wget을 설치한다.
wget https://files.phpmyadmin.net/phpMyAdmin/5.0.2/phpMyAdmin-5.0.2-all-languages.tar.gz
tar -xvf phpMyAdmin-5.0.2-all-languages.tar.gz // 명령어로 압축을 푼다.tar 명렁어의 주요 옵션은 아래와 같다.
- 기본 형식: tar [OPTION...] [FILE]...
- 옵션
-f : 대상 tar 아카이브 지정. (기본 옵션)
-c : tar 아카이브 생성. 기존 아카이브 덮어 쓰기. (파일 묶을 때 사용)
-x : tar 아카이브에서 파일 추출. (파일 풀 때 사용)
-v : 처리되는 과정(파일 정보)을 자세하게 나열.
-z : gzip 압축 적용 옵션.
-j : bzip2 압축 적용 옵션.
-t : tar 아카이브에 포함된 내용 확인.
-C : 대상 디렉토리 경로 지정.
-A : 지정된 파일을 tar 아카이브에 추가.
-d : tar 아카이브와 파일 시스템 간 차이점 검색.
-r : tar 아카이브의 마지막에 파일들 추가.
-u : tar 아카이브의 마지막에 파일들 추가.
-k : tar 아카이브 추출 시, 기존 파일 유지.
-U : tar 아카이브 추출 전, 기존 파일 삭제.
-w : 모든 진행 과정에 대해 확인 요청. (interactive)
-e : 첫 번째 에러 발생 시 중지.phpmyadmin을 설치할 때 파일의 이름은 전통적으로 phpmyadmin으로 지어졌다.
mv phpMyAdmin-5.0.2-all-languages /var/www/html/phpmyadmin 명령어로 phpmyadmin의 폴더명 변경과 폴더 이동을 해준다.
rm phpMyAdmin-5.0.2-all-languages.tar.gz 명령어로 불필요한 압축파일은 삭제해준다.
6.4 phpmyadmin 설정*
phpmyadmin 내에 config.sample.inc.php 의 샘플 파일을 복사하여 config.inc.php 파일을 만든다.
6.4.1 복사하기*
cp /var/www/html/phpmyadmin/config.sample.inc.php /var/www/html/phpmyadmin/config.inc.php
6.4.2 편집하기*
vim /var/www/html/phpmyadmin/config.inc.php
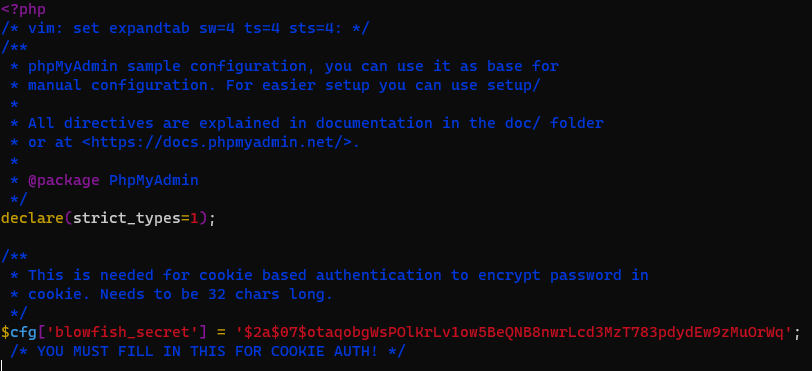
파일 내부의 내용 중, blowfish_secret(암호화 문자열) 부분에 대한 설정이 필요하다.
config.inc.php 파일 내 $cfg['blowfish_secret'] = ''; /* YOU MUST FILL IN THIS FOR COOKIE AUTH! */ 부분을 편집할 것이며, ''에 비밀번호를 넣으면 된다.
암호화 문자열은 hash 방식으로 만들어진 password를 넣어야 하며, 링크 등을 통해 만들 수 있다.
6.4.3 설정 적용하기*
지금까지 한 설정을 적용하기 위해 필요한 service들을 reload 해준다.
service nginx reload
service php7.3-fpm restart6.5 데이터 테이블 만들기*
이제 Datatable을 만들기 위해서 service mysql start 명령어로 MySQL을 작동시킨다.
6.5.1 MySQL에 테이블 불러오기*
MySQL로 데이터를 관리하기 위해 mysql < var/www/html/phpmyadmin/sql/create_tables.sql -u root --skip-password 명령어로 테이블을 불러온다.
< 로 외부 .sql 파일에서 데이터를 불러올 수가 있다.
-u 옵션으로 user는 root로 설정한다.--skip-password6.5.2 MySQL 서버 관리하기*
mysqladmin -u root -p password 명령어로 MySQL 계정의 패스워드를 설정해준다.
mysqladmin - MySQL 서버를 관리하기 위한 클라이언트이다.u 옵션: 서버 접속 시 사용하는 mysql 사용자 이름p 옵션: 서버 접속 시 사용하는 패스워드.
기존 비밀번호는 없으니 enter로 넘어가고, new password와 confirm new password 창엔 원하는 비밀번호를 입력한다.
