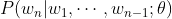64bit macOS에서 parameter는 rdi, rsi, rdx, rcx, r8, r9 register를 통해서 전달되며, 그 이상의 parameter는 stack을 통해 전달된다. 따라서, char const *str은 rdi에 전달되어 있다. 관련 자료는 calling convention을 찾아보자. 참고자료
rax에 저장되어 있는 값은 함수가 끝났을 때 return하는 값이기 때문에 count index를 rax로 사용하였다.
strlen 함수는 문자열의 길이를 반환하는 함수이므로, str의 주소를 참조하여 해당 문자가 null인지 아닌지 판단하여 값을 반환하게 된다.
assembly에서 값을 비교할 때는 register의 크기에 주의해야 한다. 문자 하나의 data size는 1byte이기 때문에 null을 판단할 때에도 byte 만큼만 비교해야 한다.
ft_strcmp
assembly에서는 두 operand를 비교할 때, 둘 중 하나의 operand에만 추가 연산이 가능하다. 예를 들어, a와 b를 index 만큼 이동한 위치를 비교한다고 가정할 때, a + index, b + index 와 같은 연산이 불가능하다는 이야기이다.
따라서 위와 같은 연산을 할 경우에는 다른 register에 값을 옮긴 후 옮겨진 값을 이용하여 연산해야 한다.
libft에서 고려하지 않았던 확장 아스키코드와의 비교도 가능하기 때문에 unsigned char의 범위 안에 있는 문자는 모두 비교할 수 있어야 한다.
문자의 차이값을 구하는 과정에서 특정 register의 flag에 주의하여야 한다. overflow가 발생했을 경우에 어떻게 처리해야 할지 잘 생각해봐야 한다.
ft_strcpy
ft_strcmp와 마찬가지로 하나의 register를 temp로 사용하여 src에 있는 값을 복사한 후 복사된 값이 null인지를 체크하여 마지막에 *dest를 return 해주면 된다.
이 함수를 작성하면서 왜 parameter에서 dest가 먼저 전달되는 지 알 수 있었다. rdi와 rsi의 관계가 dest와 src의 관계와 일치한다.
ft_write
syscall에 대해 이해하고 있다면 함수를 작성하는 것 자체는 어렵지 않다. 그러나, error처리에 대한 부분을 간과하기 쉽다.
syscall 후에 error가 발생했다면, 자동적으로 error number를 rax에 return해준다.
error가 발생했을 때, 적절한 return value와 errno를 반환해야 하기 때문에 먼저 ___error를 불러오는 방법부터 알아야 한다.
___error 함수를 호출했을 때, return되는 값은 errno의 주소값이다.
errno가 제대로 설정되었는지 확인하려면 standard 함수에서의 errno와 비교해보면 된다. 다만 standard 함수에서 errno 출력 후, ft_write 함수를 불러오기 전에 errno를 다시 초기화 해주어야 하는 것을 잊지 말자.
문장은 각 단어들이 문법이라는 규칙을 따라 배열되어 있기 때문에 시퀀스 데이터로 볼 수 있다.
문법은 복잡하기 때문에 문장 데이터를 이용한 인공지능을 만들 때에는 통계에 기반한 방법을 이용한다.
순환신경망(RNN)
나는 공부를 [ ]에서 빈 칸에는 한다 라는 단어가 들어갈 것이다. 문장에는 앞 뒤 문맥에 따라 통계적으로 많이 사용되는 단어들이 있다. 인공지능이 글을 이해하는 방식도 위와 같다. 문법적인 원리를 통해서가 아닌 수많은 글을 읽게하여 통계적으로 다음 단어는 어떤 것이 올지 예측하는 것이다. 이 방식에 가장 적합한 인공지능 모델 중 하나가 순환신경망(RNN)이다.
시작은 <start>라는 특수한 토큰을 앞에 추가하여 시작을 나타내고, <end>라는 토큰을 통해 문장의 끝을 나타낸다.
언어 모델
나는, 공부를, 한다 를 순차적으로 생성할 때, 우리는 공부를 다음이 한다인 것을 쉽게 할 수 있다. 나는 다음이 한다인 것은 어딘가 어색하게 느껴진다. 실제로 인공지능이 동작하는 방식도 순전히 운이다.
이것을 좀 더 확률적으로 표현해 보면 나는 공부를 다음에 한다가 나올 확률을 $p(한다|나는, 공부를)$라고 하면, $p(공부를|나는)$보다는 높게 나올 것이다. $p(한다|나는, 공부를, 열심히)$의 확률값은 더 높아질 것이다.
문장에서 단어 뒤에 다음 단어가 나올 확률이 높다는 것은 그 단어가 자연스럽다는 뜻이 된다. 확률이 낮다고 해서 자연스럽지 않은 것은 아니다. 단어 뒤에 올 수 있는 자연스러운 단어의 경우의 수가 워낙 많아서 불확실성이 높을 뿐이다.
n-1개의 단어 시퀀스 $w_1,⋯,w_{n-1}$이 주어졌을 때, n번째 단어 $w_n$으로 무엇이 올지 예측하는 확률 모델을 언어 모델(Language Model)이라고 부른다. 파라미터 $\theta$로 모델링 하는 언어 모델을 다음과 같이 표현할 수 있다.
언어 모델은 어떻게 학습시킬 수 있을까? 언어 모델의 학습 데이터는 어떻게 나누어야 할까? 답은 간단하다. 어떠한 텍스트도 언어 모델의 학습 데이터가 될 수 있다. x_train이 n-1번째까지의 단어 시퀀스고, y_train이 n번째 단어가 되는 데이터셋이면 얼마든지 학습 데이터로 사용할 수 있다. 이렇게 잘 훈련된 언어 모델은 훌륭한 문장 생성기가 된다.