입력하지 않는 경우엔 error 발생 가능.
(참고)단, 비밀번호 설정을 하지 않는 방법도 있다.
var/www/html/phpmyadmin/config.inc.php 내용 중, AllowNoPassword를 default인 false에서 true로 변경해주면 비밀번호 없이 접속이 가능하다.6.5.3 MySQL 접속하기*
command line에 mysql을 입력하여 MySQL에 접속한다. 단, 패스워드가 있을 경우, mysql -p${PASSWORD}로 접속할 수 있다.
show databases; // database 조회
CREATE DATABASE IF NOT EXISTS wordpress; // 워드프레스를 위한 DB 만들기
Grant all privileges on *.* to ‘user’@‘%’ identified by ‘설정한비밀번호’ with grant option;
flush privileges;
show databases; // 변경되었는지 조회
exit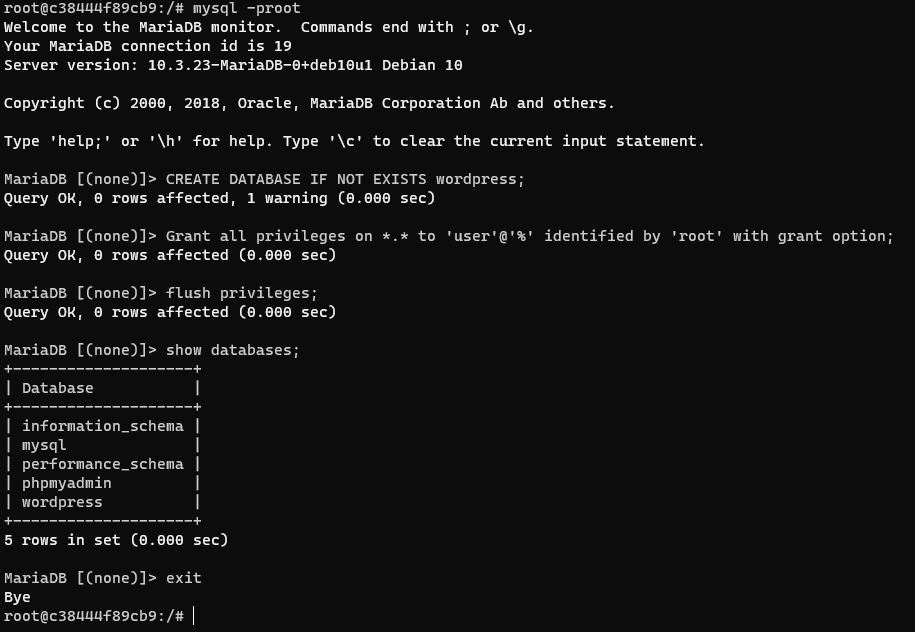
MySQL 문법
GRANT 권한 ON 데이터베이스.테이블 TO '아이디'@'호스트' IDENTIFIED BY '비밀번호'(*.*,class.*)
아이디@호스트 중에서 호스트는 접속자가 사용하는 머신의 IP를 의미한다. IP를 특정하지 않으려면 ‘%’를 사용dev@123.100.100.100 : IP 123.100.100.100인 머신에서 접속한 ID devdev@% : IP 관계없이 ID가 dev인 사용자
flush privileges;
FLUSH PRIVILEGES는 grant 테이블을 reload함으로서 변경 사항을 즉시 반영하도록 한다.6.5.4 phpmyadmin 작동 확인*
service nginx reload 명령어로 변경된 사항을 다시 적용한다.
localhost/phpmyadmin 에 접속하여 확인한다.
아이디는 root, 비밀번호는 mysql에서 설정한 비밀번호이다.
Wordpress 설치
7.1 Wordpress 설치하기
Wordpress도 마찬가지로 wget을 이용하여 설치를 진행한다.
wget https://wordpress.org/latest.tar.gz
tar -xvf latest.tar.gz
mv wordpress/ var/www/html/
chown -R www-data:www-data /var/www/html/wordpresschown: chown은 파일을 소유하는 유저와 그룹을 변경하기 위해서 사용한다. (출처)
wordpress 를 사용하기 위해 폴더에 접근권한을 바꾸어준다.7.2 Wordpress 설정하기*
Wordpress도 마찬가지로 샘플 설정 파일이 주어지므로 수정하여 사용한다.
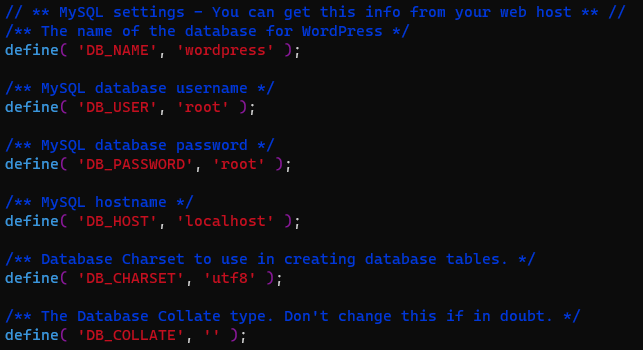
cp var/www/html/wordpress/wp-config-sample.php var/www/html/wordpress/wp-config.php
wp-config.php 파일을 본인의 password에 맞게 수정한다.
7.3 Wordpress 작동 확인*
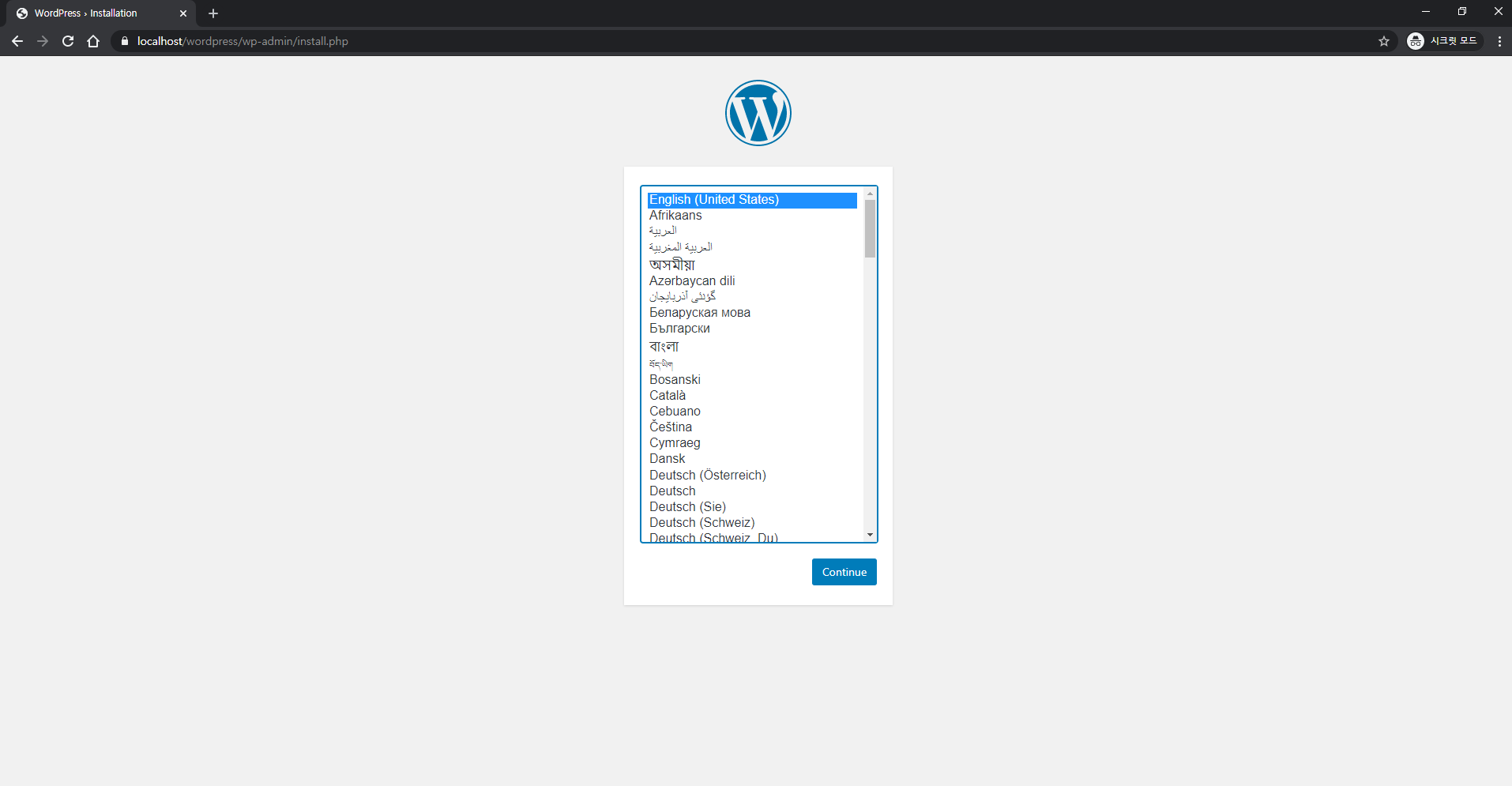
service nginx reload 명령어로 변경사항을 적용시켜준다.
localhost/wordpress 에 접속하면 다음과 같은 초기 설정 화면을 볼 수 있다.
페이지를 만든 후 phpmyadmin에서 wordpress 데이터가 제대로 생성되었는지 확인한다.
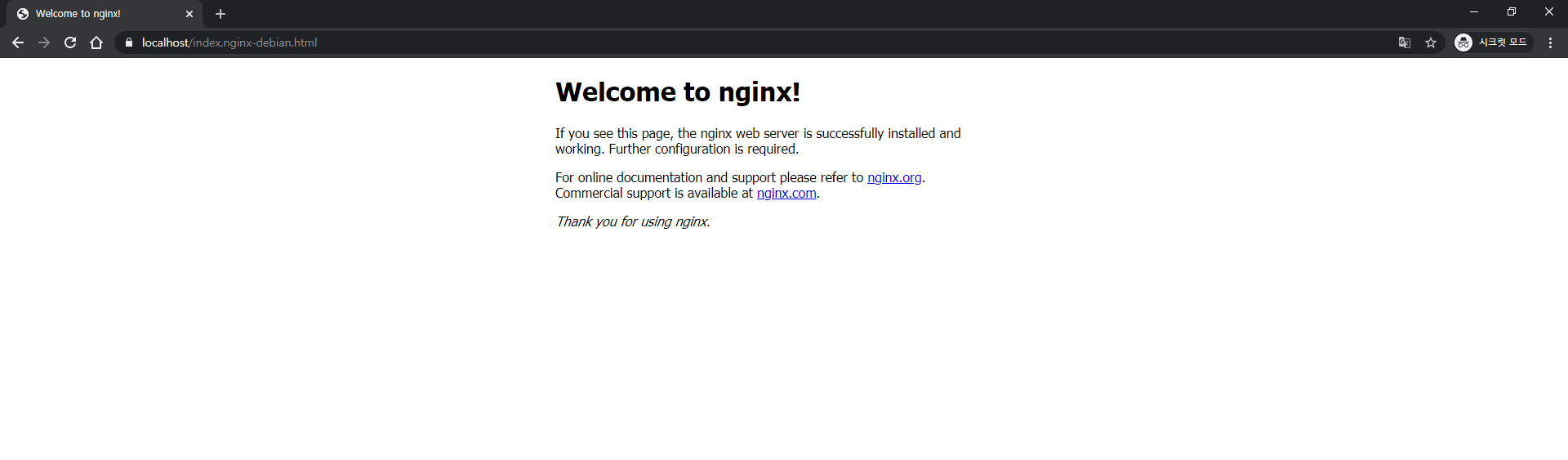
Autoindex 적용하기
현재 localhost로 접속하면 다음과 같은 화면을 볼 수 있다.
autoindex란, 인덱스 페이지를 디렉토리 목록으로 나타내는 방법을 말한다.
/etc/nginx/sites-available/default 파일을 편집하여 autoindex 기능을 활성화시킬 수 있다.
/etc/nginx/sites-available/default 파일을 다음과 같이 수정해준다.
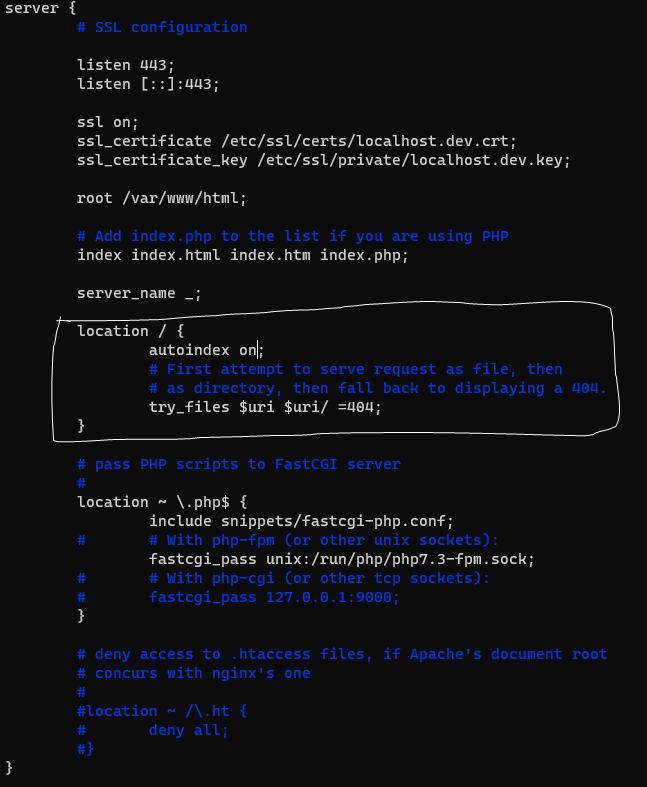
service nginx reload 명령어로 변경사항을 적용시켜준 후 localhost 에 접속하면 autoindex가 적용된 화면을 볼 수 있다.

서비스 하기 전에 도커 맛을 쬐끔만 봐라
IP 주소(IP Address)란 무엇인가?

IP 주소는 네트워크 부분과 호스트 부분으로 나뉜다. 네트워크 주소는 특정 네트워크의 주소이고 라우팅시 사용하며, 호스트 주소는 네트워크에 속한 호스트의 주소이다. 같은 네트워크에 있다면 라우터를 거치지 않고도 통신이 가능한데, 이러한 영역을 broadcast 영역이라고 한다.
IP 주소는 유일성을 보장하기 위해 국제 표준화 기구에서 전체 주소를 관리하고 할당해 중복 주소의 사용을 원천적으로 차단한다. IP 프로토콜이 처음 개발될 당시에는 현재처럼 폭넓게 활용되리라 예측하지 못했다. 따라서 IP 주소로 표현할 수 있는 최대 주소 공간의 크기를 32비트로 제한함으로써 확장성에 많은 문제점이 야기되고 있다. 이를 해결하려고 새로운 프로토콜 IPv6(Internet Protocol Version 6)에서는 주소 표현 공간을 128비트로 확장했다. 그리고 현재의 IP 프로토콜은 IPv6과 구분하기 위해 IPv4로 표현한다.
IPv4는 인터넷 프로토콜의 4번째 판이며, 전 세계적으로 사용된 첫 번째 인터넷 프로토콜이다. IPv4의 주소체계는 총 12자리이며 네 부분으로 나뉜다. 각 부분은 0~255까지 3자리의 수로 표현된다. IPv4 주소는 32비트로 구성되어 있으며, 현재 인터넷 사용자의 증가로 인해 주소공간의 고갈에 대한 우려가 높아지고 있다. 이에 따라 대안으로 128비트 주소체계를 갖는 IPv6가 등장하였다.
IPv6(Internet Protocol version 6)는 인터넷 프로토콜 스택 중 네트워크 계층의 프로토콜로서 버전 6 인터넷 프로토콜로 제정된 차세대 인터넷 프로토콜을 말한다. IPv6와 기존 IPv4 사이의 가장 큰 차이점은 바로 IP 주소의 길이가 128비트로 늘어났다는 점이다.
넷마스크(Netmask)란 무엇인가?
넷마스크란 IP 주소의 네트워크 부분을 가리거나 걸러서 호스트 컴퓨터의 주소 부분만이 남도록 하기 위해 0과 1이 조합되어 있는 문자열이다.
IP 주소와 넷마스크를 AND연산하면 네트워크 주소를 얻을 수 있다.