인공지능 만들기
(1) 데이터 준비
import re
import numpy as np
import tensorflow as tf
import os
# 파일 열기
file_path = os.getenv('HOME') + '/aiffel/lyricist/data/shakespeare.txt'
with open(file_path, "r") as f:
raw_corpus = f.read().splitlines() # 텍스트를 라인 단위로 끊어서 list 형태로 읽어온다.
print(raw_corpus[:9])
데이터에서 우리가 원하는 것은 문장(대사)뿐이므로, 화자 이름이나 공백은 제거해주어야 한다.
# 문장 indexing
for idx, sentence in enumerate(raw_corpus):
if len(sentence) == 0: continue # 길이가 0인 문장은 스킵
if sentence[-1] == ":": continue # :로 끝나는 문장은 스킵
if idx > 9: break
print(sentence)
이제 문장을 단어로 나누어야 한다. 문장을 형태소로 나누는 것을 토큰화(Tokenize)라고 한다. 가장 간단한 방법은 띄어쓰기를 기준으로 나누는 것이다. 그러나 문장부호, 대소문자, 특수문자 등이 있기 때문에 따로 전처리를 먼저 해주어야 한다.
# 문장 전처리 함수
def preprocess_sentence(sentence):
sentence = sentence.lower().strip() # 소문자로 바꾸고 양쪽 공백을 삭제
# 정규식을 이용하여 문장 처리
sentence = re.sub(r"([?.!,¿])", r" \1 ", sentence) # 패턴의 특수문자를 만나면 특수문자 양쪽에 공백을 추가
sentence = re.sub(r'[" "]+', " ", sentence) # 공백 패턴을 만나면 스페이스 1개로 치환
sentence = re.sub(r"[^a-zA-Z?.!,¿]+", " ", sentence) # a-zA-Z?.!,¿ 패턴을 제외한 모든 문자(공백문자까지도)를 스페이스 1개로 치환
sentence = sentence.strip()
sentence = '<start> ' + sentence + ' <end>' # 문장 앞뒤로 <start>와 <end>를 단어처럼 붙여 줍니다
return sentence
print(preprocess_sentence("Hi, This @_is ;;;sample sentence?"))
우리가 구축해야할 데이터셋은 입력이 되는 소스 문장(Source Sentence)과 출력이 되는 타겟 문장(Target Sentence)으로 나누어야 한다.
언어 모델의 입력 문장 : <start> 나는 공부를 한다
언어 모델의 출력 문장 : 나는 공부를 한다 <end>
위에서 만든 전처리 함수에서 를 제거하면 소스 문장, 를 제거하면 타겟 문장이 된다.
corpus = []
# 모든 문장에 전처리 함수 적용
for sentence in raw_corpus:
if len(sentence) == 0: continue
if sentence[-1] == ":": continue
corpus.append(preprocess_sentence(sentence))
corpus[:10]
이제 문장을 컴퓨터가 이해할 수 있는 숫자로 변경해주어야 한다. 텐서플로우는 자연어 처리를 위한 여러 가지 모듈을 제공하며, tf.keras.preprocessing.text.Tokenizer 패키지는 데이터를 토큰화하고, dictionary를 만들어주며, 데이터를 숫자로 변환까지 한 번에 해준다. 이 과정을 벡터화(Vectorize)라고 하며, 변환된 숫자 데이터를 텐서(tensor)라고 한다.
def tokenize(corpus):
# 텐서플로우에서 제공하는 Tokenizer 패키지를 생성
tokenizer = tf.keras.preprocessing.text.Tokenizer(
num_words=7000, # 전체 단어의 개수
filters=' ', # 전처리 로직
oov_token="<unk>" # out-of-vocabulary, 사전에 없는 단어
)
tokenizer.fit_on_texts(corpus) # 우리가 구축한 corpus로부터 Tokenizer가 사전을 자동구축
# tokenizer를 활용하여 모델에 입력할 데이터셋을 구축
tensor = tokenizer.texts_to_sequences(corpus) # tokenizer는 구축한 사전으로부터 corpus를 해석해 Tensor로 변환
# 입력 데이터의 시퀀스 길이를 일정하게 맞추기 위한 padding 메소드
# maxlen의 디폴트값은 None. corpus의 가장 긴 문장을 기준으로 시퀀스 길이가 맞춰진다
tensor = tf.keras.preprocessing.sequence.pad_sequences(tensor, padding='post')
print(tensor,tokenizer)
return tensor, tokenizer
tensor, tokenizer = tokenize(corpus)
print(tensor[:3, :10]) # 생성된 텐서 데이터 확인
# 단어 사전의 index
for idx in tokenizer.index_word:
print(idx, ":", tokenizer.index_word[idx])
if idx >= 10: break
src_input = tensor[:, :-1] # tensor에서 마지막 토큰을 잘라내서 소스 문장을 생성. 마지막 토큰은 <end>가 아니라 <pad>일 가능성이 높다.
tgt_input = tensor[:, 1:] # tensor에서 <start>를 잘라내서 타겟 문장을 생성.
print(src_input[0])
print(tgt_input[0])
# 데이터셋 구축
BUFFER_SIZE = len(src_input)
BATCH_SIZE = 256
steps_per_epoch = len(src_input) // BATCH_SIZE
VOCAB_SIZE = tokenizer.num_words + 1 # 0:<pad>를 포함하여 dictionary 갯수 + 1
dataset = tf.data.Dataset.from_tensor_slices((src_input, tgt_input)).shuffle(BUFFER_SIZE)
dataset = dataset.batch(BATCH_SIZE, drop_remainder=True)
dataset
데이터셋 생성 과정 요약
정규표현식을 이용한 corpus 생성
tf.keras.preprocessing.text.Tokenizer를 이용해 corpus를 텐서로 변환
tf.data.Dataset.from_tensor_slices()를 이용해 corpus 텐서를 tf.data.Dataset객체로 변환
(2) 모델 학습하기
이번에 만들 모델의 구조는 다음과 같다.