subnet이란 무엇인가?
subnet의 broadcast address란 무엇인가?
Netmask로 IP Address를 나타내기 위한 방식에는 어떤 것이 있는가?
Public IP와 Private IP는 어떻게 다른가?
공인 IP (Public IP)는 인터넷 사용자의 로컬 네트워크를 식별하기 위해 ISP(인터넷 서비스 공급자)가 제공하는 IP 주소이다. 공용 IP 주소라고도 불리우며 외부에 공개되어 있는 IP 주소이다.
공인 IP 주소가 외부에 공개되어 있기에 인터넷에 연결된 다른 PC로부터의 접근이 가능하다. 따라서 공인 IP 주소를 사용하는 경우에는 방화벽 등의 보안 프로그램을 설치할 필요가 있다.
사설 IP (Private IP)는 일반 가정이나 회사 내 등에 할당된 네크워크의 IP 주소이며, 로컬 IP 또는 가상 IP 라고도 한다. IPv4의 주소부족으로 인해 서브넷팅된 IP 이기 때문에 라우터에 의해 로컬 네트워크 상의 PC 나 장치에 할당된다.
사설 IP 주소대역은 다음 3가지 주소대역으로 고정된다.
Class A : 10.0.0.0 ~ 10.255.255.255
Class B : 172.16.0.0 ~ 172.31.255.255
Class C : 192.168.0.0 ~ 192.168.255.255


IP Address의 Class에는 어떤 것이 있는가?
IP 주소는 Class라는 개념을 통하여 네트워크 영역과 호스트 영역을 구분하고 있다. 다시 말해, Class는 하나의 IP 주소에서 네트워크 영역과 호스트 영역을 나누는 방법이자 약속이다.
Class는 네트워크의 규모에 따라 결정되며, Class의 차이는 A~C(D, E도 있으나 멀티캐스트 또는 연구용으로 사용) 사이에 몇 개의 호스트 주소를 할당할 수 있느냐의 차이이다. 그러나 고정구간으로 낭비가 많아서 CIDR 체계로 변경되었다.


TCP vs UDP
TCP는 Transmission Control Protocol의 약자이고, UDP는 User Datagram Protocol의 약자이다. 두 프로토콜은 모두 패킷을 한 컴퓨터에서 다른 컴퓨터로 전달해주는 IP 프로토콜을 기반으로 구현되어 있지만, 서로 다른 특징을 가지고 있다.
수신자와 수신이 제대로 되었는지 확인과정이 이루어지는 TCP에 반해, UDP는 일방적으로 데이터를 송신만 할 뿐, 수신 확인은 하지 않는다. 즉, 신뢰성이 요구되는 애플리케이션에서는 TCP를 사용하고 간단한 데이터를 빠른 속도로 전송하고자 하는 애플리케이션에서는 UDP를 사용한다.


TCP는 네트워크 계층 중 전송 계층에서 사용하는 프로토콜로서, 장치들 사이에 논리적인 접속을 성립(establish)하기 위하여 연결을 설정하여 신뢰성을 보장하는 연결형 서비스 이다. TCP는 네트워크에 연결된 컴퓨터에서 실행되는 프로그램 간에 일련의 옥텟(데이터, 메세지, 세그먼트라는 블록 단위)를 안정적으로, 순서대로, 에러없이 교환할 수 있게 한다.
TCP는 네트워크 계층 중 전송 계층에서 사용하는 프로토콜로서, 장치들 사이에 논리적인 접속을 성립(establish)하기 위하여 연결을 설정하여 신뢰성을 보장하는 연결형 서비스 이다. TCP는 네트워크에 연결된 컴퓨터에서 실행되는 프로그램 간에 일련의 옥텟(데이터, 메세지, 세그먼트라는 블록 단위)를 안정적으로, 순서대로, 에러없이 교환할 수 있게 한다.
연결형 서비스 : 연결형 서비스로 가상 회선 방식을 제공한다.
흐름제어 (Flow control) : 데이터 처리 속도를 조절하여 수신자의 버퍼 오버플로우를 방지
혼잡제어 (congestion control) : 네트워크 내의 패킷 수가 넘치게 증가하지 않도록 방지
신뢰성이 높은 전송 (Reliable transmission)
Dupack-based retransmission
Timeout-based retransmission
전이중, 점대점 방식
전이중 (Full-Duplex)전송이 양방향으로 동시에 일어날 수 있다.
점대점 (Point to Point)각 연결이 정확히 2개의 종단점을 가지고 있다.
=> 멀티캐스팅이나 브로드캐스팅을 지원하지 않는다.

응용 계층으로부터 데이터를 받은 TCP는 헤더를 추가한 후에 이를 IP로 보낸다. 헤더에는 아래 표와 같은 정보가 포함된다.


ACK는 송신측에 대하여 수신측에서 긍정 응답으로 보내지는 전송 제어용 캐릭터
ACK 번호를 사용하여 패킷이 도착했는지 확인한다.
-> 송신한 패킷이 제대로 도착하지 않았으면 재송신을 요구한다.


SYN을 보내고 SYN_SENT 상태로 대기한다.SYN_RCVD 상태로 바꾸고 SYN과 응답 ACK를 보낸다.SYN과 응답 ACK을 받은 클라이언트는 ESTABLISHED 상태로 변경하고 서버에게 응답 ACK를 보낸다.ACK를 받은 서버는 ESTABLISHED 상태로 변경한다.FIN_WAIT1 상태로 대기한다.CLOSE_WAIT으로 바꾸고 응답 ACK를 전달한다. 동시에 해당 포트에 연결되어 있는 어플리케이션에게 close()를 요청한다.FIN_WAIT2로 변경한다.FIN을 클라이언트에 보내 LAST_ACK 상태로 바꾼다.TIME_WAIT으로 상태를 바꾼다. TIME_WAIT에서 일정 시간이 지나면 CLOSED된다. ACK를 받은 서버도 포트를 CLOSED로 닫는다.주의반드시 서버만 CLOSE_WAIT 상태를 갖는 것은 아니다.서버가 먼저 종료하겠다고 FIN을 보낼 수 있고, 이런 경우 서버가 FIN_WAIT1 상태가 됩니다.누가 먼저 close를 요청하느냐에 따라 상태가 달라질 수 있다.
응용 계층으로부터 데이터 받은 UDP도 UDP 헤더를 추가한 후에 이를 IP로 보낸다.