# 모델 생성
class TextGenerator(tf.keras.Model):
def __init__(self, vocab_size, embedding_size, hidden_size):
super(TextGenerator, self).__init__()
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_size)
self.rnn_1 = tf.keras.layers.LSTM(hidden_size, return_sequences=True)
self.rnn_2 = tf.keras.layers.LSTM(hidden_size, return_sequences=True)
self.linear = tf.keras.layers.Dense(vocab_size)
def call(self, x):
out = self.embedding(x)
out = self.rnn_1(out)
out = self.rnn_2(out)
out = self.linear(out)
return out
embedding_size = 256 # 워드 벡터의 차원 수
hidden_size = 1024 # LSTM Layer의 hidden 차원 수
model = TextGenerator(tokenizer.num_words + 1, embedding_size , hidden_size)
# 모델의 데이터 확인
for src_sample, tgt_sample in dataset.take(1): break
model(src_sample)
# 모델의 최종 출력 shape는 (256, 20, 7001)
# 256은 batch_size, 20은 squence_length, 7001은 단어의 갯수(Dense Layer 출력 차원 수)
model.summary() # sequence_length를 모르기 때문에 Output shape를 정확하게 모른다.
# 모델 학습
optimizer = tf.keras.optimizers.Adam()
loss = tf.keras.losses.SparseCategoricalCrossentropy(
from_logits=True,
reduction='none'
)
model.compile(loss=loss, optimizer=optimizer)
model.fit(dataset, epochs=30)
위의 코드에서 embbeding_size 는 워드 벡터의 차원 수를 나타내는 parameter로, 단어가 추상적으로 표현되는 크기를 말한다. 예를 들어 크기가 2라면 다음과 같이 표현할 수 있다.
차갑다: [0.0, 1.0]
뜨겁다: [1.0, 0.0]
미지근하다: [0.5, 0.5]
(3) 모델 평가하기
인공지능을 통한 작문은 수치적으로 평가할 수 없기 때문에 사람이 직접 평가를 해야 한다.
# 문장 생성 함수
def generate_text(model, tokenizer, init_sentence="<start>", max_len=20):
# 테스트를 위해서 입력받은 init_sentence도 텐서로 변환
test_input = tokenizer.texts_to_sequences([init_sentence])
test_tensor = tf.convert_to_tensor(test_input, dtype=tf.int64)
end_token = tokenizer.word_index["<end>"]
# 단어를 하나씩 생성
while True:
predict = model(test_tensor) # 입력받은 문장
predict_word = tf.argmax(tf.nn.softmax(predict, axis=-1), axis=-1)[:, -1] # 예측한 단어가 새로 생성된 단어
# 우리 모델이 새롭게 예측한 단어를 입력 문장의 뒤에 붙이기
test_tensor = tf.concat([test_tensor,
tf.expand_dims(predict_word, axis=0)], axis=-1)
# 우리 모델이 <end>를 예측했거나, max_len에 도달하지 않았다면 while 루프를 또 돌면서 다음 단어를 예측
if predict_word.numpy()[0] == end_token: break
if test_tensor.shape[1] >= max_len: break
generated = ""
# 생성된 tensor 안에 있는 word index를 tokenizer.index_word 사전을 통해 실제 단어로 하나씩 변환
for word_index in test_tensor[0].numpy():
generated += tokenizer.index_word[word_index] + " "
return generated # 최종 생성된 자연어 문장
# 생성 함수 실행
generate_text(model, tokenizer, init_sentence="<start> i love")
회고록
range(n)도 reverse() 함수가 먹힌다는 걸 오늘 알았다...
예시에 주어진 train data 갯수는 124960인걸 보면 총 데이터는 156200개인 것 같은데 아무리 전처리 단계에서 조건에 맞게 처리해도 168000개 정도가 나온다. 아무튼 일단 돌려본다.
문장의 길이가 최대 15라는 이야기는 <start>, <end>를 포함하여 15가 되어야 하는 것 같아서 tokenize했을 때 문장의 길이가 13 이하인 것만 corpus로 만들었다.
학습 회차 별 생성된 문장 input : <start> i love
1회차 '<start> i love you , i love you <end> '
2회차 '<start> i love you , i m not gonna crack <end> '
3회차'<start> i love you to be a shot , i m not a man <end> '
4회차 '<start> i love you , i m not stunning , i m a fool <end> '
batch_size를 각각 256, 512, 1024로 늘려서 진행했는데, 1epoch당 걸리는 시간이 74s, 62s, 59s 정도로 batch_size 배수 만큼의 차이는 없었다. batch_size가 배로 늘어나면 걸리느 시간도 당연히 반으로 줄어들 것이라 생각했는데 오산이었다.
1회차는 tokenize 했을 때 length가 15 이하인 것을 train_data로 사용하였다.
2, 3, 4회차는 tokenize 했을 때 length가 13 이하인 것을 train_data로 사용하였다.
3회차는 2회차랑 동일한 데이터에 padding 을 post에서 pre로 변경하였다. RNN에서는 뒤에 padding을 넣는 것 보다 앞쪽에 padding을 넣어주는 쪽이 마지막 결과에 paddind이 미치는 영향이 적어지기 때문에 더 좋은 성능을 낼 수 있다고 알고있기 때문이다.
근데 실제로는 pre padding 쪽이 loss가 더 크게 나왔다. 확인해보니 이론상으로는 pre padding이 성능이 더 좋지만 실제로는 post padding쪽이 성능이 더 잘 나와서 post padding을 많이 쓴다고 한다.
batch_size를 변경해서 pre padding을 한 번 더 돌려보았더니 같은 조건에서의 post padding 보다 loss가 높았고 문장도 부자연스러웠다. 앞으로는 post padding을 사용해야겠다.
int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *(*start_routine)(void*), void *arg)
1. thread : 성공적으로 함수가 호출되면 이곳에 thread ID가 저장됩니다. 이 인자로 넘어온 값을 통해서 pthread_join과 같은 함수를 사용할 수 있습니다.