TCP 헤더와 다르게 UDP 헤더에는 포함된 정보가 부실한 느낌마저 든다.UDP는 수신자가 데이터를 받는지 마는지 관심이 없기 때문이다. 즉, 신뢰성을 보장해주지 않지만 간단하고 속도가 빠른 것이 특징이다.


Network layers는 무엇인가?
계층 구조를 갖고 있기 때문에, 자세히 알아보기 전에 먼저 계층 구조가 어떤 것인지, 적용하면 어떤 점이 좋은지를 알 필요가 있다. 계층 구조(Layered)는 네트워크 뿐만 아니라 운영체제 등 다양한 분야에서 적용되는데, 계층 구조를 사용하는 목적은 분할 정복(Divide and Conquer) 때문이다. 어떠한 복잡한 문제를 해결하고자 할 때, 나누어 생각하면 쉽게 해결할 수 있다는 취지인 것이다.전제조건이 되어야한다.OSI model은 무엇인가?
OSI 7 Model은 네트워크 통신 과정을 7개의 계층으로 구분한 산업 표준 참조 모델이다. 초창기의 네트워크는 각 컴퓨터마다 시스템이 달랐기 때문에 하드웨어와 소프트웨어의 논리적인 변경없이 통신할 수 있는 표준 모델이 나타나게 되었다.
OSI 참조 모델은 위의 그림과 같이 7개의 층으로 이루어져 있다.

PDU 란?OSI 7계층에서는 PDU 개념을 중요시 하는데, PDU(Process Data Unit)란 각 계층에서 전송되는 단위이다. 1계층에서 PDU가 비트(Bit)라고 생각하기 쉽지만 PDU라고 하지 않고 여기서 비트는 단위라기 보다는 단지 전기 신호의 흐름일 뿐이다.PDU는 2계층-프레임(Frame), 3계층-패킷(Packet), 4계층-세그먼트(Segment) 만 생각하면 된다. 네트워크 통신과정을 깊게 이해하기 위해서는 왜 각각의 계층의 PDU가 다른지 알아야 하고, 역할에 대해 알고 있어야 한다.
물리계층은 OSI 모델의 최하위 계층에 속하며, 상위 계층에서 전송된 데이터를 물리 매체(허브, 라우터, 케이블 등)를 통해 다른 시스템에 전기적 신호를 전송하는 역할을 한다.
즉, 기계어를 전기적 신호로 바꿔서 와이어에 실어주는 것이다.
링크계층은 네트워크 기기들 사이의 데이터 전송을 하는 역할을 한다. 시스템 간의 오류 없는 데이터 전송을 위해 패킷을 프레임으로 구성하여 물리계층으로 전송한다. 3계층에서 정보를 받아 주소와 제어정보를 헤더와 테일에 추가한다.
네트워크계층은 기기에서 데이터그램(Datagram)이 가는 경로를 설정해주는 역할을 한다. 라우팅 알고리즘을 사용하여 최적의 경로를 선택하고 송신측으로부터 수신측으로 전송한다. 이때, 전송되는 데이터는 패킷 단위로 분할하여 전송한 후 다시 합쳐진다. 2계층이 노드 대 노드 전달을 감독한다면, 3계층은 각 패킷이 목적지까지 성공적이고 효과적으로 전달되도록 한다.
발신지에서 목적지(End-to-End) 간 제어와 에러를 관리한다. 패킷의 전송이 유효한지 확인하고 전송에 실패된 패킷을 다시 보내는 것과 같은 신뢰성있는 통신을 보장하며, 헤드에는 세그먼트가 포함된다. 주소 설정, 오류 및 흐름 제어, 다중화를 수행한다.
통신 세션을 구성하는 계층으로, 포트(Port)번호를 기반으로 연결한다. 통신장치 간의 상호작용을 설정하고 유지하며 동기화한다. 동시송수신(Duplex), 반이중(Half-Duplex), 전이중(Full-Duplex) 방식의 통신과 함께 체크 포인팅과 유후, 종료, 다시 시작 과정 등을 수행한다.
표현계층은 송신측과 수신측 사이에서 데이터의 형식(png, jpg, jpeg...)을 정해준다. 받은 데이터를 코드 변환, 구문 검색, 암호화, 압축의 과정을 통해 올바른 표준방식으로 변환해준다.
응용계층은 사용자와 바로 연결되어 있으며 응용 SW를 도와주는 계층이다. 사용자로부터 정보를 입력받아 하위 계층으로 전달하고 하위 계층에서 전송한 데이터를 사용자에게 전달한다.
파일 전송, DB, 메일 전송 등 여러가지 응용 서비스를 네트워크에 연결해주는 역할을 한다.
그렇지만 OSI 참조 모델은 말그대로 참조 모델일 뿐 실제 사용되는 인터넷 프로토콜은 을 7계층 구조를 완전히 따르지는 않는다. 인터넷 프로토콜 스택(Internet Protocol Stack)은 현재 대부분 TCP/IP를 따른다.
TCP/IP는 인터넷 프로토콜 중 가장 중요한 역할을 하는 TCP와 IP의 합성어로 데이터의 흐름 관리, 정확성 확인, 패킷의 목적지 보장을 담당한다. 데이터의 정확성 확인은 TCP가, 패킷을 목적지까지 전송하는 일은 IP가 담당한다.
TCP/IP의 4계층TCP/IP는 OSI 참조 모델과 달리 표현계층, 세션계층을 응용계층에 다 포함시키고 있지만, 사실상 TCP/IP Model의 Application 계층 하나에서 Application, Presentatiom, Session 계층의 구현을 다 하고 있다고 이해하는 게 올바르다.

데이터는 아래 그림과 같이 단계 별로 헤더(Data → Segment → Datagram → Frame)를 붙여 전송하며 이를 데이터 캡슐화라고 한다.