2. attr : 스레드의 특성을 정의합니다. 기본적으로 NULL을 지정합니다. 만약 스레드의 속성을 지정하려고 한다면 pthread_attr_init등의 함수로 초기화해야합니다.
3. start_routine : 어떤 로직을 할지 함수 포인터를 매개변수로 받습니다.
4. arg : start_routine에 전달될 인자를 말합니다. start_routine에서 이 인자를 변환하여 사용합니다.
pthread_join
int pthread_join(pthread_t thread, void **retval)
1. thread : 우리가 join하려고 하는 thread를 명시해줍니다. pthread_create에서 첫번째 인자가 있었죠? 그 스레드가 join하길 원한다면 이 인자로 넘겨주면 됩니다.
2. retval : pthread_create에서 start_routine이 반환하는 반환값을 여기에 저장합니다.
pthread_detach
때에 따라서는 스레드가 독립적으로 동작하길 원할 수도 있습니다. 단지 pthread_create 후에 pthread_join으로 기다리지 않구요. 나는 기다려주지 않으니 끝나면 알아서 끝내도록 하라는 방식입니다.
독립적인 동작을 하는 대신에 스레드가 끝이나면 반드시 자원을 반환시켜야합니다. pthread_create만으로 스레드를 생성하면 루틴이 끝나서도 자원이 반환되지 않습니다. 그러한 문제점을 해결해주는 함수가 바로 pthread_detach입니다.
int pthread_detach(pthread_t thread)
thread는 우리가 detach 시킬 스레드입니다.
성공시 0을 반환하며 실패시 오류 넘버를 반환하지요.
pthread_detach와 pthread_join을 동시에 사용할 수는 없습니다.
소리는 진동으로 인한 공기의 압축을 이야기하며, 압축이 얼마나됐느냐는 파동(Wave)로 나타낼 수 있다.
소리에서 얻을 수 있는 물리량
진폭(Amplitude) → 강도(Intensity)
주파수(Frequency) →소리의 높낮이(Pitch)
위상(Phase) → 음색
(2) 오디오 데이터의 디지털화
연속적인 아날로그 신호 중 가장 단순한 형태인 sin 함수를 수식으로 표현하면 다음과 같다.
# 아날로그 신호의 Sampling
import numpy as np
import matplotlib.pyplot as plt
def single_tone(frequecy, sampling_rate=16000, duration=1):
t = np.linspace(0, duration, int(sampling_rate))
y = np.sin(2 * np.pi * frequecy * t)
return y
y = single_tone(400)
# 시각화
plt.plot(y[:41])
plt.show()
# 시각화
plt.stem(y[:41])
plt.show()
일반적으로 사용하는 주파수 영역대는 16kHz, 44.1kHz이며, 16kHz는 보통 Speech에서 많이 사용되고, 44.1kHz는 Music에서 많이 사용한다.
나이키스트-섀넌 표본화에 따르면 Sampling rate는 최대 주파수의 2배 이상을 표본화 주파수로 사용해야 aliasing을 방지할 수 있다고 한다.
연속적인 아날로그 신호는 표본화(Sampling), 양자화(Quantizing), 부호화(Encoding)을 거쳐 이진 디지털 신호(Binary Digital Signal)로 변환시켜 인식한다.
(3) Wave Data 분석
Bits per Sample(bps)
샘플 하나마다의 소리의 세기를 몇 비트로 저장했는지 나타내는 단위
값이 커질 수록 세기를 정확하게 저장 가능
16bits의 경우, 2^16인 65,536 단계로 표현 가능
Sampling Frequency
소리로부터 초당 샘플링한 횟수를 의미
샘플링은 나이퀴스트 샘플링 룰에 따라서 복원해야 할 신호 주파수 2배 이상으로 샘플링
가청 주파수 20 ~ 24kHz를 복원하기 위해 사용하며, 음원에서는 44.1kHz를 많이 사용
Channel
각 채널별로 샘플링된 데이터가 따로 저장
2채널은 왼쪽(L)과 오른쪽(R), 1채널은 왼쪽(L) 데이터만 있으며 재생시엔 LR 동시출력
(4) 데이터셋 살펴보기
npz 파일로 이뤄진 데이터이며, 각각 데이터는 "wav_vals", "label_vals"로 저장되어 있다.
# 데이터 불러오기
import numpy as np
import os
data_path = os.getenv("HOME")+'/aiffel/speech_recognition/data/speech_wav_8000.npz'
speech_data = np.load(data_path)
print("Wave data shape : ", speech_data["wav_vals"].shape)
print("Label data shape : ", speech_data["label_vals"].shape)
# 데이터 확인
import IPython.display as ipd
import random
# 데이터 선택
rand = random.randint(0, len(speech_data["wav_vals"]))
print("rand num : ", rand)
sr = 8000 # 1초동안 재생되는 샘플의 갯수
data = speech_data["wav_vals"][rand]
print("Wave data shape : ", data.shape)
print("label : ", speech_data["label_vals"][rand])
ipd.Audio(data, rate=sr)
Train/Test 데이터셋 구성하기
(1) Label Data 처리
# 구분해야 할 Data Label list
target_list = ['yes', 'no', 'up', 'down', 'left', 'right', 'on', 'off', 'stop', 'go']
label_value = target_list
label_value.append('unknown')
label_value.append('silence')
print('LABEL : ', label_value)
new_label_value = dict()
for i, l in enumerate(label_value):
new_label_value[l] = i
label_value = new_label_value
print('Indexed LABEL : ', new_label_value)
# Label Data indexing
temp = []
for v in speech_data["label_vals"]:
temp.append(label_value[v[0]])
label_data = np.array(temp)
label_data
(2) 데이터 분리
# 사이킷런의 split 함수를 이용하여 데이터 분리
from sklearn.model_selection import train_test_split
sr = 8000
train_wav, test_wav, train_label, test_label = train_test_split(speech_data["wav_vals"],
label_data,
test_size=0.1,
shuffle=True)
print(train_wav)
train_wav = train_wav.reshape([-1, sr, 1]) # add channel for CNN
test_wav = test_wav.reshape([-1, sr, 1])
# 데이터셋 확인
print("train data : ", train_wav.shape)
print("train labels : ", train_label.shape)
print("test data : ", test_wav.shape)
print("test labels : ", test_label.shape)
# Hyper-parameter Setting
batch_size = 32
max_epochs = 10
# the save point
checkpoint_dir = os.getenv('HOME')+'/aiffel/speech_recognition/models/wav'
checkpoint_dir
(3) Data Setting
tf.data.Dataset을 이용해서 데이터셋을 구성한다.