동적 호스트 설정 프로토콜(Dynamic Host Configuration Protocol)로서 해당 호스트에게 IP주소, 서브넷 마스크, 기본게이트웨이 IP주소, DNS서버 IP주소 를 자동으로 일정 시간 할당해주는 인터넷 프로토콜
DHCP를 통한 IP 주소 할당은 임대(Lease)라는 개념을 가지고 있는데 이는 DHCP 서버가 IP 주소를 영구적으로 단말에 할당하는 것이 아니고 임대기간(IP Lease Time)을 명시하여 그 기간 동안만 단말이 IP 주소를 사용하도록 하는 것이다. 단말은 임대기간 이후에도 계속 해당 IP 주소를 사용하고자 한다면 IP 주소 임대기간 갱신(IP Address Renewal)을 DHCP 서버에 요청해야 하고 또한 단말은 임대 받은 IP 주소가 더 이상 필요치 않게 되면 IP 주소 반납 절차(IP Address Release)를 수행하게 된다.
즉,
유동 IP를 할당한다 == DHCP서버로부터 IP를 DHCP서버에서 설정해놓은 사용시간만큼 임대해온다.
DHCP서버는 인터넷을 제공해주는 곳의 서버에서 실행되는 프로그램으로 일정한 범위의 IP주소를 다른 클라이언트에게 할당하여 자동으로 설정하게 해주는 역할을 한다. DHCP서버는 클라이언트에게 할당된 IP주소를 변경없이 유지해 줄 수 있다. DHCP가 설정해주는 주소 정보들은 아래와 같다.

클라이언트들은 시스템이 시작하면 DHCP서버에 자신의 시스템을 위한 IP주소를 요청하고, DHCP 서버로부터 IP주소를 부여받으면 TCP/IP 설정은 초기화되고 다른 호스트와 TCP/IP를 사용해서 통신을 할 수 있게 된다.
즉, 서버에게 IP를 할당받으면 TCP/IP 통신을 할 수 있다.

IP 주소 할당(임대) 절차에 사용되는 DHCP 메시지는 아래 그림과 같이 4개의 메시지로 구성되어 있다.

패킷 방향 : DHCP 서버 -> 클라이언트
브로드캐스트 메시지 : Destination MAC = FF:FF:FF:FF:FF:FF 혹은 유니캐스트.
이는 클라이언트가 보낸 DHCP Discover 메시지 내의 Broadcast Flag의 값에 따라 달라지는데, 이 Flag=1이면 DHCP 서버는 DHCP Offer 메시지를 Broadcast로, Flag=0이면 Unicast로 보내게 된다.
의미: DHCP 서버가 "저 여기 있어요~"라고 응답하는 메시지. 단순히 DHCP 서버의 존재만을 알리지 않고, 클라이언트에 할당할 IP 주소 정보를 포함한 다양한 "네트워크 정보"를 함께 실어서 클라이언트에 전달한다.
주요 파라미터(패킷 내용) :
패킷 방향: DHCP 서버 -> 클라이언트
브로드캐스트 메시지 : Destination MAC = FF:FF:FF:FF:FF:FF 혹은 유니캐스트.
이는 단말이 보낸 DHCP Request 메시지 내의 Broadcast Flag=1이면 DHCP 서버는 DHCP Ack 메시지를 Broadcast로, Flag=0이면 Unicast로 보내게 된다.
의미: DHCP 절차의 마지막 메시지로, DHCP 서버가 단말에게 "네트워크 정보"를 전달해 주는 메시지. 앞서 설명한 DHCP Offer의 '네트워크 정보"와 동일한 파라미터가 포함된다.
주요 파라미터(패킷 내용) : DHCP Request 패킷의 파라미터와 동일
도메인 네임과 IP 주소의 대응 관계를 데이터베이스로 구축해 사용하는 인터넷 프로토콜
위에서 배웠듯 클라이언트에게 DNS (Domain Name Server)를 제공하는 것은 DHCP 서버의 책임이다. DNS는 브라우징을 단순화하는 매우 특별한 목적을 수행하는 인터넷 상의 또 다른 컴퓨터라고 볼 수 있다.
네트워크의 각 컴퓨터에는 고유한 IP 주소가 있고, 이는 인터넷에서도 마찬가지이다. 인터넷에 연결된 모든 네트워크 또는 컴퓨터 서버에도 고유한 주소가 있다. 우리가 자주 방문하는 사이트의 각 IP 주소를 매번 기억하는 것은 사실 불가능한 일에 가깝다. 그래서 우리는 도메인 이름(www.으로 시작하는 주소)을 사용하는데, 사용자가 https://velog.io/@hidaehyunlee 과 같이 입력한 주소를 125.209.222.141와 같은 IP 주소로 변환해주는 일을 바로 DNS가 수행하는 것이다. 이러한 DNS를 운영하는 서버를 네임서버(Name Server)라고 한다.
1. 특정 사이트를 방문하기위해 사용자가 브라우저에 URL을 입력한다.
2. 그러면 브라우저는 DNS에 접속하여 입력한 도메인 이름과 관련된 IP 주소를 요청한다.
3. 획득한 IP 주소를 사용하여 브라우저는 그 컴퓨터와 통신하고 사용자로부터 요청된 특정 페이지를 요청할 수 있다. 
13. 두 개의 IP Address 사이에 통신하기 위한 규칙은 무엇이 있는가?
https://ko.wikipedia.org/wiki/인터넷_프로토콜
라우터는 전용회선을 통해 LAN에 연결된 컴퓨터들이 동시에 인터넷을 사용할 수 있게 해주는 장비로 데이터를 목적지까지 전달하는 기능을 수행하며 2개 이상의 서로 다른 네트워크를 접속하고 이들 간 데이터를 주고 받게하는 중계 기능도 한다. 대부분의 라우터는 IP 라우팅 기능뿐 아니라 LAN용 프로토콜인 IPX, AppleTalk등의 브리징 기능도 함께한다.

즉, 라우터는 IP네트워크, 서브넷을 관리하면서 다른 네트워크를 거쳐 패킷을 전송하는 역할을 하는 장비이고, 라우팅은 그 패킷을 보낼 경로를 선택하는 과정이라고 볼 수 있다.
라우터는 패킷의 전송경로를 결정하기 위해 랜테이블, 네트워크테이블, 라우팅테이블을 사용한다. 라우터는 위의 3가지 테이블을 관리함으로써 다른 네트워크에 연결된 장치들을 비롯하여 네트워크에 연결된 모든 장치들의 주소를 인식하고 이것을 바탕으로 패킷의 전송경로를 결정한다.
동일 네트워크 상에 있는 장치로 패킷을 보낼 때 라우터에서는 아래 순서를 매번 거친다.
랜테이블 검사를 한다. 이곳에서는 패킷의 목적지가 같은 네트워크에 있는지 아니면 다른 네트워크에 있는지를 확인한다.네트워크테이블을 검사하여 패킷을 전달할 네트워크 주소를 찾아낸다.라우팅테이블을 검색하여 가장 적합한 경로를 찾아내서 패킷을 보낸다.랜테이블
랜테이블은 라우터에 연결되어 있는 랜 세그먼트 내 장치의 주소를 관리하고 있으며 필터링작업에 사용된다.
네트워크테이블
네트워크상의 모든 라우터의 주소를 보관하며 패킷의 수신지 라우터를 식별하는데 사용된다.
라우팅테이블
각각의 라우터에 구축되어 있으며 각 경로에 대한 정보를 유지하고 있어서 다른 세그먼트로 전송 되는 패킷의 가장 효율적인 경로를 결정하는데 사용된다.
자신과 물리적으로 직접 연결되어있는 장비의 IP 주소를 자동으로 알아온다. 이때 IP는 네트워크 주소로 라우팅 테이블에 저장된다.
관리자가 직접 라우팅 경로를 선택해서 보내는 설정.
각 라우터들이 갖고 있는 정보를 서로에게 공유하여 라우팅 테이블에 저장한다. 주시적으로 최적경로를 계산하여 라우팅 테이블의 정보를 유지하는 방식이다.
정보 교환이 이루어지지 않는 장비끼리 관리자가 강제로 교환하는 방식.
Routing의 기본 Gateway는 무엇인가?
IP의 관점에서 Port는 무엇이며, 두 기기간의 통신하는데 사용되는 것은 무엇인가?
int ft_printf(const char *, ...);flags : '-0.*'
width
precision
type : cspdiuxX%
스티커를 세밀하고 자연스럽게 적용하기 위해서는 눈, 코, 입, 귀와 같은 얼굴 각각의 위치를 아는 것이 중요하다. 이들을 찾아내는 기술을 랜드마크(landmark)또는 조정(alignment)이라고 한다. 조금 더 큰 범위로는 keypoint detection 이라고 부른다.
# 관련 패키지 설치
pip install opencv-python
pip install cmake
pip install dlib# 필요 라이브러리 import
import cv2
import matplotlib.pyplot as plt
import numpy as np
print("🌫🛸")
# opencv로 이미지 읽어오기
import os
my_image_path = os.getenv('HOME')+'/aiffel/camera_sticker/images/image.jpg'
img_bgr = cv2.imread(my_image_path) #- OpenCV로 이미지를 읽어서
img_bgr = cv2.resize(img_bgr, (480, 640)) # 640x360의 크기로 Resize
img_show = img_bgr.copy() #- 출력용 이미지 별도 보관
plt.imshow(img_bgr)
plt.show()
# plt.imshow 이전에 RGB 이미지로 변경
# opencv는 RGB 대신 BGR을 사용하기 때문에 RGB로 변경해주어야 한다.
img_rgb = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB)
plt.imshow(img_rgb)
plt.show()Object detection 기술을 이용해서 얼굴의 위치를 찾는다. dlib 의 face detector는 HOG(Histogram of Oriented Gradient) feature를 사용해서 SVM(Support Vector Machine)의 sliding window로 얼굴을 찾는다.
# hog detector 선언
import dlib
detector_hog = dlib.get_frontal_face_detector()
# bounding box 추출
img_rgb = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB)
dlib_rects = detector_hog(img_rgb, 1) #- (image, num of img pyramid)
# 찾은 얼굴영역 출력
print(dlib_rects) # 찾은 얼굴영역 좌표
for dlib_rect in dlib_rects:
l = dlib_rect.left()
t = dlib_rect.top()
r = dlib_rect.right()
b = dlib_rect.bottom()
cv2.rectangle(img_show, (l,t), (r,b), (0,255,0), 2, lineType=cv2.LINE_AA)
img_show_rgb = cv2.cvtColor(img_show, cv2.COLOR_BGR2RGB)
plt.imshow(img_show_rgb)
plt.show()이목구비의 위치를 추론하는 것을 face landmark localization 기술이라고 한다. face landmark는 detection의 결과물인 bounding box로 잘라낸(crop) 얼굴 이미지를 이용한다.