tf.data.Dataset.from_tensor_slices 함수에 return 받기 원하는 데이터를 튜플(data, label) 형태로 넣어서 사용할 수 있다.
map함수는 dataset이 데이터를 불러올 때 마다 동작시킬 데이터 전처리 함수를 매핑해준다.
# One-hot Encoding
def one_hot_label(wav, label):
label = tf.one_hot(label, depth=12)
return wav, label
# Dataset 함수 구성
import tensorflow as tf
# for train
train_dataset = tf.data.Dataset.from_tensor_slices((train_wav, train_label))
train_dataset = train_dataset.map(one_hot_label)
train_dataset = train_dataset.repeat().batch(batch_size=batch_size)
print(train_dataset)
# for test
test_dataset = tf.data.Dataset.from_tensor_slices((test_wav, test_label))
test_dataset = test_dataset.map(one_hot_label)
test_dataset = test_dataset.batch(batch_size=batch_size)
print(test_dataset)
Wave classification 모델 구현
(1) 모델 설계
audio는 1차원 데이터이기 때문에 데이터 형식에 맞게 모델을 구성해주어야 한다.
from tensorflow.keras import layers
input_tensor = layers.Input(shape=(sr, 1))
# 규정 상 삭제
output_tensor = layers.Dense(12)(x)
model_wav = tf.keras.Model(input_tensor, output_tensor)
model_wav.summary()
(2) Loss function
정답 label의 class가 12개이기 때문에 해당 class를 구분하기 위해서는 multi-class classification이 필요하며, 이를 수행하기 위한 Loss function으로는 Categorical Cross-Entropy loss function을 사용한다.
input_tensor = layers.Input(shape=(sr, 1))
# 규정 상 삭제
output_tensor = layers.Dense(12)(x)
model_wav_skip = tf.keras.Model(input_tensor, output_tensor)
model_wav_skip.summary()
# Optimization
optimizer=tf.keras.optimizers.Adam(1e-4)
model_wav_skip.compile(loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True),
optimizer=optimizer,
metrics=['accuracy'])
# checkpoint
checkpoint_dir = os.getenv('HOME')+'/aiffel/speech_recognition/models/wav_skip'
cp_callback = tf.keras.callbacks.ModelCheckpoint(checkpoint_dir,
save_weights_only=True,
monitor='val_loss',
mode='auto',
save_best_only=True,
verbose=1)
# 모델 학습
batch_size = 32 # 메모리가 남길래 batch_size 32에서 64로 변경 했었는데 터져서 다시 32로
history_wav_skip = model_wav_skip.fit(train_dataset, epochs=max_epochs,
steps_per_epoch=len(train_wav) // batch_size,
validation_data=test_dataset,
validation_steps=len(test_wav) // batch_size,
callbacks=[cp_callback]
)
# 시각화
import matplotlib.pyplot as plt
acc = history_wav_skip.history['accuracy']
val_acc = history_wav_skip.history['val_accuracy']
loss=history_wav_skip.history['loss']
val_loss=history_wav_skip.history['val_loss']
epochs_range = range(len(acc))
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
# 모델 평가
model_wav_skip.load_weights(checkpoint_dir)
results = model_wav_skip.evaluate(test_dataset)
# loss
print("loss value: {:.3f}".format(results[0]))
# accuracy
print("accuracy value: {:.4f}%".format(results[1]*100))
# 실제 확인 테스트
inv_label_value = {v: k for k, v in label_value.items()}
batch_index = np.random.choice(len(test_wav), size=1, replace=False)
batch_xs = test_wav[batch_index]
batch_ys = test_label[batch_index]
y_pred_ = model_wav_skip(batch_xs, training=False)
print("label : ", str(inv_label_value[batch_ys[0]]))
ipd.Audio(batch_xs.reshape(8000,), rate=8000)
# 예측 결과
if np.argmax(y_pred_) == batch_ys[0]:
print("y_pred: " + str(inv_label_value[np.argmax(y_pred_)]) + '(Correct!)')
else:
print("y_pred: " + str(inv_label_value[np.argmax(y_pred_)]) + '(Incorrect!)')
Spectrogram
waveform은 음성 데이터를 1차원 시계열 데이터로 해석하는 방법이다. 그러나 waveform은 많은 음원의 파형이 합성된 복합파이기 때문에 좀 더 뚜렷하게 다양한 파형들을 주파수 대역별로 나누어 해석할 수 있는 방법이 Spectrogram이다.
(1) 푸리에 변환 (Fourier transform)
푸리에 변환 식은 위와 같다. 그러나 이해하기 어려우니 아래 그림으로 보자.
(2) 오일러 공식
아래 cos과 sin은 주기와 주파수를 가지는 주기함수이다. 즉, 푸리에 변환은 입력 signal에 상관 없이 sin, cos과 같은 주기함수들의 합으로 항상 분해가 가능하다.
푸리에 변환이 끝나면 실수부와 허수부를 가지는 복소수가 얻어진다. 복소수의 절댓값은 Spectrum magnitude(주파수의 강도)라고 부르며, angle은 phase spectrum(주파수의 위상)이라고 부른다.
(3) STFT(Short Time Fourier Transform)
FFT(Fast Fourier Transform)는 시간의 흐름에 따라 신호의 주파수가 변했을 때, 어느 시간대에 주파수가 변하는지 모른다. 따라서 STFT는 시간의 길이를 나눠서 푸리에 변환을 한다.
N은 FFT size이고, Window를 얼마나 많은 주파수 밴드로 나누는 가를 의미한다.
Duration은 sampling rate를 window로 나눈 값이다. duration은 신호주기보다 5배 이상 길게 잡아야 한다. T(window)=5T(signal). ex) 440Hz의 window size = 5(1/440)
$\omega$(n)는 window 함수를 나타낸다. 일반적으로는 hann window 가 많이 쓰인다.
n은 window size다. window 함수에 들어가는 sample의 양으로 n이 작을수록 low-frequency resolution, high-time resolution을 가지게 되고, n이 길어지면 high-frequency, low-time resolution을 가지게 된다.
H는 hop size를 의미한다. window가 겹치는 사이즈이며, 일반적으로 1/4정도를 겹치게 한다.
(4) Spectrogram 이란?
wav 데이터를 해석하는 방법 중 하나로, 일정 시간동안 wav 데이터 안의 다양한 주파수들이 얼마나 포함되어 있는 지를 보여준다. STFT를 이용하여 Spectrogram을 그릴 수 있다.
# 필요한 library import
import numpy as np
import os
import librosa
import librosa.display
import IPython.display as ipd
import matplotlib.pyplot as plt
import random
# data load
data_path = os.getenv("HOME")+'/aiffel/speech_recognition/data/speech_wav_8000.npz'
speech_data = np.load(data_path)
# data list 확인
list(speech_data)
# wav to spectrum function
def wav2spec(wav, fft_size=258): # spectrogram shape을 맞추기위해서 size 변형
D = np.abs(librosa.stft(wav, n_fft=fft_size))
return D
# wav data를 spectrum data로 변환
temp = []
for i in speech_data['wav_vals']:
temp.append(wav2spec(i))
new_speech_data = np.array(temp)
# shape 확인
new_speech_data.shape
# 구분해야 할 Data Label list
target_list = ['yes', 'no', 'up', 'down', 'left', 'right', 'on', 'off', 'stop', 'go']
label_value = target_list
label_value.append('unknown')
label_value.append('silence')
print('LABEL : ', label_value)
new_label_value = dict()
for i, l in enumerate(label_value):
new_label_value[l] = i
label_value = new_label_value
print('Indexed LABEL : ', new_label_value)
# Label Data indexing
temp = []
for v in speech_data["label_vals"]:
temp.append(label_value[v[0]])
label_data = np.array(temp)
label_data
# 사이킷런의 split 함수를 이용하여 데이터 분리
from sklearn.model_selection import train_test_split
sr = 16380
# 메모리 부족으로 커널 자꾸 죽어서 train_size 줄여서 train 진행
train_wav, test_wav, train_label, test_label = train_test_split(new_speech_data,
label_data,
test_size=0.2,
shuffle=True)
print(train_wav)
train_wav = train_wav.reshape([-1, sr, 1]) # add channel for CNN
test_wav = test_wav.reshape([-1, sr, 1])
# 데이터셋 확인
print("train data : ", train_wav.shape)
print("train labels : ", train_label.shape)
print("test data : ", test_wav.shape)
print("test labels : ", test_label.shape)
# Hyper-parameter Setting
batch_size = 32 # 메모리 부족으로 32 이상 불가
max_epochs = 10
# the save point
checkpoint_dir = os.getenv('HOME')+'/aiffel/speech_recognition/models/wav'
checkpoint_dir
# One-hot Encoding
def one_hot_label(wav, label):
label = tf.one_hot(label, depth=12)
return wav, label
# Dataset 함수 구성
import tensorflow as tf
# for train
train_dataset = tf.data.Dataset.from_tensor_slices((train_wav, train_label))
train_dataset = train_dataset.map(one_hot_label)
train_dataset = train_dataset.repeat().batch(batch_size=batch_size)
print(train_dataset)
# for test
test_dataset = tf.data.Dataset.from_tensor_slices((test_wav, test_label))
test_dataset = test_dataset.map(one_hot_label)
test_dataset = test_dataset.batch(batch_size=batch_size)
print(test_dataset)
# 모델 설계
from tensorflow.keras import layers
input_tensor = layers.Input(shape=(sr, 1))
# 규정 상 삭제
output_tensor = layers.Dense(12)(x)
model_wav = tf.keras.Model(input_tensor, output_tensor)
model_wav.summary()
# optimizer 설정
optimizer=tf.keras.optimizers.Adam(1e-4)
model_wav.compile(loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True),
optimizer=optimizer,
metrics=['accuracy'])
# callback 설정
cp_callback = tf.keras.callbacks.ModelCheckpoint(checkpoint_dir,
save_weights_only=True,
monitor='val_loss',
mode='auto',
save_best_only=True,
verbose=1)
# 모델 훈련
history_wav = model_wav.fit(train_dataset, epochs=max_epochs,
steps_per_epoch=len(train_wav) // batch_size,
validation_data=test_dataset,
validation_steps=len(test_wav) // batch_size,
callbacks=[cp_callback]
)
# 훈련 결과 시각화
import matplotlib.pyplot as plt
acc = history_wav.history['accuracy']
val_acc = history_wav.history['val_accuracy']
loss=history_wav.history['loss']
val_loss=history_wav.history['val_loss']
epochs_range = range(len(acc))
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
# checkpoint callback 함수에서 저장한 weight 불러오기
model_wav.load_weights(checkpoint_dir)
# test 데이터와 비교
results = model_wav.evaluate(test_dataset)
# loss
print("loss value: {:.3f}".format(results[0]))
# accuracy
print("accuracy value: {:.4f}%".format(results[1]*100))
# 예측 데이터
inv_label_value = {v: k for k, v in label_value.items()}
batch_index = np.random.choice(len(test_wav), size=1, replace=False)
batch_xs = test_wav[batch_index]
batch_ys = test_label[batch_index]
y_pred_ = model_wav(batch_xs, training=False)
print("label : ", str(inv_label_value[batch_ys[0]]))
ipd.Audio(batch_xs.reshape(16380,), rate=16380)
# 실제 데이터가 맞는지 확인
if np.argmax(y_pred_) == batch_ys[0]:
print("y_pred: " + str(inv_label_value[np.argmax(y_pred_)]) + '(Correct!)')
else:
print("y_pred: " + str(inv_label_value[np.argmax(y_pred_)]) + '(Incorrect!)')