Dlib landmark localization
# Dlib 제공 모델 사용
wget http://dlib.net/files/shape_predictor_68_face_landmarks.dat.bz2
mv shape_predictor_68_face_landmarks.dat.bz2 ~/aiffel/camera_sticker/models
cd ~/aiffel/camera_sticker && bzip2 -d ./models/shape_predictor_68_face_landmarks.dat.bz2# landmark 모델 불러오기
import os
model_path = os.getenv('HOME')+'/aiffel/camera_sticker/models/shape_predictor_68_face_landmarks.dat'
landmark_predictor = dlib.shape_predictor(model_path)
# landmark 찾기
list_landmarks = []
for dlib_rect in dlib_rects:
points = landmark_predictor(img_rgb, dlib_rect)
list_points = list(map(lambda p: (p.x, p.y), points.parts()))
list_landmarks.append(list_points)
print(len(list_landmarks[0]))
# landmark 출력
for landmark in list_landmarks:
for idx, point in enumerate(list_points):
cv2.circle(img_show, point, 2, (0, 255, 255), -1) # yellow
img_show_rgb = cv2.cvtColor(img_show, cv2.COLOR_BGR2RGB)
plt.imshow(img_show_rgb)
plt.show()
적절한 랜드마크를 기준으로 하여 스티커 이미지를 구현한다.
# 좌표 확인
for dlib_rect, landmark in zip(dlib_rects, list_landmarks):
print (landmark[30]) # nose center index : 30
x = landmark[30][0]
y = landmark[30][1] - dlib_rect.width()//2
w = dlib_rect.width()
h = dlib_rect.width()
print ('(x,y) : (%d,%d)'%(x,y))
print ('(w,h) : (%d,%d)'%(w,h))
# 스티커 이미지 Read
import os
sticker_path = os.getenv('HOME')+'/aiffel/camera_sticker/images/king.png'
img_sticker = cv2.imread(sticker_path)
img_sticker = cv2.resize(img_sticker, (w,h))
print (img_sticker.shape)
# 스티커 이미지 좌표
refined_x = x - w // 2 # left
refined_y = y - h # top
print ('(x,y) : (%d,%d)'%(refined_x, refined_y))
# y좌표가 음수일 때, -y만큼 이미지를 잘라준 후 y 경계값은 0으로 설정
#img_sticker = img_sticker[-refined_y:]
#print (img_sticker.shape)
#refined_y = 0
#print ('(x,y) : (%d,%d)'%(refined_x, refined_y))
# 원본에 스티커 적용
sticker_area = img_show[refined_y:refined_y+img_sticker.shape[0], refined_x:refined_x+img_sticker.shape[1]]
img_show[refined_y:refined_y+img_sticker.shape[0], refined_x:refined_x+img_sticker.shape[1]] = \
np.where(img_sticker==0,sticker_area,img_sticker).astype(np.uint8)
# 결과 이미지 출력
plt.imshow(cv2.cvtColor(img_show, cv2.COLOR_BGR2RGB))
plt.show()
# bounding box 제거 후 이미지
sticker_area = img_bgr[refined_y:refined_y+img_sticker.shape[0], refined_x:refined_x+img_sticker.shape[1]]
img_bgr[refined_y:refined_y+img_sticker.shape[0], refined_x:refined_x+img_sticker.shape[1]] = \
np.where(img_sticker==0,sticker_area,img_sticker).astype(np.uint8)
plt.imshow(cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB))
plt.show()이번엔 귀여운 고양이 수염 스티커를 만들어보자.
# 필요 라이브러리 import
import cv2
import matplotlib.pyplot as plt
import numpy as np
import os
import dlib
import math
print("🌫🛸")
# opencv로 이미지 불러오기
my_image_path = os.getenv('HOME')+'/aiffel/camera_sticker/images/images01.jpg'
img_bgr = cv2.imread(my_image_path) #- OpenCV로 이미지를 읽어서
#img_bgr = cv2.resize(img_bgr, (img_bgr.shape[0] // 16 * 5, img_bgr.shape[1] // 9 * 5)) # Resize
img_bgr_orig = img_bgr.copy()
img_show = img_bgr.copy() #- 출력용 이미지 별도 보관
plt.imshow(img_bgr)
plt.show()
# RGB 변환
img_rgb = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB)
plt.imshow(img_rgb)
plt.show()
# HOG Detector 선언
detector_hog = dlib.get_frontal_face_detector()
# Bounding box 추출
dlib_rects = detector_hog(img_rgb, 1) #- (image, num of img pyramid)
# 찾은 얼굴 영역 좌표
print(dlib_rects)
for dlib_rect in dlib_rects:
l = dlib_rect.left()
t = dlib_rect.top()
r = dlib_rect.right()
b = dlib_rect.bottom()
cv2.rectangle(img_show, (l,t), (r,b), (0,255,0), 2, lineType=cv2.LINE_AA)
img_show_rgb = cv2.cvtColor(img_show, cv2.COLOR_BGR2RGB)
plt.imshow(img_show_rgb)
plt.show()
# landmark model 불러오기
model_path = os.getenv('HOME')+'/aiffel/camera_sticker/models/shape_predictor_68_face_landmarks.dat'
landmark_predictor = dlib.shape_predictor(model_path)
# landmark 찾기
list_landmarks = []
for dlib_rect in dlib_rects:
points = landmark_predictor(img_rgb, dlib_rect)
list_points = list(map(lambda p: (p.x, p.y), points.parts()))
list_landmarks.append(list_points)
print(len(list_landmarks[0])) # landmark 갯수 확인
# landmark 출력
for landmark in list_landmarks:
for idx, point in enumerate(list_points):
cv2.circle(img_show, point, 2, (0, 255, 255), -1) # yellow
img_show_rgb = cv2.cvtColor(img_show, cv2.COLOR_BGR2RGB)
plt.imshow(img_show_rgb)
plt.show()
# 좌표 확인
for dlib_rect, landmark in zip(dlib_rects, list_landmarks):
print (landmark[30]) # nose center index : 30
x = landmark[30][0]
y = landmark[30][1]
w = dlib_rect.width()
h = dlib_rect.width()
print ('(x,y) : (%d,%d)'%(x,y))
print ('(w,h) : (%d,%d)'%(w,h))
# 스티커 이미지 Read
sticker_path = os.getenv('HOME')+'/aiffel/camera_sticker/images/cat-whiskers.png'
img_sticker = cv2.imread(sticker_path)
img_sticker = cv2.resize(img_sticker, (w, h))
img_sticker_rgb = cv2.cvtColor(img_sticker, cv2.COLOR_BGR2RGB)
plt.imshow(img_sticker_rgb)
plt.show
print (img_sticker.shape)
# 스티커 이미지 좌표
refined_x = x - w // 2 # left
refined_y = y - h // 2 # top
print ('(x,y) : (%d,%d)'%(refined_x, refined_y))
# y좌표가 음수일 때, -y만큼 이미지를 잘라준 후 y 경계값은 0으로 설정
if refined_y < 0:
img_sticker = img_sticker[-refined_y:]
refined_y = 0
print (img_sticker.shape)
print ('(x,y) : (%d,%d)'%(refined_x, refined_y))
# 원본에 스티커 적용
sticker_area = img_show[refined_y:refined_y+img_sticker.shape[0], refined_x:refined_x+img_sticker.shape[1]]
img_show[refined_y:refined_y+img_sticker.shape[0], refined_x:refined_x+img_sticker.shape[1]] = \
np.where(img_sticker==255,sticker_area,img_sticker).astype(np.uint8)
# 결과 이미지 출력
plt.imshow(cv2.cvtColor(img_show, cv2.COLOR_BGR2RGB))
plt.show()
# 불투명도 조절
sticker_area = img_bgr_orig[refined_y:refined_y+img_sticker.shape[0], refined_x:refined_x+img_sticker.shape[1]]
img_bgr[refined_y:refined_y+img_sticker.shape[0], refined_x:refined_x+img_sticker.shape[1]] = \
cv2.addWeighted(sticker_area, 0.5, np.where(img_sticker==255,sticker_area,img_sticker).astype(np.uint8), 0.5, 0)
plt.imshow(cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB))
plt.show()
# vector 계산
landmark = list_landmarks[0]
v1 = np.array([0, -1])
v2 = np.array([abs(landmark[33][0] - landmark[27][0]), abs(landmark[33][1] - landmark[27][1])])
unit_vector_1 = v1 / np.linalg.norm(v1)
unit_vector_2 = v2 / np.linalg.norm(v2)
dot_product = np.dot(unit_vector_1, unit_vector_2)
angle = np.arccos(dot_product)
# 회전 변환
rows, cols = img_sticker.shape[:2]
img_sticker_rot = cv2.warpAffine(img_sticker, cv2.getRotationMatrix2D((cols/2, rows/2), math.degrees(angle), 1), (cols, rows))
plt.imshow(img_sticker_rot)
plt.show
# 회전 후 불투명도 조절 -> 실패
sticker_area = img_bgr_orig[refined_y:refined_y+img_sticker.shape[0], refined_x:refined_x+img_sticker.shape[1]]
img_bgr[refined_y:refined_y+img_sticker.shape[0], refined_x:refined_x+img_sticker.shape[1]] = \
cv2.addWeighted(sticker_area, 0.5, np.where(img_sticker_rot==255,sticker_area,img_sticker_rot).astype(np.uint8), 0.5, 0)
plt.imshow(cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB))
plt.show()유용한 링크
https://opencv-python.readthedocs.io/en/latest/doc/01.imageStart/imageStart.html
https://medium.com/@jongdae.lim/기계-학습-machine-learning-은-즐겁다-part-4-63ed781eee3c
https://opencv-python.readthedocs.io/en/latest/doc/14.imagePyramid/imagePyramid.html
https://www.tugraz.at/institute/icg/research/team-bischof/lrs/downloads/aflw/
| [SSAC X AIFFEL] 인공지능 모델로 음성 단어 구분하기 (1) | 2021.01.29 |
|---|---|
| [SSAC X AIFFEL] 영화리뷰 텍스트 감성분석 하기 (0) | 2021.01.22 |
| [SSAC X AIFFEL] 사이킷런(scikit-learn): Iris 품종 분류해보기 (0) | 2021.01.08 |
| [SSAC X AIFFEL] 첫 딥러닝 모델: 가위바위보 분류기 (0) | 2021.01.05 |
| [SSAC X AIFFEL] 첫 글쓰기 (0) | 2020.12.31 |