2D Layer 로 변환하여 학습해보기
# 필요한 Library import
import numpy as np
import os
import librosa
import IPython.display as ipd
import random
# data load
data_path = os.getenv("HOME")+'/aiffel/speech_recognition/data/speech_wav_8000.npz'
speech_data = np.load(data_path)
# data list 확인
list(speech_data)
# wav to spectrum function
def wav2spec(wav, fft_size=258): # spectrogram shape을 맞추기위해서 size 변형
D = np.abs(librosa.stft(wav, n_fft=fft_size))
return D
# wav data를 spectrum data로 변환
temp = []
for i in speech_data['wav_vals']:
temp.append(wav2spec(i))
new_speech_data = np.array(temp)
# shape 확인
new_speech_data.shape
# 구분해야 할 Data Label list
target_list = ['yes', 'no', 'up', 'down', 'left', 'right', 'on', 'off', 'stop', 'go']
label_value = target_list
label_value.append('unknown')
label_value.append('silence')
print('LABEL : ', label_value)
new_label_value = dict()
for i, l in enumerate(label_value):
new_label_value[l] = i
label_value = new_label_value
print('Indexed LABEL : ', new_label_value)
# Label Data indexing
temp = []
for v in speech_data["label_vals"]:
temp.append(label_value[v[0]])
label_data = np.array(temp)
label_data
# 사이킷런의 split 함수를 이용하여 데이터 분리
from sklearn.model_selection import train_test_split
train_wav, test_wav, train_label, test_label = train_test_split(new_speech_data,
label_data,
test_size=0.2,
shuffle=True)
print(train_wav)
# 데이터셋 확인
print("train data : ", train_wav.shape)
print("train labels : ", train_label.shape)
print("test data : ", test_wav.shape)
print("test labels : ", test_label.shape)
# Hyper-parameter Setting
batch_size = 32
max_epochs = 10
# the save point
checkpoint_dir = os.getenv('HOME')+'/aiffel/speech_recognition/models/wav'
checkpoint_dir
# One-hot Encoding
def one_hot_label(wav, label):
label = tf.one_hot(label, depth=12)
return wav, label
# Dataset 함수 구성
import tensorflow as tf
# for train
train_dataset = tf.data.Dataset.from_tensor_slices((train_wav, train_label))
train_dataset = train_dataset.map(one_hot_label)
train_dataset = train_dataset.repeat().batch(batch_size=batch_size)
print(train_dataset)
# for test
test_dataset = tf.data.Dataset.from_tensor_slices((test_wav, test_label))
test_dataset = test_dataset.map(one_hot_label)
test_dataset = test_dataset.batch(batch_size=batch_size)
print(test_dataset)
# 모델 설계
from tensorflow.keras import layers
input_tensor = layers.Input(shape=(130, 126, 1))
# 규정 상 삭제
output_tensor = layers.Dense(12)(x)
model_wav = tf.keras.Model(input_tensor, output_tensor)
model_wav.summary()
# optimizer 설정
optimizer=tf.keras.optimizers.Adam(1e-4)
model_wav.compile(loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True),
optimizer=optimizer,
metrics=['accuracy'])
# callback 설정
cp_callback = tf.keras.callbacks.ModelCheckpoint(checkpoint_dir,
save_weights_only=True,
monitor='val_loss',
mode='auto',
save_best_only=True,
verbose=1)
# 모델 훈련
history_wav = model_wav.fit(train_dataset, epochs=max_epochs,
steps_per_epoch=len(train_wav) // batch_size,
validation_data=test_dataset,
validation_steps=len(test_wav) // batch_size,
callbacks=[cp_callback]
)
# 훈련 결과 시각화
acc = history_wav.history['accuracy']
val_acc = history_wav.history['val_accuracy']
loss=history_wav.history['loss']
val_loss=history_wav.history['val_loss']
epochs_range = range(len(acc))
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
# checkpoint callback 함수에서 저장한 weight 불러오기
model_wav.load_weights(checkpoint_dir)
# test 데이터와 비교
results = model_wav.evaluate(test_dataset)
# loss
print("loss value: {:.3f}".format(results[0]))
# accuracy
print("accuracy value: {:.4f}%".format(results[1]*100))
# 예측 데이터
inv_label_value = {v: k for k, v in label_value.items()}
batch_index = np.random.choice(len(test_wav), size=1, replace=False)
batch_xs = test_wav[batch_index]
batch_ys = test_label[batch_index]
y_pred_ = model_wav(batch_xs, training=False)
print("label : ", str(inv_label_value[batch_ys[0]]))
ipd.Audio(batch_xs.reshape(16380,), rate=16380)
# 실제 데이터가 맞는지 확인
if np.argmax(y_pred_) == batch_ys[0]:
print("y_pred: " + str(inv_label_value[np.argmax(y_pred_)]) + '(Correct!)')
else:
print("y_pred: " + str(inv_label_value[np.argmax(y_pred_)]) + '(Incorrect!)')
회고록
예전에 음악에 관심이 많았을 때 더 좋은 음질로 노래를 듣기 위해서 공부했을 때의 지식이 과제를 해결하는데 많은 도움이 된 것 같다.
Wave Classification은 아무래도 데이터가 많아서 그런지 Image Classification이나 NLP보다 훨씬 parameter도 많고 시간도 오래 걸리는 것 같다.
skip-connection 모델을 알고 있다는 전제하의 학습 노드였는데 사실 잘 몰라서 조금 더 찾아봐야 할 것 같다.
skip-connection 을 이용하니까 overfitting은 줄어들은 것 같지만 실제로 정확도에는 큰 차이가 없는 것 같다.
LMS 할 땐 batch_size를 32로 해도 메모리가 남길래 64로 변경해서 진행했었는데, Spectrum으로 변경하니까 parameter 수가 훨씬 많아져서 그런지 batch_size를 32로 조정해도 커널이 자꾸 죽어서 train_size를 줄이는 방향으로 겨우 model을 train시켰다.
Spectrum을 1D-array로 reshape하여 train한 결과는 약 91%의 정확도가 나왔다!
1D-array에 Skip-connect을 적용해봤더니 적용하기 전과 큰 차이는 없는 것 같다.
2D-array로 reshape하여 2D-Conv Layer로 model을 train했더니 무려 96%의 정확도가 나왔다! 확실히 차원이 올라갈 수록 특징을 잡아내는 능력은 향상되는 것 같다. 대신 parameter의 수가 어마어마해져서 1epoch당 거의 5분 이상 걸려서 10epoch을 모두 진행하는 데 거의 1시간 정도가 걸렸다.
1D-array보다 2D-array쪽이 epoch을 거듭할 수록 train_loss와 val_loss의 차이가 벌어지는 정도가 덜했다. Overfitting이 덜하다는 의미인 것 같다. 실제로 결과도 더 좋았다.
2. 식별자 뒤에 숫자가 오면(digit-logs) Input되어있는 순서로 정렬되어야 한다.
3. 그 후, letter-logs 뒤에 digit-logs를 이어준다.
풀이방법
처음에는 위 조건대로 우선 letter-logs랑 digit-logs를 분리한 후, letter-logs를 lambda식을 이용하여 정렬하고, join으로 다시 하나의 문자열로 만들어 준 후에 letter-logs와 digit-logs를 합쳐주었다.
class Solution:
def reorderLogFiles(self, logs: List[str]) -> List[str]:
split_list = []
log_list = []
dig_list = []
ret = []
for str in logs:
s = str.split()
if s[1].isdecimal():
dig_list.append(s)
else:
log_list.append(s)
sorted_log = sorted(log_list, key=lambda x: (x[1:], x[0]))
for s in sorted_log:
ret.append(" ".join(s))
for s in dig_list:
ret.append(" ".join(s))
return ret
다른 풀이방법을 찾아보니 확실히 파이썬 답게 풀었구나 싶었다. split에 maxsplit parameter로 split할 수 있는 범위를 제한할 수 있는 것도 처음 알았고, return에서 조건문을 이렇게도 사용할 수 있구나 싶었다.
이 문제는 m, n이 주어졌을 때, linked list의 m번째 노드부터 n번째 노드까지 역순으로 정렬하는 문제이다.
풀이방법
이번 문제는 주어진 범위의 list만 reverse하는 문제이다. 처음에는 주어진 범위의 list만 reverse하여 m-1 노드의 next를 rev 노드의 head에 연결하고, rev 노드의 tail 의 next를 n+1 노드에 연결하려 했지만 잘 되지 않아서 다른 방법을 찾았다. 이 방법은 이동하면서 start의 next를 end의 next로, end의 next를 end의 next.next로 연결하는 방법이다.
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def reverseBetween(self, head: ListNode, m: int, n: int) -> ListNode:
if not head or m == n:
return head
root = ListNode()
root.next = head
start = root
for _ in range(m - 1):
start = start.next
end = start.next
for _ in range(n - m):
temp = start.next
start.next = end.next
end.next = end.next.next
start.next.next = temp
return root.next
이 문제는 Linked list를 홀수번과 짝수번을 나눠서 정렬시키는 문제이다. 처음에는 노드를 swap해야 하나 싶었는데 다시 생각해보니 홀수, 짝수번째의 Node만 이어서 홀수번째 마지막을 짝수번째 시작 노드에 연결해주면 되는 문제였다.
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def oddEvenList(self, head: ListNode) -> ListNode:
# Linked list가 존재하지 않을 때 예외처리
if not head:
return None
odd = head
even_head = head.next
even = even_head
# even의 next가 없으면 list의 끝
while even and even.next:
odd.next = odd.next.next
odd = odd.next
even.next = even.next.next
even = even.next
# odd의 다음은 even의 시작
odd.next = even_head
return head
이 문제는 linked list의 노드를 두 개씩 짝을 지어 swap한 후 head를 반환하는 문제이다.
풀이방법
swap은 짝수번째 마다 일어난다.
swap 후에는 홀수번째가 되므로 다음 노드로 이동한다.
head, mid, tail로 노드의 조건을 나뉘어서 swap하였다.
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def swapPairs(self, head: ListNode) -> ListNode:
curr = prev = head
while curr and curr.next:
prec = curr.next
# head
if curr == head:
head = curr.next
curr.next = head.next
head.next = curr
# tail
elif not curr.next.next:
prev.next = prec
curr.next = prec.next
prec.next = curr
# mid
else:
prev.next = curr.next
curr.next = prec.next
prec.next = curr
prev = curr
curr = curr.next
return head
다른 풀이를 보니 head 앞에 root 노드를 만들어서 모든 노드에서 동일한 방식으로 swap이 가능하게 푼 방법도 있었다.
알고리즘 문제를 많이 풀어보질 않아서 이런 알고리즘 테크닉들을 익혀두면 알고리즘 문제들을 조금 더 general하게 풀 수 있을 것 같다.
class Solution:
def swapPairs(self, head: ListNode) -> ListNode:
root = prev = ListNode()
prev.next = head
while head and head.next:
b = head.next
head.next = b.next
b.next = head
prev.next = b
prev = head
head = head.next
return root.next